Labeled data is the bottleneck, so my work focuses on getting good results with less data. Key parts:
- Created EDANSA [1], the first public dataset of its kind from these areas, using a improved active learning method (ensemble disagreement) to efficiently find rare sounds.
- Explored other low-resource ML: transfer learning, data valuation (using Shapley values), cross-modal learning (using satellite weather data to train audio models), and testing the reasoning abilities of MLLMs on audio (spoiler: they struggle!).
Happy to discuss any part!
Just wondering if the raw data that you've mentioned are available publicly so we can test our techniques on them or they're only available through research collaborations. Either way very much interested on the potential use of our techniques for the polar research in Arctic and/or Antarctica.
That actually reminds me, at one point, a researcher suggested looking into geophone or fiber optic Distributed Acoustic Sensing (DAS) data that oil companies sometimes collect in Alaska, potentially for tracking animal movements or impacts, but I never got the chance to follow up. Connecting seismic activity data (like yours) with potential effects on animal vocalizations or behaviour observed in acoustic recordings would be an interesting research direction!
Regarding data access:
Our labeled dataset (EDANSA, focused on specific sound events) is public here: https://zenodo.org/records/6824272. We will be releasing an updated version with more samples soon.
We are also actively working on releasing the raw, continuous audio recordings. These will eventually be published via the Arctic Data Center (arcticdata.io). If you'd like, feel free to send me an email (address should be in my profile), and I can ping you when that happens.
Separately, we have an open-source model (with updates coming) trained on EDANSA for predicting various animal sounds and human-generated noise. Let me know if you'd ever be interested in discussing whether running that model on other types of non-stationary sound data you might have access to could be useful or yield interesting comparisons.
The main hurdle we've hit is honestly the scale of relevant data needed to train such large models from scratch effectively. While our ~19.5 years dataset duration is massive for ecoacoustics, a significant portion of it is silence or ambient noise. This means the actual volume of distinct events or complex acoustic scenes is much lower compared to the densely packed information in the corpora typically used to train foundational speech or general audio models, making our effective dataset size smaller in that context.
We also tried leveraging existing pre-trained SSL models (like Wav2Vec 2.0, HuBERT for speech), but the domain gap is substantial. As you can imagine, raw ecoacoustic field recordings are characterized by significant non-stationary noise, overlapping sounds, sparse events we care about mixed with lots of quiet/noise, huge diversity, and variations from mics/weather.
This messes with the SSL pre-training tasks themselves. Predicting masked audio doesn't work as well when the surrounding context is just noise, and the data augmentations used in contrastive learning can sometimes accidentally remove the unique signatures of the animal calls we're trying to learn.
It's definitely an ongoing challenge in the field! People are trying different things, like initializing audio transformers with weights pre-trained on image models (ViT adapted for spectrograms) to give them a head start. Finding the best way forward for large models in these specialized, data-constrained domains is still key. Thanks again for the suggestion, it really hits on a core challenge!
but as you mention, labeled data is the bottleneck. eventually I'll be able to skirt around this by just capturing more video data myself and learning sound features from the video component, but I have a hard time imagining how I can get the global coverage that I have in visual datasets. I would give anything to trade half of my labeled image data for labeled audio data!
On the labeled audio data front: our Arctic dataset (EDANSA, linked in my original post) is open source. We've actually updated it with more samples since the initial release, and getting the new version out is on my to-do list.
Polli.ai looks fantastic! It's genuinely exciting to see more people tackling the ecological monitoring challenge with hardware/software solutions. While I know the startup path in this space can be tough financially, the work is incredibly important for understanding and protecting biodiversity. Keep up the great work!
Enhancing frequenSee for scientific use (labelling/analysis) sounds like a good idea. But I am not sure what is missing from the current tooling. What functionalities were you thinking of adding?
We are also actively working on releasing the raw, continuous audio recordings. These will eventually be published via the Arctic Data Center (arcticdata.io). If you'd like, feel free to send me an email (address should be in my profile), and I can ping you when that happens.
What's the licensing is it public domain
Would love to hear any feedback the HN crowd has. I'm aware of a couple of alignment issues, will fix them up tonight. Also, yes, there will be a "generate PDF" button, for now if you want a pdf I'd suggest using the Print dialog to "Save as PDF".
Also it’s open-source https://github.com/VladSez/easy-invoice-pdf
Would love to receive any feedback as well :)
Anything else can be corrected. It is important to easily make corrections and/or credit nota as those seem to happen at the worse time. Usually the same as the invoice but with amounts in the -
It is also nice to tie the products into it so that you don't have to type it every time and get consistent naming. Same for an address book.
https://ec.europa.eu/digital-building-blocks/sites/display/D...
I don't know how complicated or easy it would be to just create templates which satisfy this.
In Germany it's already required for B2B transactions [0]
In principle, the following formats will comply with CEN 16931:
ZUGFeRD: Hybrid format: Human-readable PDF/A-3 with an embedded XML file in the syntax "Cross-Industry Invoice" (CII)
XRechnung: XML file in the syntax "Cross-Industry Invoice" (CII)
XRechnung: XML file in the "Universal Business Language" (UBL) syntax
Also back when I had to do these (I used Wave) having a notes section was very useful to include a few things (i.e. I used to include conversion rates). Would probably be pretty easy.
I tried implementing my own on my own website, but between all my projects and work I keep pushing my own business website backward...
Overall it’s pretty good solution for occasional invoice generators.
At some point I'd like to add shortlinks but at the moment everything is clientside, there's no persistence at all (beyond localStorage). I think that's a nice feature from a security perspective.
The app might be stateless right now (I haven't checked); if it is, adding a URL shortener will break that.
First major disconnect is that not every country uses invoices, but may use receipts instead. This is true for the USA for example, so many US devs (for example: Stripe in the early days) are not familiar with the concept of invoicing. Technically there is no difference between receipts and invoices, so if you're not familiar with the concept of invoicing, just read this post with /s/invoice/receipt in mind.
The point about invoicing is to act as a non-mutable entry into the ledgers of both parties (seller and buyer). In most countries (especially EU) invoices are mandated by law for B2B transactions, and so is keeping accounts (aka bookkeeping). So for invoicing to be practical it needs to be tied to your books/accounts. Because of this, any business will use some bookkeeping/accounting software, which will have invoicing capabilities built-in. Invoicing as a standalone product doesn't make sense if you have to import it all into your ledgers later.
Then there is the 'design' trap, which many invoicing startups seem to fall for. Invoices are weird things. They are basically very, very inefficient artefacts from the past. An invoice is just a very little amount of transaction data exchanged between buyer and seller. In the days of physical bookkeeping (actual paper books) paper invoices made sense, but nowadays it is all done digitally. So the invoice is effectively a machine-2-machine interface, but for all sorts of legacy reasons we still wrap them in PDF with a fancy design that looks great for humans, but it effectively impossible for machines to read.
There are all sorts of attempts made to improve upon this situation (like OCR, and nowadays AI to extract data from PDF invoices). There are open structured data formats such as UBL to replace / augment PDF invoices, but due to all sorts of politics and lobbying the open standards have been doomed from the beginning. There is a lot of money made in accounting software, and they all rely on vendor lock-in. The major accounting software vendors have very strong incentives to keep us from adopting UBL et al, and most of the established accounting product suck, but you can't easily migrate so you'll be stuck with it.
If you run or own a business, treat your books as an asset of your business, a very important asset for that matter. Books are kept in accounting software, which is typically part of a larger software suite which also features tax filing, HRM, asset management, invoicing, etc. In fancy business terms this is often called ERP. But think of ERP as just your central database, or your 'books'.
Choosing your accounting software an important decision. Choose accounting software that allows exporting your data (very important!), that has an API (also very important), and preferably a web interface. It should be always available, so on-premise software is out. For entrepreneurs: choose your own accounting software, do not be tempted to hire an external bookkeeper that keeps the books in 'their' systems (accountant lock-in). Don't let an accountant recommend your software either, they get huge kickbacks from the software vendors (vendor lock-in). Every sale—whether this being PoS, invoicing, or a payment integration like Stripe—should automatically registered as a ledger entry in the books, preferably with an invoice document attached. Here you can see why an accountant who keeps your books in their systems won't work, you don't want to be stuck having to periodically send an email (or shoebox) filled with invoices for them to process. Your books should be owned by the business, should be automated (at least for the receivable side), and always be up-to-date. You can then give an(y) accountant access to your books for them to do audits, tax filings, etc. For a business, the books are the central database of the business, everything else revolves around it. Do not be tempted to write your own, instead integrate with existing solutions while avoiding vendor lock-in as much as possible.
Integrating your business with the accounting software is an ever-ongoing part of your software development efforts, so not underestimate it. Accepting payments is hard, making sure it is well registered in your books is equally hard. It takes _much_ more time than you'd think (most first-time entrepreneurs actually don't consider it at all). There are no silver bullets here.
Every invoice—whether B2B or even B2C (receipts included)—must be sent electronically using a government-defined XML format. This invoice includes predefined metadata and is digitally signed by the issuing party. Once ready, it gets submitted to the national tax agency’s centralized system, called the Sistema di Interscambio (SdI), which validates and registers it before forwarding it to the recipient.
This system essentially acts as a clearinghouse: it ensures all invoices go through the same format, are verifiably issued, and are automatically recorded on both ends. For consumers (B2C), the invoice still goes through the same pipeline and is made available in their personal portal on the IRS website, while the seller can still email a copy (PDF) for convenience.
This centralized and machine-readable approach has eliminated a lot of the fragmentation seen elsewhere. There’s no vendor lock-in, no OCR, and no AI needed to parse PDFs—just a signed XML file going through a common pipeline. It’s not perfect, but it shows how much smoother things can be when the rules (and formats) are defined at the infrastructure level.
So not a universal standard then. Imagine having to implement a different format for every country you do business with...
