I don’t know what serving stacks kids use these days but judging from my web developer tools, it appears to be a hodgepodge of dynamically loaded crap and microservices (which adds also TLS handshakes to the mix) that of course fetch things in the least efficient ways possible. Caching (a) won’t even work for many of these cases and (b) wouldn’t help much even when it does work.
I’d love to see a post about round trips exclusively and how to reduce it in the bloated stacks of today. I hope it’s not as bad as I think.
Then GraphQL came along to solve the N+1 issue as let you query everything in one network call... but only over HTTP POST so it broke caching on CDNs.
Then edge workers/lambda came to solve that issue. You can also bring your data closer to the edge with replicated databases.
Most newer stacks like Nextjs, Nuxt or SvelteKit behave like a traditional server side rendered page at first and then dynamically load content like an SPA once loaded which is the best of both worlds. They'll also be using HTTP/3 to force-feed a bunch of assets to the client before it even requests them.
Ideally you'd have your data distributed around the world with GraphQL servers close to your users and use SSR to render the initial page markup.
This is not the problem.
The problem that the GP is pointing out is that modern frontends seem to break the data all over the place, and request each piece independently. GraphQL allows solving this problem, but on practice nobody uses it that way because it breaks the abstractions your frontend framework gives you.
Anyway, this entire discussion is on a weird tangent from the article. If you (not the parent, but you reading this) don't cache your static assets forever (with guarantees that this won't break anything), then you should really read the article.
That's why when making request related to realtime data in the server, a POST is always needed! GET is ONLY get for static content.
While POST is effectively never cached, GET isn't always either. Cache headers should be set properly on GET responses, indicating desired caching behavior (which is more than 'on' or 'off', as the OP gets into), on any content, static or not.
The fundamental difference between GET and POST in http is idempotency. An non-cacheable response to an idempotent request is sometimes a (intentional, desirable) thing, which is why you can make GET responses non-cacheable if you want.
Static content isn't the only thing you might want to be cached, there are all sorts of use cases for caching (which again can be configured in many ways, it's not just on or off) for non-static content.
Further, in my experience, intermediate caches are mostly useless for non-binary product data. Either you need to make a round trip or you don’t. Sure, you can cache and return “not changed”, but you still get the latency. Just returning the data often isn’t much slower.
POST avoids all of those issues by pretty much saying “give us what we neeed every time”
I guess the person I was replying to, and you, were talking about Javascript API calls rather than ordinary HTML executed by a "browser". It still seems like a wrong idea to me, but if this is what you do on actual apps and have success, I guess that's a thing.
Don't we call those bugs? http has a pretty well defined spec?
* Support TLS 1.3 + HTTP/2 or HTTP/3.
* Reduce the number of different hosts that you connect to. The optimal number is 1.
That's it.
I would expect that unless you have exceptionally large cookies, the saved roundtrips from another TLS handshake matter more than the data transmission for the cookies.
For assets served from a third party (a CDN), you don't want to send cookies that might include secrets (a session cookie that could allow access to a user's account for example).
You can trust that a third party won't intentionally log or make use of any sensitive information in cookies but you can't guarantee it. Best not to send it at all.
But the motivation to put stuff on a CDN would be to improve performance. If you put your HTML on your own HW and your assets on a CDN for performance reasons, you might want to check if that really pans out, because those extra roundtrips may kill all performance savings you get from the CDN.
Won't that naturally be on a different domain anyway?
How much performance hit do cookies really have in 2023?
Generally speaking, I’ve found it’s better to remove this from the build logic and treat it as an infra / deployment issue. Dump all of your static assets into your object store using the Git hash of the current version as a prefix. So if you are deploying foo.js, then you might serve it as https://static.example.com/<git hash>/foo.js.
This means that you can set all of your assets as permanently cacheable and still have your cache invalidated for everything every time you deploy something new. And it doesn’t matter what you use to build your assets; your build pipeline doesn’t need to know anything about this, it can just generate assets normally.