For the Netherlands there is a similar (but slightly different I believe) XML type format required if you want to do business with the government. Initially a company successfully lobbied to get their closed-specification version to be the mandated standard for government, to get the XML spec you had to become partner (I believe for €8k/year or something).
Luckily they are now performing a XKCD 927 and have defined a few new (this time open) standards, which they aim to consolidate into a new spec that complies to EN 16931. EN 16931 is the EU compliance standard for e-invoicing.
There’s plenty of need for basic use invoicing like this. Generate an invoice as a way to bill someone or serve as an estimate for work/project cost. Not everyone is at a place where it needs to be so formal and integrated into a complete solution that tracks the dollars from invoice to balance sheet to income statement, etc. It’s a lot especially for people that are just freelancing and need a similar probably infrequent way to send a bill. They probably are just tracking things in a spreadsheet and not even big enough to use quickbooks or anything else. It would be a poor use of time and over engineering to put that all in place and setup things that cost subscription dollars in perpetuity just to bill for a one off charge. Or even a handful of them.
When I think of people I pay, my lawn guy and my housekeeper both just text me how much I owe them. Then I zelle them. They both have dozens of clients at least and I imagine they are doing this way for them all. If I were a business, in May insist on getting an invoice to load the AP into an accounting flow from my end but they wouldn’t really want to change their system of doing things just to comply with my request. So, they may want something like this that just basically converts the text message info into an official looking invoice.
I feel the real problem is everyone is assuming this side project type thing to solve every edge case that exists in the world. Even the bigger guys like stripe. That’s the wrong take. They offer a solution, you have to evaluate of it fits your needs, if not, use something else. If you’re in a locale that mandates something completely different, use something else. This project is being very transparent about what it does and how it works, which should help you out if you have a requirements list to compare it to.
I find this hard to believe. An invoice is a request for payment. A receipt is proof/confirmation of payment. Invoices sometimes double as receipts (or rather the other way around) when the payment is made immediately. But how can a country not have something that represents a formal request for payment by some future time?
I don't even understand this from an accounting perspective. What would accounts receivable and accounts payable even mean without this distinction? How would you date the respective journal entries if there is no distinction?
There are plenty countries where the vendor will charge the account of the customer, like a 'pull' mechanism. In many countries they'll use (or used) checks/cheques for that, or a different payment account like a credit card. The agreement for this would have been a contract. They may still use invoices for larger transactions, but they aren't always required by law.
I remember that in the old days, Google, Stripe, etc wouldn't send invoices, sometimes you'd get a minimal receipt message by email, but that was about it. This was particularly annoying for EU-based companies where there are minimal requirements for invoices and/or receipts.
Times have changed though. Most companies, including US-based, will now offer invoices that comply with most international regulations.
Except PayPal of course, for some reason they still seem to get away with not offering invoices. You'll have to download your monthly account overview in PDF from their merchant portal, and they just slapped the following text on it: "This statement may serve as a receipt for accounting and tax related purposes.".
~30 years ago I worked at a very small business (3 employees) and they used and liked Quickbooks. The accountant convinced them to switch to some "better" system and for around 3 months they had no idea how much money they had, they just lost all visibility into the system because it didn't work in the way they expected. "If things didn't look right, we'd just go through every screen in the system and press Post." At the end of those 3 months they realized they had unexpectedly gotten into $70K in debt -- this was ~35 years ago when a house was around that much. They had to take a second mortgage on their house. Eventually, they figured out the accounting system, righted the ship, and paid back the second mortgage over a few years. Y2K really helped, with that giant bump in sales.
I am just starting my journey into entrepreneurship, and have yet to choose a bank or accounting software, and would appreciate guidance. I am based in the UK, and will only be conducting business in the UK to start off with.
As far as integrations, GNU cash lets you import from various formats like quicken while beancount has lots of plugins from the community like importers for various banks. I don’t believe either offer invoicing but you could integrate it yourself or just manually record.
IMO, the hardest part of keeping your own books is learning double entry accounting.
Love that it dumps you right into the experience.
pure.md acts as a global caching layer between LLMs and web content. I like to think of it like a CDN for LLMs, similar to how Cloudinary is a CDN for images.
[1] https://pure.md
At: https://willadams.gitbook.io/design-into-3d/2d-drawing the links for:
https://mathcs.clarku.edu/~djoyce/java/elements/elements.htm...
https://mathcs.clarku.edu/~djoyce/java/elements/bookI/bookI....
https://mathcs.clarku.edu/~djoyce/java/elements/bookI/defI1....
are rendered as:
_Elements_ _:_ _Book I_ _:_ _Definition 1_
Maybe detect when a page is on gitbook or some other site where there is .md source on github or some other site and grab the original instead?
Recently discussed, too: https://news.ycombinator.com/item?id=43462894 (10 comments)
I wanted to understand how models learn, like literally bridging the gap between mathematical formulas and high-level API calls. I feel like, as a beginner in machine learning, it's important to strip away the abstractions and understand how these libraries work from the ground up before leveraging these "high-level" libraries such as PyTorch and Tensorflow. Oh I also wrote a blog post [5] on the journey.
[1] https://github.com/workofart/ml-by-hand
[2] https://github.com/karpathy/micrograd
[3] https://github.com/workofart/ml-by-hand/blob/main/examples/c...
[4] https://github.com/workofart/ml-by-hand/blob/main/examples/g...
I love card games, but for digital card games the business model is beyond predatory. If you need a specific card your option is to basically buy a pack. Let’s say this is about 3$ give or take. But if it’s a specific rare card, you can open a dozen of so packs and still not get the specific card you want.
This can go on indefinitely, and apologists will claim you can just work around this, by building a different deck. But the business model clearly wants you to drop 50 to 100$ just to get a single card.
All for this to repeat every 3 months when they introduce new mechanics to nerf the old cards or just rotate out the dream deck you spent 100$+ to build.
I’m under no impression I’ll directly compete, but it’s a fun FOSS game you can spin up with friends. Or even since it’s all MIT, you can fork and sell.
It also gives me an excuse to use Python, looks like Django on the backend and Godot for the game client. Although the actual logic runs in Django so you can always roll a different game client.
Eventually I’d like different devs to roll their own game clients in whatever framework they want.
Want to play from the CLI, sure
[0]: https://boardgamegeek.com/boardgame/345584/mindbug-first-con...
I would love to compare game development notes if you're interested in discussing this sometime.
So far it's basically just a Django server. You're responsible for self hosting ( although I imagine I'll put up a demo server), you can define your own cards.
You can play the game by literally just using curl calls if you want to be hardcore about it.
I *might* make a nice closed source game client one day with a bunch of cool effects, but that's not my focus right now.
I think virtual tabletops (VTTs) as they currently stand are barking up the wrong tree[2]. I want a computer-augmented RPG to allow the GM to do everything he does in the analog form of the game. On-the-fly addition of content to the game world, defining of new kinds of content, defining and editing rules, and many other things ... as well as the stuff VTTs do, of course. The closest we've gotten in the last 30 years is LambdaMOO and other MUDs.
The app I made for my thesis project was an experimental vertical slice of the kinds of functionality I want. The app I made after that last year is more practical and focused on the needs of my weekly game, in my custom system; I continue to develop it almost daily.
I'm itching to tackle the hardest problem of all, which is fully incorporating game rules in a not-totally-hardcoded way. I need rules to be first-class objects that can be programmatically reasoned about to do cool things like "use the Common Lisp condition system to present end user GMs with strategies for recovering from buggy rules." Inspirations include the Inform 7 rulebook system.
[1] See my homepage, under Greatest Hits: https://www.mxjn.me
[2] Anything that requires physical equipment other than dice and a regular computer is also barking up the wrong tree. So no VR, no video-tracked physical miniatures, no custom-designed tabletop, no Microsoft Surface... Again, just my opinion.
Is your project available anywhere? Best of luck!
If you're interested, because I kept seeing "LLM as GM" projects, I got curious about how well it would work to have LLMs as players instead. So I made this:
https://github.com/maxwelljoslyn/gm-trainer
It's a training ground for GMs to practice things like spontaneous description, with 4 AI players that get fed what each other say so they act in a reasonably consistent manner. It's not perfect, but I've gotten some good use out of it.
For instance, my game rules include an economic subsystem, which takes in the production of goods and services at hundreds of in-game cities, and computes prices for over a thousand player-purchaseable goods. The "second app" that I referred to above allows players to (among many other things) purchase stuff at the market nearest their current location and have those items go straight into their character sheet. If the "item" is actually an animal, a hired mercenary, etc. then a different subsystem generates a new NPC with the right statistics and attaches the player to it as owner/liege.
I could write an extension for a VTT that talks to my economic system over an API, and throws items up on screen, lets players purchase them, moves them into their character sheet using the right function calls in the VTT's extension library, etc. But every step of the way, I would be fighting to cram this subsystem into the VTT's conception that gameplay begins and ends with maps and char sheets.
It's been a fun project. Dealing with the scale of Reddit (~300 posts/second) creates some interesting technical challenges. It's also let me polish up my frontend development skills.
I don't think it will ever be a money spinner - it has ~70 folks using it buy they're all on the free tier. It's felt really good to build something useful, though.
[1]: https://mentions.us
That being said, here is an additional feature: being able to track discord/slack/telegram by providing my API key and you streaming the content of the groups I've signed up to.
Interesting feature request! I’ll have a think on it.
If your company just wants alerts when their keywords are mentioned on social media then mentions.us should work great for them. If you work for Coca Cola then you likely need something very different from your social listening tool!
For LinkedIn monitoring we use the voyager APIs. It’s not perfect because it gets posts but not comments, but it’s pretty good.
I’m not optimising to extract every possible $ from the market with that pricing strategy. Instead I hope it will maximise the number of users whilst breaking even on costs.
What would your customers need to make them want to pay for it ?
I do have a paid plan for people who want Slack notifications, and I think those folks ought to be happy to pay. My hope is that I'll eventually get a few paid signups and that those will cover the costs of the service (which are minimal).
I know I lose a bit of revenue with the above approach, but it's a tradeoff I'm happy to make.
I built a no-AI, human-only social network focused on ONLY one thing - keeping people connected.
I'd stepped away from mainstream social media last year due to the overwhelming negativity, privacy violation, etc. Then around early this year, I started to feel I was missing updates from people who actually matter in my life. Instead of going back to traditional platforms, I decided to create a simple solution myself.
The platform emphasizes: - No AI algorithms or content manipulation - No infinite scrolling designed to trap your attention - A simple interface for sharing life updates with close connections (Text and Photos only for now)
We've intentionally made connecting difficult: no user search and no friend suggestions - you only connect with people you already know and care about.
Web: https://aponlink.com/ Android App: https://play.google.com/store/apps/details?id=com.aponlink.a... (iOS version coming soon)
I'd love to hear how this approach resonates with the HN community, particularly from those who've also grown tired of traditional social media.
> no user search and no friend suggestions
I get the intentionality, but the reason that facebook was successful was that it found the people you intentionally wanted to communicate with for you.
The issue is that the social graph overstays its welcome. After its done finding all the people you want to communicate with, it suggests a ton of people you dont.
I actually find this to be similar to netflix and spotify suggestions, both of which were able to find things I wanted to consume early on, but now just give me waves of shit.
Consider doing something a lot smaller, like an opt in, 1 month activation at a time, depth 1 search to find people you might want to connect with, but without the hassle of having to swap details on another platform.
The challenge is figuring out how to offer just enough discoverability that doesn't creep users. I like your idea of an opt-in, time-limited, depth-1 search, it keeps things intentional while reducing friction. Definitely something to think about.
Curious: would you see value in a simple "import contacts" option, or do you think that would risk overstepping?
It would be useful to identify my friends but I dont want a loose thread of some guy I emailed 20 years ago to constantly bug me.
---
The links on the bottom of the page (about, privacy policy, ect) don't work.
In general: Non-functioning links / buttons are a huge no-no. When I encounter non-functioning links / buttons in software, I just assume I'm going to waste my time and move on.
I know that sometimes when designing a UI, you want to be able to "see" what the final product will look like. Leaving them in before they work is sloppy, and gives the impression that your product also has more loose ends.
1. The bottom nav links are fixed now, really appreciate you pointing that out.
2. > ...an About page with screenshots great suggestion! We’ll work on adding that soon to better showcase what Aponlink is about.
How do you envision onboarding? Do I join, and then try to convince a handful of people to join as well?
> How do you envision onboarding? Do I join, and then try to convince a handful of people to join as well?
Yes, that's been the idea so far for onboarding. But we’re also exploring ways to make the platform more organically discoverable and valuable from day one (without AI).
In my case, it's been easy to convince my network to move and I found they shared a similar level of dismay towards traditional networks.
Please let me know if you have any suggestions on the onboarding process
The need is there (at least for some of us!) so the sell shouldn't be so hard, but I feel like I'm missing the "a-ha!" differentiator here. It's not enough to pull the good/useful remnants from the sludge socials are today; it would need an extra something to excite people enough to make the effort to engage with yet another online service.
Error Firebase: Error (auth/network-request-failed).
I’ll also check on my end to make sure everything is running smoothly. Appreciate the heads-up!
You can read an intro here: https://blog.tangled.sh/intro (it’s publicly available now, not invite-only).
In short, at the core of Tangled is what we call “knots”; they’re lightweight, headless servers that serve up your git repository, and the contents viewed and collaborated upon via the “app view” at tangled.sh. All social data (issues, comments, PRs, other repo metadata) is stored “on-proto”—in your AT Protocol PDS.
We don’t just plan to reimplement GitHub, but rethink and improve on the status quo. For instance, we plan to make stacked PRs and stacked diff-based reviews first-class citizens of the platform.
Right now, our pull request feature is rather simplistic but very useful still: you paste your git diff output, and “resubmit” for a new round of review (if necessary). You can see an example here: https://tangled.sh/@tangled.sh/core/pulls/14
We’re fully open source: https://tangled.sh/@tangled.sh/core and are actively building. Come check it out!
On YouTube: https://youtube.com/@foxev-content
In a learning app: https://foxev.io/academy/
On a physical board where people can explore electric car tech on their desk: https://foxev.io/ev-mastermind-kit/
Backstory: from 2018-2023 I converted London taxis to be electric and built three prototypes. We also raised £300k and were featured in The Guardian. I have a day-job again these days and am persisting what I learnt and sharing it. YouTube is super interesting for me because of the writing, similar for the web app actually because the code isn't that complicated, it's about how do I present it in a way that engaged users, so I am thinking mostly about UX.
Actually why not, here is the intro to the first module (100 questions about batteries - ends in a 404): https://foxev.io/academy/modules/1/
You can sign up interest and I will send you an email when it's ready.
For my day job I am currently working for an online education company. I have been learning about the concepts behind knowledge tracing and using knowledge components to get a fine grained perspective on what types of skills someone has acquired throughout their learning path. It is hard because our company hasn't really had any sort of basis to start from, so I have been reading a lot of research papers and trying to understand, from sort of first principles, how to approach this problem. It has been a fun challenge.
So the idea of Knowledge Tracing originated, from my understanding with a paper in 1994: http://act-r.psy.cmu.edu/wordpress/wp-content/uploads/2012/1... this sort of introduced the idea that you could model and understand a students learning as it progresses through a set of materials.
The concept of Knowledge Components was started, I believe, at Carnegie Mellon and University of Pittsburgh with the Learn Lab: https://learnlab.org/learnlab-research/ - in 2012 they authored a paper defining KLI (Knowledge Learning Instruction framework): https://pact.cs.cmu.edu/pubs/KLI-KoedingerCorbettPerfetti201... which provided the groundwork for the concept of Knowledge Components.
This sort of kicked things off with regards to really studying these things on a finer-grained level. They have a Wiki which covers some key concepts: https://learnlab.org/wiki/index.php?title=Main_Page like the Knowledge Component: https://learnlab.org/wiki/index.php?title=Knowledge_componen...
Going forward a few years you have a Stanford paper, Deep Knowledge Tracing (DKT): https://stanford.edu/~cpiech/bio/papers/deepKnowledgeTracing... which delves into utilizing RNN(recurrent neural networks) to aide in the task of modelling student knowledge over time.
Jumping really far forward to 2024 we have another paper from Carnegie Mellon & University of Pittsburgh: Automated Generation and Tagging of Knowledge Components from Multiple-Choice Questions: https://arxiv.org/pdf/2405.20526 and A very similar paper that I really enjoyed from Switzerland: Using Large Multimodal Models to Extract Knowledge Components for Knowledge Tracing from Multimedia Question Information https://arxiv.org/pdf/2409.20167
Overall the concept I've been sort of gathering is that, if you can break down the skills involved in smaller and smaller tasks, you can make much more intelligent decisions about what is best for the student.
The other thing I've been gathering is that Skills Taxonomies are only useful in as much as they help you make decisions about students. If you build a very rigid Taxonomy that is unable to accommodate change, you can't really adapt easily to new course material or to make dynamic decisions about students. So the idea of a rigid Taxonomy is quickly becoming outdated. Large language models are being used to generate fine-grained skills (Knowledge Components) from existing course material to help model a students development based on performance in a way that can be easily updated when materials change.
I have worked through and replicated some of the findings in these later papers using local models, for example using the open Gemma 2 27b models from Google to generate Knowledge components and using Sentence Embedding models and K-means clustering to gather them together and create groups of related Knowledge Components. It's been a really fun project and I've been learning quite a bit.
It's nice to know I'm not the only one thinking about that.
The trick for me is that it's a path in a graph for each student, so even if some component is not as strong for one student, he can fill the gap by taking another route. A good framework would be resilient if it finds many possible paths to reach the same result, and not forcing one path. But then, teaching in this way is more difficult.
[Edit]: I wrote a re-introduction to Runno: The WebComponent for Code over the weekend (https://runno.dev/articles/web-component/)
I've been playing around with turning it into a sandbox for running code in Python (https://runno.dev/articles/sandbox-python/). This would allow you to safely execute AI generated code.
Generally thinking about more ways to run code in sandbox environments, as I think this will become more important as we are generating a lot of "untrusted" code using Gen AI.
1. https://pyodide.org/en/stable/ 2. https://ai.pydantic.dev/mcp/run-python/
A big difference between my approach and their approach is that Runno is generic across programming languages. Pyodide only works for Python (and can only work for Python).
Big interesting development in this space is the announcement of Endor at WASM IO which I'd like to try out: https://endor.dev/
Been a freelance dev for years, now going on "sabbatical" (love that word) shortly.
Planning to do a lot of learning, self-improvement, and projects. Tech-related and not. Preparing for the next volume (not chapter) of life. Refactoring, if you like, among other things.
I'm excited.
Right now it's all a flat index.html and simple.css hosted on github pages, but I'll get a site eventually. Writing a blog is part of my goals to become a profitable author. (Creativity ~= blogging, sketching, animation)
It lets users merge two or more workouts into a single one. There have been times when I have been out riding, hiking or whatever and accidentally end the activity on my apple watch instead of pausing it. Starting a new workout means having your stats split across the two workouts.
The "usual" way to merge such workouts is to export all of them to individual FIT files, then use a tool like fitfiletools.com to merge the individual FIT files. You then have a merged FIT file, which is difficult to import back into Apple Health. This process also requires access to the internet, which is not always guaranteed when out in remote areas.
MergeFit makes this process easy by merging workouts right on device and without the need to deal with FIT files at all. It reads data directly from Apple Health and writes the merged data back to Apple Health.
The app reached a small milestone a few days ago - crossing 1000$ in total sales.