This way, a new deployment of your application doesn’t cause new assets to be served to users, and maintains the speed of your website.
You’re talking about this in terms of chunks of JavaScript, but static asset caching is something you should be doing for all static assets, not just JavaScript. Whenever I’ve seen somebody use Webpack content hashing for this, they’ve done it for JavaScript and CSS and forgot about basically every other type of file. And also, now you are tied to only referencing those assets via JavaScript because you have to get the URLs from Webpack, whereas with a URL prefix you can just use relative URLs which work in other contexts as well.
To fingerprint files you normally wouldn't import in JS, you can 1) import them in JS anyway just for the bundling side effect or 2) use a Webpack copy plugin to copy all font files, for example, to the build directory and fingerprint them.
I fail to understand how resolving that is simpler.
- /js/foo.js
- /css/bar.css
- /img/baz.png
- /js/foo.abc123.js
- /css/bar.def456.css
- /img/baz.ghi789.png
With a Git hash prefix, you would have something like:
- /abcdef/js/foo.js
- /abcdef/css/bar.css
- /abcdef/img/baz.png
Your build process and your infrastructure caching are two separate concerns; it’s easier if they aren’t tightly coupled.
I also don't want to jump to conclusions, maybe the author really does like PicPerf (and just so happened to include a referral tag lol), but I think most people here are very sensitive to content marketing.
I'm trying to apply for a visa, and it's almost impossible to find official government documents or 1st hand experiences buried underneath all the shitty content marketing from law firms.
Worse: The author of the post is the creator of PicPerf
[1] https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/ET...
This gets much worse if you do any sort of lazy loading such as images that get loaded as the user scrolls or client-side routing which loads the next page dynamically using a hashed script file.
I wrote a blog post about these problems a while ago: https://kevincox.ca/2021/08/24/atomic-deploys/
You can cache a lot more than you think if you mastermind your strategy.
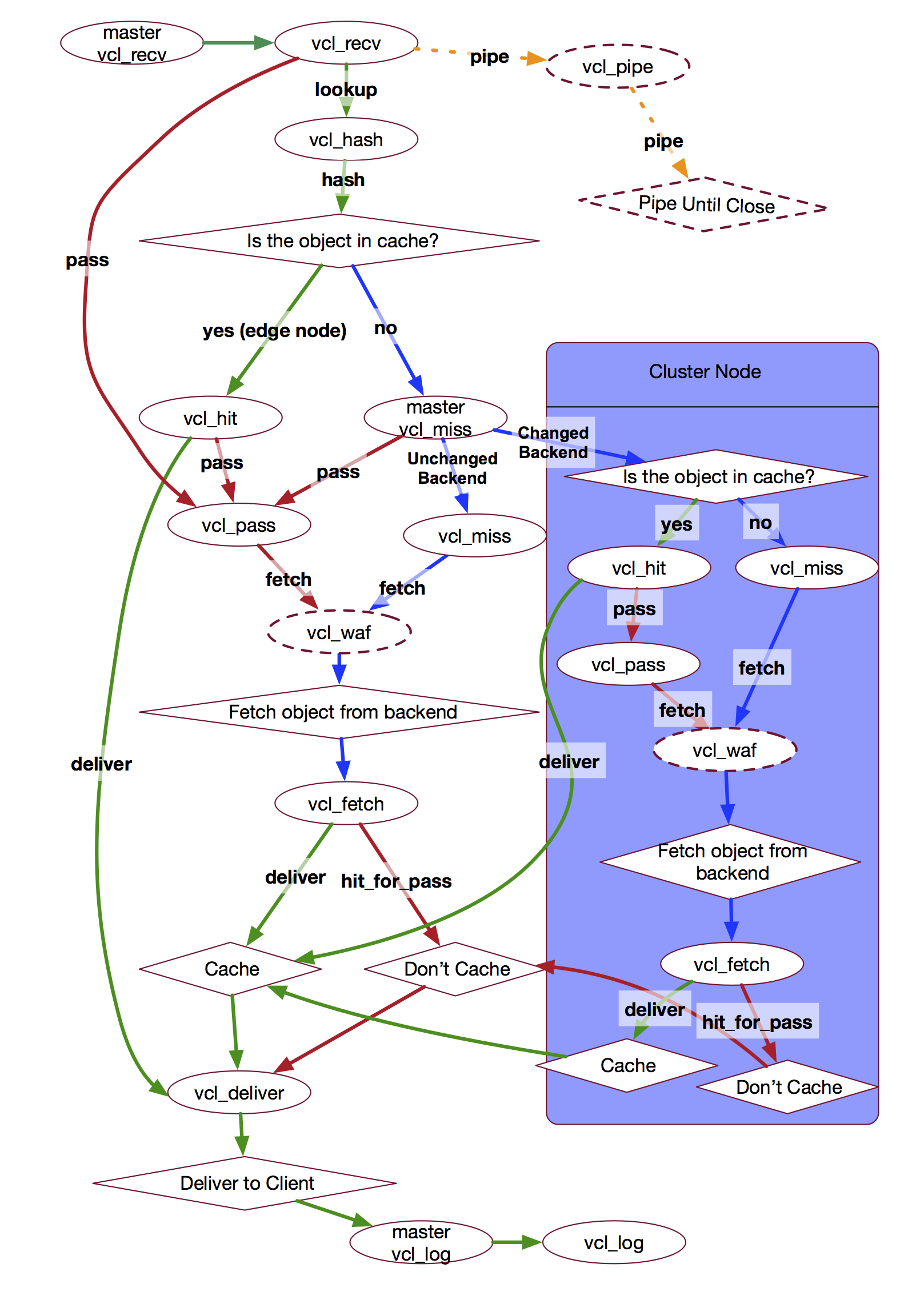
A diagram of fastly/varnish state -> https://www.integralist.co.uk/images/fastly-request-flow.png
[1] https://www.varnish-software.com/developers/tutorials/http-c...
[2] https://info.varnish-software.com/blog/request-coalescing-an...