I recently completed Valence: a language with polysemantic programs https://danieltemkin.com/Esolangs/Valence on GitHub: https://github.com/rottytooth/Valence
Older work includes Folders: code written as a pattern of folders: https://github.com/rottytooth/Folders , Entropy: where data decays each time it’s read from or written to: http://entropy-lang.org/ and Olympus: where code is written as prayer to Greek gods, who may or may not carry out your wishes: https://github.com/rottytooth/Olympus (a way to reverse the power structure of code, among other things).
I have three more to complete in the next few months.
here's a screenshot:
https://gist.github.com/1cg/e99206f5d7b7b68ebcc8b813d54a0d38
Can load source from gists https://k8.fingswotidun.com/static/ide/?gist=ad96329670965dc...
Never really did much with it, but it was interesting and fun.
An electronic board game similar to Settlers of Catan (https://github.com/seanboyce/Calculus-the-game), just received the much better full sized boards. Will assemble and test over the next few weeks, then document properly. I got the matte black PCBs, they look really cool.
A hardware quantum RNG. Made a mistake in the board power supply, but it still works well with cut trace and a bodge wire. Will probably fix the bug and put the results up in a few weeks. Can push out ~300 bytes of entropy a second, each as an MQTT message.
A hardware device that just does E2E encrypted chat (using Curve 25519). Microcontrollers only, no OS, and nothing ever stored locally. HDMI output (1024x768), Wi-Fi, and USB keyboard support. I originally designed it to use a vanilla MQTT broker, but I'm probably going to move it to HTTP and just write a little self-hosted HTTP service that handles message routing and ephemeral key registration. Right now the encryption, video output, and USB host works -- but it was a tangle of wires to fix the initial bugs, so I ordered new boards. Got to put those through testing, then move on to writing the server.
Iterating on hardware stuff is pretty slow. I try to test more than one bugfix in parallel on the same board. Iteration time is 2-3 weeks and 8$. If I have all the parts in stock. I don't have very much free time right now due to work, so this suits me fine. A rule I live by is that I must always be creating, so I think this is a reasonable compromise.
Its main differentiator: hover any thumbnail (homepage, search, shorts, etc.) for an instant mini-summary, like Wikipedia link previews. Also includes detailed summaries w/ timestamps, chat w/ video, chat w/ entire channels, and comment summaries.
Hover & Detailed summaries are free if you plug in your own OpenAI API key ("free for nerds" mode).
Aiming to be the best YouTube-specific AI tool. Would love your feedback. No signup needed for free tier/BYOK. If you try it and email me ([redacted]), happy to give you extended Pro access!
I think its impact on watch time depends on your goal of that session. When I'm in "looking for a specific answer" mode it does reduce my watch time, but there's plenty of times when I just want to watch youtube–and when I do, it helps me find what to watch, rather than reducing my watch time per se.
A ray-casting engine is an old style of game engine (think 1990 - Wolfenstein or Duke Nukem). The most famous, well-known example is probably Wolfenstein-3D created by ID software (John Carmack and John Romero etc!) You don’t see these engines used anymore in modern games.
So to me, they are novel and a great challenge to try and modernise. Especially as a solo dev! And for further context, raycasted levels are usually teeny tiny (Wolfenstein 3D or Shadow Warrior are the largest worlds I’ve seen, so nothing impressively scaled). I have never ever come across a raycaster with levels the scale of something like Minecraft. So that’s what my ambition is.
I spent a period of 2-3 months roughly 8-10 hour days every day on this project, not knowing much C and not knowing anything about game engines or graphics, and average at mathematics.
But I’m on a break from the project and coding after my 7 year relationship broke down. Realised I had tunnel vision with my life and ambitions, and am now “touching grass” daily instead. It’s hard to put effort into your hobbies when you feel other areas of your life are suffering.
So now I’m lifting weights and doing cardio and reading books instead, trying to keep active and my mind occupied.
I do want to pick this project back up, I’m really proud of what I was able to achieve with no knowledge coming in and I think the project has good bones.
And I loved coding, still haven’t found a hobby that scratches a similar itch
[0] - https://github.com/con-dog/chunked-z-level-raycaster/blob/ma...
The idea is simple: if your app can send an email, it can trigger notifications across multiple channels with no extra coding. Think of it as "SMTP Server to Anything."
One of the cool parts is MailTrigger supports WebAssembly (WASM), so you can customize your own notification logic and automate workflows. I’ve used it for tasks like monitoring internal systems, forwarding alerts to different chat platforms, and even adding basic decision-making logic before sending notifications. It’s been a huge time saver.
I’ve also experimented with using LLMs to assist in rule creation — you can configure notification rules using natural language instead of writing manual code. It’s like giving your infrastructure a smarter way to handle incidents.
At my company, I’m using MailTrigger for real-time price drop alerts and server health monitoring, along with integrations like Jenkins and Sentry to forward alerts to our DevOps Telegram channel.
It’s still super early, and things like the docs, pricing, and overall user experience are definitely a work in progress. But I’m iterating quickly and would love to hear feedback from this community!
Check it out here: https://mailtrigger.app/
Curious to hear your thoughts!
I wanted to check it out but using Brave Browser and Chrome on a Samsung A54 it took 10s+ to load. After a few seconds the spinner loaded, then the progress bar moved and then restarted and then loaded.
I’m sorry the loading took so long. I’m not entirely sure if the issue was with the main site or the Join Waiting List process. We’ll definitely investigate and get it fixed as soon as possible.
If it turns out that the waiting list form was the problem and you'd still like to join, feel free to shoot me an email at bear@nuwainfo.com — I'd be happy to add you directly!
Thanks again for flagging this. Your feedback means a lot and will help us improve!
Right now, each MailTrigger mailbox requires SMTP authentication (username/password), so unless someone has the correct credentials, they can’t inject messages. That gives us a basic layer of protection against spoofing from the SMTP side.
For forwarded emails (e.g. from Gmail), we do validate SPF, DKIM, and DMARC on inbound messages. Each mailbox acts as a gated endpoint — only verified senders are allowed to trigger actions.
As for pricing — you nailed it, we’re still working that out. We have a few rough ideas, but I’d genuinely love to hear what kind of pricing model would feel fair or sustainable to you.
Would you lean towards usage-based (like number of messages/month), flat monthly per mailbox, or something else entirely? Have you seen pricing models you liked (or didn’t) in similar tools like Zapier or SendGrid?
Your feedback’s incredibly helpful at this stage — really appreciate it!
I often read about interesting public companies (from an investment perspective or otherwise), but fail to then keep up with them over time (sometimes reading many months/years later how successful they were - or not!). I built this to make an easy way for me to follow updates from said companies.
Only feedback so far — I wish there was a bit of formatting for the numbers. The big blocks of text are hard to scan for important details.
Bullets are the first thing I can think of.
Key updates from the past month:
- New demo screencast [2]: Deploy a highly available web app with automatic HTTPS across cloud VMs and on-premises in just a couple minutes
- Added initial Docker Compose support for service deployment. The same Compose can be used for developing locally and deploying to your cluster
- Completely revamped how service and container specifications are stored, enabling proper implementation of the service 'scale' command and selective container recreation
My goal for Uncloud is to create a more capable and modern replacement for Docker Swarm, which is no longer being actively developed.
[1]: https://github.com/psviderski/uncloud
[2]: https://github.com/psviderski/uncloud?tab=readme-ov-file#-qu...
In addition to the code assistant, I configured a Grafana's MCP server with Cline, so that I can chat with an LLM while having real-time metrics and logs.
For context, I self host grafana in addition to a bunch of services on a raspberry pi. Simple prompts such as "why has CPU been increasing this week?" resulted in a deep analysis of logs/metrics that uncovered correlations I had never been aware of.
Incredible. I can only imagine what this will all look like in a few years
Thanks for this! :)
I spent time kicking around, had a work visa through BUNAC[0] but didn't use it, went to some festivals, did some WWOOFing[1] and hiking and climbing. Also took the opportunity to visit other countries near AU that I wouldn't get to otherwise (NZ, Fiji).
One of my life highlights. Two thumbs up! I doubt my experience is super relevant any more, but feel free to send me an email (address in profile) if you want to chat about it.
I am worried about my decision too, but I think about a few things:
- You got your current job (plus all of the previous roles), so why wouldn't you be able to do it again if and when the time comes?
- Job gaps don't look as bad as they used to. People understand burnout and being stuck in a bad job. Breaking away from those can be seen as a positive, especially if you are pursuing your own health and interests
- There's more to life than draining your useful waking hours for a paycheck at a place that offers little else. With more time and energy, you can explore interests and projects on your own terms
Best of luck in your future endeavors
I'm in a weird state that I have an okay amount of saving for me to do this, but I'm still worried because I had been through having almost zero money and two years of unemployment, I'm scared to get back to that again.
In the end, I know I have to let this thing go or I'll never become happy even if I'm making tons of money, gotta enjoy life sometimes, thanks for the words!
Best of luck in our journeys too!
It’s a TypeScript web framework that’s runtime agnostic, so it can work on serverless and servers (similar to Hono).
What’s different is that the focus is primarily just on TypeScript. There’s a CLI tool that inspects all the project code and generates loads of metadata. This can include:
• services used
• all the HTTP routes, inputs and outputs
• OpenAPI documentation
• schemas to validate against
• typed fetch client
• typed WebSocket client (and more)
The design decision was also to make it follow a function-based approach, which means your product code is just functions (that get given all the services required). And you have controllers that wire them up to different transport protocols.
This allows interesting design concepts, like writing WebSocket code via serverless format, while allowing it to be deployed via a single process or distributed/serverless. Or progressive enhancement, allowing backend functions to work as HTTP, but also work via Server-Sent Events if a stream is provided.
It also allows functions to be called directly from Next.js and full-stack development frameworks without needing to run on a separate server or use their API endpoints (not a huge advocate, but it helps a lot with SSR). Gave a talk about that last week at the Node.js meetup in Berlin.
It’s still not 1.0 and there are breaking changes while I include more use cases.
Upcoming changes:
• use Request and Response objects to make it truly runtime agnostic (currently each adapter has its own thin layer, which tbf is still needed by many that don’t adopt the web spec)
• smarter code splitting (this will reduce bundle size by tree-shaking anything not needed on a per-function basis)
• queues (one more form of transport)
Check it out, would love feedback!
> see how dark pool and automated trading behaviors are evolving and impacting the market.
[0]https://finance.yahoo.com/news/darker-dark-pool-welcome-wall...
We'll have about ~300 short audio clips to record, and we'll store/access them via an SPI SD card reader peripheral. Audio output via a MAX98357A combo DAC/class D amplifier that we'll talk to via I2S. Powered by 2 AA batteries. Programming will be in CircuitPython, which is a cool way to teach the kids programming. (There are easy libraries for talking to all those peripherals.)
The real key here is how migrations over time are handled seamlessly and effortlessly. Never again do you have to meet with half a dozen teams to see what a field does and if you still need it - you can identify all the logic affecting the field and all the history of every change on the field and create a mapping. Then deploy and the system migrated data on the fly as needed.
Still in stealth mode and private github but the launch is coming.
The difference is that I'm building a database and exposing the WAL to the application layer. What that means is that you can connect your legacy DB application and have it issuing insert and update queries which are now native messages on a distributed message queue. Suddenly you gain a conokete audit trail for your entities without brittle tables and triggers to track this. Then instead of hooking up Qlik or devezium, you can just stand up another instance of the DB, propagate the realtime WAL and you've got streaming analytics - or whatever new application you want.
Also, I've recently picked up modeling my financial choices and circumstances in Python. Modeling uncertainty is especially interesting I've found. I might share the Jupyter notebook some time to get some feedback.
- It will work as a library that a tool (e.g. family finance tracker) would be based on;
- Every record will be immutable and undeleteable; the whole thing is space inefficient, though I've some mechanisms in mind for pruning away unnecessary records, and it's just plain text, so I'm not worried: should compress well; I wouldn't envision something like this working well on a very large scale though;
- Editing of preexisting records will be implemented as adding a new record that simply references the previous one as its previous version; also, you can implement a ledger by creating a parent-child chain (though the tracking of signatures I mentioned previously might be a simpler approach);
- I like the append-only model because it gives you history of edits for everything, and protects you in case of mistakes (or malice);
- You'll be able to collaborate on records (and the whole db) with other devices/people; every record will be signed by its author/device; conflicting edits (records marking the same record as their parent) will not be deconflicted automatically by the db: the high level app can choose how it wants to do that: throw up an alarm for the user, ignore the older fork, whatever;
- SyncThing-compatibility will be achieved by simply having each device only edit files specific to it; there won't be a single file that is edited by more than a single device/user, thus, SyncThing conflicts can't happen;
- The db will have fairly good guarantees: if it runs its checks and tells you all's good, you can be sure that records were not changed, there is not a new record masquerading as an old record, a record was not secretely deleted, records weren't reordered, another device didn't edit some other device's files, every record's author is its author;
- It was important for me to make the database easily editable and readable via regular text editors, i.e. not only plaintext, but text-editing-centric, but I've not found a way to do that at the lowest level; right now I'm contemplating using some variant of JSON for the records; however, I do envision a text-interface where the database, or a database query/subset, is rendered as a text file, and edits are automatically picked up by a daemon and translated into new records in the actual db, but that would be just another tool using this db, not a feature of the db itself;
- Like for anything synced via SyncThing, the user (or an app using the db) will want to implement some kind of backup (SyncThing is not meant for backups), unless the data is not sensitive to loss.
PUGs need a way to communicate and broadcast, to be discovered, but it doesn't necessarily need all of Meetup's features. Also, PUGs probably don't want to be tied to Facebook or other social media platforms. It'd be best if they allowed a simple ownership transfer, once you get tired of organizing.
That's why I created https://pythonuser.group/ - a lightweight side project that, despite being rough around the edges, fulfills the core need: allowing people to discover PUGs worldwide for free. The platform costs me almost nothing to maintain. Allows to subscribe to local PUGs via RSS (not sure if it works). I'll add "export all my PUG data" once someone requests this feature.
It's the first time I share it with the world. Please don't treat it as prod-ready. Feedback welcome at hn@{username}.com
See here: https://imgur.com/a/e3Xo9Io
Carimbo source code: https://github.com/willtobyte/carimbo
More information: https://nullonerror.org/2024/10/08/my-first-game-with-carimb...
Started as a personal pain after moving to the US. Now works for both people and businesses. Built our own voice infra. iOS, Android for B2C, and web dashboard for B2B. Building full-time with my wife – just pushed the first version of the mobile app this week.
I do however think people would be more tolerant of an AI answering a phone call they made, I'm bullish on that half of the equation.
Absolutely not.
For younger kids I've modified Overcooked 2, a traditionally co-op game. I've replaced the second player with a visual scripting platform that allows kids to code their way through levels — worth noting I haven't removed co-op, there's still room for 2 other players:
https://www.youtube.com/watch?v=ackD3G_D2Hc
For older kids I've been making contributions to GodotJS, which allows you to build games in Godot using TypeScript rather than GDScript. GDScript is pretty nice, but I want to be able to teach kids skills that are more directly transferable to different domains e.g. web development:
https://github.com/godotjs/GodotJS/pull/65
I used to be Head of Engineering at Ender, where we ran custom Minecraft servers for kids: https://joinender.com/ and prior to that I was Head of Engineering at Prequel / Beta Camp, where we ran courses that helped teenagers learn about entrepreneurship: https://www.beta.camp/. During peak COVID I also ran a social emotion development book subscription service with my wife, a primary school teacher.
would the ability to pick up a new language/syntax be also a skill worth learning?
but my impression of the godot community is a lot of gdscript,some C#. So they would not easily be growing in the godot community and make games.
as for teenagers learning new languages, if i remember my teens, 200 years ago, learning new computer things was a thrill, not a chore.
and like I said earlier, I see the habit of picking up a new language a wonderful skill.
hope it is clearer. good luck with your quest of teaching kids to make their own games with godot.
Therefore, I‘m working on a mid- to longform blog post that details how precisely the competencies that senior developers and tech leads already have are the key to fully harness the potential of these tools.
And who knows, maybe I‘m going to develop this into some form of consulting or training side project.
https://manuel.kiessling.net/2025/03/31/how-seasoned-develop...
Feedback more than welcome!
https://manuel.kiessling.net/2025/03/31/how-seasoned-develop...
I've been working on building a programming method for biology labs. Basically, it is a dynamic execution environment using lua that can have full rewind-ability (for complete execution tracing) and pausing - you can execute some code then wait a week or so to continue execution. The idea is you can have a dynamic environment for executing biology experiments where the route changes on the basis of outcomes - something I haven't really seen anywhere else. Then I focused a bit on the pedagogy of LLMs so that you can ask an LLM to generate a protocol, and then when you execute it and get unexpected results, it can automatically debug its own protocol using a code sandbox.
It all sounds decent in theory but the difference is I actually implemented it and ran a real biology experiment with it (albeit a simple one that I knew wouldn't work)
Demo here: https://github.com/koeng101/autodemo (probably watch the video)
To start with, there's https://nuenki.app. It's a browser extension that selectively translates sentences into the language you're learning, so you're constantly immersing yourself in text at your knowledge level.
I've also been working with a friend on a device to help blind people without light perception. I'm quite new to electronics. It's pretty simple, conceptually - a coin-sized device on the forehead that takes in the light intensity in a ~15 degree cone, then translates it into high resolution haptic feedback to the forehead.
The idea being that it means people without light perception can gain a sixth sense through neuroplasticity, with helps them navigate the room and understand their surroundings. We're planning on open sourcing the files. My mum used to teach blind kids, and there's been quite a lot of interest!
As for Nuenki, I'm pretty bad at marketing, so I'm doing a final lot of work to see if I can make it work financially - seeing if an exceptionally generous affiliate program will do the trick - before putting it on maintenance mode, since I have a small group of users who really like it. I'm burning through my gap year fast, and really want to focus on the electronics project, tutoring, and practicing maths for my physics degree.
I just installed it and enjoying the integration.
I wanted a better way to keep track of applications I sent out, A spreadsheet just seemed like a poor way of tracking data. So overtime I built a desktop application to track my job search activity for me. Most alternatives are web-based, but I didn’t love the idea of broadcasting my job search to third parties. This is a native desktop app (Windows/macOS) that keeps everything local.
Still working on code signing (so no scary "unknown publisher" warnings), but otherwise, v1 is ready.
Would love feedback—especially from others who’ve struggled with job-search tracking!
That and I am able to customize the flow of applications, and the number of swim lanes would be a bit messy. I have my app setup to track interviews, phone screens, take home assignments, and many more.
I found that a smart sorting algorithm is best for displaying the applications.
But its still early days of the app, possibly someday.
https://github.com/Belphemur/night-routine
I wanted to build everything from the ground up in Go and have it fully integrated with Google Calendar where we have our family calendar.
It setup full day event with the name of the parent in charge of the night routine. To override a routine, any of us can just rename the event with the the other parent name and the software recalculate the following routines.
I also wanted to give a try to Roo Code in VS Code it only took me 2 days (evenings) to code the whole thing with a proper sqlite db.
Also, FWIW, I think I'm the one that is in the deficit of fair although dad's usually get a bad rep in this regard. I end up doing a lot more night time reps because she does frequent girls nights and has multiple friend groups she's trying to stay engaged with and is in a theater group and mahjong group, etc. However, I balance it with my occasional "take an entire day" to myself. Stuff like this is hard to track and why I think it's important to shoot for what 'feels fair' and make sure you talk about it occasionally so nobody suddenly has repressed feelings of inequality.
We wanted both a system that keeps track of it for us. We want to be sure we can both have activities while still not leaving the other parent on the side and rely on feeling.