[3] https://docs.varnish-software.com/tutorials/object-lifetime/
[4] https://www.varnish-software.com/developers/tutorials/varnis...
Unless you are actually serving different versions based on this key you can run into issues here. If the user loads version 1 of the page but some point later tries to request /script.js?v=1 but you have deployed version 2 in the meantime they will get the new version which may not be compatible. (also note that every time they request a script it will be "some point later" compared to the HTML file)
This is becoming more of an issue with lazy-loading single-page applications where they will load the script next routes as you click on them. This means that it may be many minutes between the original page load and the load of the next script.
Of course maybe that is better than a 404 like most of these providers provide with a different file name, but the 404 may be easier to catch and handle with a true reload.
If you want to serve multiple versions of a static asset at the same time just use different file names.
Edit: That's why SPA frameworks usually use the hash inside the file name approach, so you can keep serving the previous script files for users that didn't reload the application yet.
What we usually do for infrequently updated enterprise applications: we terminate all active sessions during an update and users are forced to do a silent SSO re-login and re-load the SPA. This also allows us to deploy non-backwards compatible API changes without running into problems. This strategy may not fit everywhere though.
Browsers have a cache API that can be used directly or in service/webworkers.
A managed cache comes with significant upsides, such as complete control, but costs design/developer time and comes with a risk:
Caching done wrong can lead to bugs that are very hard to reason about and fix. Especially when service workers are involved.
Whenever we update something, whether an image, js, or css, we increment the number. Most of it is automated since we have millions of images.
Doesn't this creates a security issue with ext content?
Shouldn't this easy to Selfhost through some nginx config?
Like nginx do a proxy pass upstream and cache and return a cache header? The only thing you need to do is either use a specific path or do the same as this service does with a URL at the end.
Of course denying random hosts l.
Should be doable in a few minutes
{kind=link}