In our case we also have recurring events like sport in the evening that happens every week at the same time so this help plan around it and not become unbalanced. We already put everything in the calendar :)
The big debate in my head right now is whether a next byte prediction architecture is better or worse than full sequence prediction.
The benefit of next byte prediction is that we only expect 1 byte of information to be produced per execution of the UTM program. The implication here is that the program probably doesn't need a whole lot of interpreter cycles to figure out this single byte each time (given reasonable context size). However, the downside is that you only get 256 levels of signal to work with at tournament selection time. There isn't much gradient when comparing candidates on a specific task.
The full sequence prediction architecture is expected to produce the entire output (i.e., context window size) for each UTM program invocation. This implies that we may need a much larger # of interpreter cycles to play with each time. However, we get a far richer gradient to work with at fitness compare time (100-1000 bytes).
Other options could involve bringing BPE into my life, but I really want to try to think different for now. If I take the bitter lesson as strongly as possible, tokenization and related techniques (next token prediction) could be framed as clever tricks that a different computational model could avoid.
One consistent annoyance in my professional work has been dealing with PDFs – specifically, extracting information into editable formats without losing structure. Copy-pasting often creates a mess.
So, my first project tackling this is an online PDF to Markdown converter: https://pdftomarkdown.pro/
I've focused heavily on trying to maintain good formatting for headings, text flow, formulas, and especially table structure (getting rows/columns right in Markdown). It also has an online editor for quick modifications after conversion.
A key aspect for me was privacy: the application explicitly does not save the content of uploaded PDFs or the generated Markdown files. It only stores minimal metadata (email, filename, page count) for registered users' plan limits.
It's very much a "scratching my own itch" project born out of that PDF frustration. Early days, but hoping it proves useful for others too.
I couldn't find a way to contact you, so if you feel like it, drop me an email (email on my website in profile).
The need for batch processing to pull out targeted data points from PDFs (rather than converting the whole document) is a valuable insight.
While the current tool focuses on full conversion to Markdown, enhancing https://pdftomarkdown.pro/ to handle specific data extraction tasks like yours is definitely something I'll consider carefully for the future roadmap. Thanks for highlighting it!
The goal is to allow anyone to know how much any car is worth at a given age/mileage, and eventually help people make better purchasing decisions.
Be warned: It's still a very buggy prototype at this stage and the data confidence for all but the most popular models is low!
With the recent flurry of historic events unfolding, I want to see it from different perspectives (e.g. U.S., Europe, Russia, China, pro-Palestine vs Pro-Israel), therefore I included channels from all these areas, even channels that may be considered propaganda. So keep a critical eye when watching them.
And it's a way for me to try out Vidstack and SvelteKit. Feels like the routing can be improved though.
Which I think is a valid answer. I have a job, family and some health issues.
The main thing I am looking at is blogging. Just posts on a problem I solved that week at work kind of thing. Seems like a low time cost way to promote myself. I might dip my toe in the cooking fat of linkedin engagement using the posts.
As much as that is yuk I feel it may be beneficial. Just need one linked in lurker to be impressed and hire me in a few years time!
And by not posting about AI or working 200 hour weeks I might stand out :)
Will continue to refine and possibly do more - love iterating and polishing as a way to learn.
Over the last 4.5 years, we've been developing slow-wave enhancement technology which increases the effectiveness of deep sleep.
We've developed the full stack, our own hardware, soft conductive dry (no paste or gel) electrodes, comfortable EEG headband, embedded sleep stage classification and stimulation models, the list goes on and on.
We're currently ramping up for a pre-sale, and getting the marketing inline, along with finalizing industrial design, prepping for manufacturing, etc, etc,
We'll be launching a pre-sale once we complete our fit testing (end of Q2 '25) and shipping Q4.
[1] https://www.affectablesleep.com/blog/is-8-hours-of-sleep-the...
Though, I don't think corrosion is the issue with Muse S, the electrodes tear as I understand it. Either way, they are not robust enough.
https://blog.tombert.com/posts/2025-03-22-swaybar/
I wanted some extra functionality for the Swaybar in the Sway Window Manager. I got a basic thing working with Bash, but I wanted more stuff, and so I rewrote it in Clojure with GraalVM.
I think it's kind of cool, I ended up with a fairly elaborate async framework with multimethods and lots of configuration, and the entire thing has almost no "real" blocking, and can persist state so that it can survive restarts.
The reason for async support was so that I can easily have my Swaybar ping HTTP endpoints and display stuff, without it affecting the synchronous data in the bar. I have TTLs in order to rate-limit stuff, and also have click-event support.
Right now, I have it ping OpenAI to generate a stupid inspirational quote based on something from a list of about two-hundred topics. Right now on the top of my bar it says:
> "Let the flame-grilled passion of life's challenges be your fuel for success" - Patty Royale
I think it's kind of cool, it's building with Nix so it should be reproducible, and with GraalVM, it hovers at around 12-15 megs of RAM on my machine.
One thing you can do is separate the information fetching from your bar completely. I have a service that runs every minute or so to fetch available updates from the arch repositories (including aur), it writes its output to a file and then my bar regularly updates it's displayed information based on that file.
I don't have the service definition uploaded anywhere, but you can see how simple it is to then integrate it with anything here [1]. This is a status bar I'm building with qml. It's not ready to be released yet, I'm at 0.7.0. Only tested on x11/i3wm so far. Last time I launched it in wayland/sway, there were some issues but it's been a while since. Since it's built with qt complex and non-blocking interactions are available out of the box. For example, switching workspace by clicking an icon in the bar, or switching the format of the displayed date time.
I do have the state persisted in a msgpack binary, but the data fetching is done within the app. I don’t know that separating it out would necessarily be better, I kind of like that I have the pipeline set up on such a way that the fetching for sync and async stuff can be reused.
I am debating rewriting this to use the slightly lower level NIO selector class instead of core.async, but the memory on this is low enough to where I am not sure that it’s worth it.
I have been writing a lot of helper apps in Rust for Sway as well, mostly as an excuse to play with Rust more [1] [2].
I will take a look at your stuff. I have wanted an excuse to learn a bit more about Qt.
Anyone else?
Boss of guy from Minnesota was kicked out of the company. I'm told the guy from Minnesota is now sooooo much nicer now.
I wish you luck :)
Capture everything going on in the Family.
Let me elaborate. Families attempt to use a Shared Calendar when things get hectic, but they don't capture everything going on, because most of these events are just too tedious to enter into a traditional Calendar. Voice Assistants are not tailored to capture the kinds of Events that families have. Examples below. So, families either don't use a Calendar, or one person in the family ends up spending too much time keeping everything in sync.
Examples of flexible events that KIN can handle: 1. Aditi has School board meeting on second Tuesday of every month. 2. Aadi has chess on Tuesdays and Thursdays from 6 to 7, and Saturdays at 11. 3. Rushi has after-school Soccer every Wednesday starting April 3rd, for 10 weeks. 4. Create events from Screenshots or Photos.
Coming in next Release: - Send Reminders to other members in the Family! e.g, Remind Aditi to pick up Rushi from School tomorrow at 3 pm.
It started as a personal project a few months back. Since then, I have been using it myself, alongside building the functionality I need. Lately I have been working on polishing it up in order to put it out there for others.
Based on my usage so far, I've come to realize some good second order effects too -
1. having a list of exercises helps me quickly pick something meaningful to practice rather than noodling for most of the time.
2. At the end of a practice session, the total duration is just 15-20 mins yet it feels like quality practice. So now, even if I have just 20-30 mins of free time, I am motivated to squeeze in a quick practice session. Turns out, this is a game changer (at least for myself).
Feature wise, I'm quite happy with the current state of it although I have some ideas for premium features (if it generates enough interest). In the coming weeks, I am planning to switch gears a bit and focus more on marketing/promotion. I also need to play more, because ironically, my practice time has reduced in the last few weeks in the pursuit of "launching" it! Also, I've set a goal to publish one new exercise in the library every week until the end of this year.
I had this idea in mind for some time already, it began with me wanting to build a simple programming language (and learn in the process) and interest in Bazel. I got started about a month ago by going through the Crafting Interpreters book by Bob Nystrom (it’s crazy good), but now Im straying further and further away from it.
Overall I find the project a great mixture of fun and challenging.
It’s a private repo for now because it’s in a pretty rough state, and is still missing a lot of stuff, but I will release as OSS at some point. That said if someone would like it could be fun:)
Not a professional developer so I suspect these projects look a lot more like slugging through mud and trying to navigate through a maze in a pitch black environment, and I've found these tools to be helpful especially in small refactorings that would normally result in me just slowly losing interest in the project.
Anyways, https://pianobooth.com is the latest one! Gave me an excuse to learn some Blender as well. It'll play your midi files (well, it might play your midi file) and show the notes being played on a keyboard. :)
Lots of room for improvement. It now works on most of the midi files I've tried, but it's still glitchy and buggy. But at least it works sometimes!
Maybe I'll finally get some of the more obvious improvements done and have something a bit more polished this week. :)
After spending a few years developing it for internal purposes, a customer decided to contribute a significant amount to its ongoing, open-source development, plus additional closed-source commercial add-on modules for their own use: making the accounting software useful for very specific industries.
Currently it's piloted running payroll & profit/loss/balance sheet for a handful of small businesses, with the rest of the usual modules (accounts payable, invoicing, quoting, etc.) slated for release this year.
Technology stack is currently Python plus Preact; "severless" architecture where each node maintains a replica of the data involved and can replicate it to other nodes. User interfaces is either CLI or web-based, with an eye towards eventually replicating the desktop user experience of popular accounting packages of times past. We are taking a hard look at shifting from Python to Rust simply as we rely heavily on third-party packages, and Rust is where a lot of the active development in that space is going.
The most fun I had was finding a module written in Perl and Postscript, porting the Perl part to Python, and realising the existing Postscript was excellent and needed no improvement. (Our team now has more Postscript competency than we ever planned to have.)
If you're interested, see my profile for an email and put "HN" in the subject.
Here's a synopsis of the plot, redacted since I've already revealed too much :)
-----, a college student from ----- majoring in -----, graduates from university and is recruited to work for a mysterious company that has links to -----. Initially hired as a translator, his talent with electronics get noticed quickly and his superiors begin training him for a covert overseas operation in which he will visit ----- as an exchange student while really serving as a spy.
With a soft spot for ----- culture, he is excited to visit ----- for the first time. Although he is fully aware he could be killed or imprisoned there, his confidence in his ----- language skills, plus a bit of youthful naiveté, make him jump at the chance. As he carries out his mission in -----, he uncovers a tangled web of family secrets.
It offers standard features like chatting with videos, summarization, FAQs, note-taking, and extracting sources mentioned in the video. We're taking it a step further by extracting relevant information from video frames and making it easily accessible.
Basically, I've noticed a bunch of social media protocols like ATProtocol, ActivityPub and Nostr are coming out and I think while having these protocols is a good idea, one thing limiting adoption is lack of differentiated social media sites on these protocols. Basically everyone keeps building twitter on a new protocol without offering anything novel. One bottleneck, I thought, is that there isn't a set of utilities to help build a new social network easily so everyone defaults to building twitter as an MVP. I wanted to make an engine, kind of like a game engine, but to make a custom social media for any particular protocol. Hypothetically this should make it so that development for these kinds of projects go way faster. Basically, like a very opinionated django rest framework. Hopefully developers will build more interesting, novel sites and increase adoption for these protocols
[1] https://github.com/kwon-young/units
[2] https://github.com/kwon-young/units/blob/master/examples/spe...
This makes Postgres itself stateless and all data storage and transaction processing is handled by FoundationDB, turning Postgres into a fully distributed database akin to CockroachDB and others.
This has a number of advantages: - Simple horizontal scaling simply by adding more nodes, including automatic sharding (no need for Citus or similar) - Distributed and strictly serializable transactions across all your data - Automatic replication for durability and read performance. No need to set up read replicas or configure your client to route queries to them. - Built-in fault tolerance that can handle node failures and full zone outages. No need to configure replication and failovers. - Multi-tenancy through FoundationDB's built-in tenants feature
All this while not just maintaining Postgres compatibility but actually being Postgres, so hopefully all the features/extensions you know and love will be supported.
I'm planning on publishing to this repo if you want to keep an eye on it: https://github.com/fabianlindfors/pgfdb. Likely won't publish any of the source at first but just some instructions for testing it out.
https://www.yogile.com/strides-of-march-2025
and Dragon Day at Cornell, where I am spooling out pictures to
https://bsky.app/profile/up-8.bsky.social and https://mastodon.social/@UP8
I'm excited that I'm getting paid to do an event next week because that's been one of my goals. I feel like I'm really progressing at understanding event venues to pair up interesting foregrounds with meaningful backgrounds as well as painting events in a strongly positive light when other photographers might do otherwise.
(2) Coding: I have several applications that use arangodb, a document/graph database that unfortunately, like most innovative databases of the 2010s, has a terrible license. I don't feel I can either commercialize or open source these things so I am switching them over to use JSONB support in Postgres. I am building an adaption layer that works like "python-arango"
https://docs.python-arango.com/en/main/
this is not a complete replacement because I'm not using many features like Pregel or Foxx and in some ways it is more functional because it supports primary keys being integers or uuids. Out of about 50 AQL queries I think there is just 1 that might be challenging to write in SQLAlchemy. It's interesting in that I am triangulating between the implementation being simple, being able to modify my applications if necessary, and also developing the API that I really want in the long term.
I've seen some pretty fun novel use cases, such as (multiple!) people using it to pick out glasses, wedding invites & so on -- https://apps.apple.com/us/app/rankpic-photo-ranking/id160299... (ios) -- https://play.google.com/store/apps/details?id=app.rankpic.ra... (android)
I mostly wanted an excuse to play with shaders and WebRTC, but I also like the idea of being a sort of “dungeon master” but instead of writing a campaign, I populate the world through procedural rules, and adjust the rules based on how we all end up playing as we go, adding things to stumble upon and keep it fresh in an organic way.
Lately, I've seen a growing interest in academic content from non-researchers, so I'm focusing on features like automatic summarization and LaTeX math explanation to lower the barrier. I hope this helps more people engage with research and ultimately push global innovation forward.
If anyone is interested, here's a quick 1 minute demo: https://www.youtube.com/watch?v=L1i8Yp_APbg Feedback is always welcome!
Also, very interested in synthetic biology atm, I’m taking HTGAA - https://www.media.mit.edu/courses/htgaa/
Otherwise, look out in Jan / Feb next year for applications to be a 'committed listener'.
Blogging by email. The best way to blog.
Pagecord makes blogging so effortless you'll want to write more. Publish posts by sending an email (or use the Pagecord app). Your readers can follow you by RSS, or subscribe to your posts by email.
Share long-form posts or short stream-of-consciousness thoughts. Both look great!
Pagecord is independent, open source and built to last :)
You select some text with your phone and share it with my app, then the shared text is reformulated to a flashcard (with the help of a llm).
You can then browse your flashcards in the app, but I’m also working on ways to show the cards to you with less friction: Like on the phone lock screen or on the face of your watch.
1. A Haskell client library for Tigerbeetle db: https://github.com/agentultra/tigerbeetle-hs
2. smolstore, the smallest possible event sourcing database: https://github.com/agentultra/smolstore
I've been more or less sick for the most of Q1/25. Always some cold, coughing, sometimes worse. Went to work nevertheless most of the time (stupid, I know), because... I don't know. Guess I think work is more important because it gives me the feeling of being good at something and worth it.
Didn't take much care about eathing healthy, getting my gym routine done or even enough sleep. Lots of other stress, too.
Not sure how much I can change from Q2/2025 on but I'll have to start optimistic. Some clouds are clearing up, some problems and issues are gone or being taken care of, can only go up from here.
All the best for everyone.
While doing that, I realized that I actually have some fundamental issues with my architecture.
When I find myself playing whack-a-mole with bugs (especially with a Watch app), then I know the fundamentals are suspect (the app is one that has been in the App Store for over a decade, in one form or another, so it does have some bitrot).
So I'm redoing the engine, and will probably substantially rewrite the app, itself.
A lot planned, not much built. Just started so follow along if it sounds useful! Also see my prior thoughts on the topic here: https://news.ycombinator.com/item?id=41286912
Sqratch - https://github.com/jkcorrea/sqratch
https://github.com/Melvillian/navi
Checkout out the README; it gives you a straightforward idea of how Navi works. Currently only works for Notion, but the idea is to make any notetaking tool (Obsidian, Evernote, Google docs, etc...) be ingestable by Navi.
Next steps are to make an SRS plugin, and to make a HTMX-based website so it's useable beyond just the CLI.
[0] jacobin.org
The 8.5 inch racking system was inspired by Jeff Geerling's video about 10 inch rack, but shrunk even further to allow me to fit it on my 3D printer bed (8.6 inch square). I currently have parts for the top and bottom of the rack, as well as 1U and 2U expansions that you can slot together to make the rack as tall as you want. I'm also thinking about making a side attachment system so you can clip fans onto the side or similar. Once I have a working rack with several units in it, I'll probably end up publishing the parts and a writeup about it
I'm writing bigger CLIs with it now and I want to tab through their subcommands and flags, as well as allow customization - suggest values for the current flag based on previous flags' values.
It's been a lot of work (9 months of quite limited side project time)- I had to rearchitect significant parts of the parsing to keep more state around, and learn how I want to approach communication with zsh, but I just need to add some tests and an option or two more and it'll be good enough for most CLIs I wrote.
Oddly enough, I'm procrastinating actually finishing it. I've really enjoyed the "grind" for this feature, and I'm also taking the time to clean up the API if I think of better versions. Being able to noodle around with no pressure (except internal) to deliver keeps the joy in programming going for me.
But, after this is done and integrated into my CLIs, I plan to take a left turn and try to add really good OTEL tracing and visualization to my CLIs- I think I can outut OTEL traces to log files and then embed logdy.dev subcommands for really nice searching and visualization.
I'm doing it for my personal use, but maybe someone will find it useful too ;)
It’s been handy for big purchases I’m ok waiting for and stocking up on recurring non-perishable essentials when they go on sale. It also lets me know when something has come back in stock.
Suggestions by this platform wouldn't interfere with treatment protocol straight away; it wouldn't ask the patient to stop medicines their doctor has prescribed, or itself prescribe scheduled drugs.
It will suggest complementary interventions. Case in point: anxiety, depression, brain degeneration & other related diseases - there's Rhonda Patrick's protocol of HIIT exercises to breach the blood-brain barrier & deliver positive effects; there's Dr Chris Palmer's method of looking at metabolism & mental health jointly & benefits of a keto diet to solve such issues.
Likewise, there can suggestions from Yoga-Pranayama where deep breathing can solve insomnia & hence other diseases downstream such as hypertension in many cases.
After being on such complementary protocols, the patient's suffering will be reduced, but also the body will heal enough to an extent that their local doctor could reduce/stop medication.
The tech is in the platform, combing through wisdom of all such complementary protocols for a start. If it gains traction, we could start involving experts have system route some queries specifically to them.
I have experience building the ML-LLM part. Anyone wants to join me and build the full stack part?
I finally cracked ansible/docker-compose provisioning on Ubuntu and plan to expand that out to support Debian also. The groundwork is there. I can finally see an official release in the distant horizon, I just need to put those quality of life features in now, like the ability to delete your own account, change your email address, notifications on comments and all that stuff.
- The idea: https://carlnewton.github.io/posts/location-based-social-net...
- A build update and plan: https://carlnewton.github.io/posts/building-habitat/
- The repository: https://github.com/carlnewton/habitat
- The project board: https://github.com/users/carlnewton/projects/2
If yes, do you think it's already mature enough to give it a spin?
I would recommend it for everything you said except for this part. Everything posted is publicly visible by design. I'm afraid I have no intention of changing that. You're free to fork it if you want though.
https://www.linkedin.com/posts/brynet_openbsd-activity-73074...
Basically it’s a way to enforce custom policy rules on GitHub PRs without writing any scripts or maintaining any custom Actions. It’s got all of the customization that you wish GitHub’s built in branch protections had.
Things like “make sure the frontend tests pass if there are frontend code changes” or “require 2 approvals only if there are no test files added” are trivial to write and enforce.
Last week I published a new version for my awk ebook (https://learnbyexample.github.io/cli-text-processing-awk-ann...) and today I'll start working on sed ebook.
It's privacy focussed and does not connects to the internet, your notes stay on device which you can backup and import into other devices, and I am working on a quick qr share features too.
My idea was that there are almost no android apps with this kind of design vision even though there are fans of this design out there as can be seen with the trend of people modifying their termux startup screens and the huge downloads of windows mobile styled launchers. And so I want to make a design system that provides an open source go to system for others to make apps with this design
Source code: https://github.com/ronynn/karui
It is shaping up nicely towards an actual 1.0 release in the near future, with a little less keccak based AEADs this time around. It was a fun experiment but in the end I have yet to do any cryptanalysis on it or provide security proofs for it - neither which I have time for at this point - so the swap to AES was expected on my end.
For fun I also added a fully e2e p2p voice chat client on top of this as the sanctum protocol is now available as a library (https://github.com/jorisvink/libkyrka) - this voice chat works with one or multiple peers and can is available at https://github.com/jorisvink/confessions.
Either way, I guess you can say I'm having a little bit too much fun with this.
- Group chat that keeps all travel discussions in one thread
- Interactive maps where everyone can pin locations and add notes
- Collaborative itineraries that sync with your calendar
- AI travel assistant that suggests activities and helps optimize your plans
## What is DeskPal? DeskPal stands for Desktop Companion - exactly as it sounds: A companion for your desktop.
It's a gadget that will: - Display your media info (From Spotify, etc. - more sources to be added) - Display time - Connect to your phone and display notifications (TBD) - Function as a StreamDeck-like device (TBD)
All of these features should work right out of the box, without installing any new apps on phone or computer: - You can use it with your company laptop, or even with no computer at all - An app may be needed to configure some settings (like StreamDeck macros - TBD)
## Hardware & Software Inside DeskPal is an ESP32S3 MCU that supports both WiFi and BLE. The current configuration has 16MB Flash memory and 8MB of SRAM.
DeskPal runs on Zephyr RTOS, a RTOS that is heavily supported by many vendors. Using Zephyr allows us to leverage a vast ecosystem of hardware drivers and enables easy porting of this project to other MCUs if needed.
DeskPal's software architecture allows adding dynamic apps so that we can install or remove functionality without firmware updates.
It's hard to juggle between the two.
[1] https://beyond-tabs.com [2] https://github.com/andreamancuso/rivar-lang
This split minimizes external dependencies and makes it easy to manage complex pipelines without leaving PostgreSQL.
I started pgflow because I wanted a fully integrated, Supabase-based system (no separate servers!) for reliable, parallel workflows which keep state in postgres so I can trigger flows from triggers and stream their progress via Supabase Realtime.
Started protytyping it in early November, released serverless task queue worker in January and I'm currently polishing the flow orchestrator pieces, releasing an alpha version in upcoming weeks.
If you're curious:
- More on Twitter/X: @pgflow_dev (https://x.com/pgflow_dev)
- Edge Worker docs (will get flow orchestration docs included soon): https://pgflow.dev
Reddit updates:
- https://www.reddit.com/r/Supabase/comments/1jfrky2/huge_mile...
- https://www.reddit.com/r/Supabase/comments/1ij9jcl/introduci...
Happy to discuss or collaborate if anyone's interested!
A friend gifted me a large box of semiconductors, and I'll be testing 7400 and 4000 series chips for the next week once my T48 EPROM Burner/IC tester shows up.
It's still a work in progres: https://github.com/mx4/gnss-rcv/
Some notes on the UI:
* I found the 50/50 split between video / map a bit annoying, especially on a 13" MacBook
* The volume slider takes up a lot of valuable space, and felt like your normal scrubber to scroll through the video
* Once you confirm a location, the whole UI changes again
* Overall (especially on my smaller screen), there was a lot of scrolling involved to get to buttons
So I built Slate — an AI-powered workspace that supports long-context reasoning (up to 1M tokens), persistent memory, and lets you work with multiple models (OpenAI, Claude, Gemini, etc.) in a Notion-like interface.
It’s still early, but live. If anyone here experiments with long-context LLM use cases or AI tooling, I’d love your feedback — and I’m currently giving away credits to try the Gemini models because I’ve got $300 worth that expire in 48 hours. No catch, just want it used and tested.
First time building and launching something on my own — excited but also a bit overwhelmed. Appreciate any thoughts!
URL: https://boxento.app/
The AI is trained on 40,000+ hours of real psychotherapy sessions and provides individualized emotional guidance to help users manage stress, anxiety, and trauma. We partner with public institutions to deliver large-scale support and just launched a B2B program for employers.
Now preparing for EU expansion (starting with Germany), mobile app rollout, and voice interaction in Ukrainian. This is not just a chatbot – it’s scalable mental health infrastructure.
→ https://ai.psyhelp.info → https://chat.psyhelp.info → https://chat.dev.psyhelp.info (+voice)
I'm askng because the answer will shed light on the level of privacy "the average consumer" is comfortable with.
We don’t train on user chats directly. Instead, we collaborate with a team of 42 certified psychologists who work with us to curate anonymized case structures, decision trees, and response strategies based on real but depersonalized therapeutic experience.
These professionals help us model how psychological support is provided — without ever using actual user conversations. Our system is trained on synthesized, anonymized session data that reflects best practices, not private logs.
It’s not buried in the T&Cs — we’re very explicit about our commitment to data ethics and user safety. No session data is used for model training, and user interaction is fully confidential and never stored in a way that links it to identities.
Our goal is to make high-quality support available without compromising trust. Let me know if you’d like more technical or ethical detail — happy to share!
Those decision trees sound interesting - are you, essentially, integrating an LLM and an expert system?
We combine the flexibility of an LLM with a structured layer of expert-driven decision trees and psychological frameworks. This hybrid approach lets us preserve nuance and personalization while maintaining safety, boundaries, and clinical integrity.
The decision tree layer is used both to steer responses contextually and to define escalation protocols (e.g., for suicidal ideation, PTSD triggers, or crisis states). It’s informed by standardized practices like CBT, trauma therapy, and psychological first aid, co-developed with our licensed psychologists.
So yes — think of it as an LLM augmented by a domain-specific expert system, designed for real-world psychological use.
Happy to share more if you’re interested in how we’re scaling this across multilingual and cultural contexts)
Also considering working on a traefik plugin + helm chart for sending LLMs that ignore robots.txt to a tarpit like iocaine/nepenthes
The one that's furthest along is a database and (currently extremely crude) webapp for asking interesting data type questions about Lotus setlists. I built a little scraper for Nugs and have all their setlists, I just need to take it further and get some of the queries I want implemented and put some kind of halfway decent interface in front.
I also built a little app that uses your Claude API key to generate "generative art," so you send in a prompt and it sends back some visualization code and renders it. It's fun to mess with but I haven't seen anything come out that's wowed me yet.
Got some other little hackeries going too, a lot of my recent hacking time has gone towards getting the -arr apps and their whole little ecosystem set up on my home server. I got a little N100 machine back in December and have been having tons of fun hosting little docker gewgaws.
Fluid's website is https://fluid.so and Fluid Link is available for download at https://fluid.so/fluid-link
Fluid is currently free (until tomorrow?) and Fluid Link is free to try up to 15 minutes at a time, with no restrictions on functionality. There's a discord server and in-app support chat for support questions, and videos demonstrating Installation and usage on YouTube.
If you have lots of money to burn and want to support a queer artist in the Gulf South, I have a Patreon.
Setting up AI agents is way too complicated. I am constantly being sent to GitHub pages with installation instructions that require way too many dependencies, API connections, and more. We’re talking hours of setup and config.
So what if there was an open-source marketplace where you could just search, find an agent, click deploy, get launched into an already configured agent, and just have it do its thing? Essentially a marketplace discoverablity, automated deployment infrastructure and an interface to manage your agents.
I’d also probably create some kind of open-source solution, probably a custom Docker container, so developers can easily build agents and wrap them in a container and upload them for deployment.
Thoughts? Does anything like this already exist?
P.S. No, I don’t want to build or use another crappy AI agent builder. I want to deploy open-source agents already built by actual developers.
I'm developing a wargame-like 3D simulator designed to train AI drones into elite stealth pilots. By integrating reinforcement learning techniques and utilizing real-life local landscape data, the simulator offers highly realistic mission scenarios.
It's easy to add it as a plain overlay over the screen if you're graphing a function, but I really want it to be able to plot arbitrary expressions with free variables where it just infers the axes, so you can just see values overload in the orthographic view (press alt-q to see that). That way you can just write something like (ss p.x 0 10 | graph) on any expression and visualize it as you go. I haven't quite figured out how to make it seamless though...
It's currently an upsell management and fulfillment platform built for hosts and property managers who list on Airbnb, Booking.com, and other travel websites. My goal is to make staying at Airbnbs as great as staying at a hotel (without the downsides) by building experiences for guests.
This currently includes the ability for the hosts to offer things like meal plans, at-home massages, etc. In the future, it will help them offer a faster check-in process, make personal recommendations, add interactive guides, and maybe even neighbourhood treasure hunts that involve other travelers.
[1] https://hostup.ae [2] https://antler.co
https://parallel-arabic.com/about https://github.com/selmetwa/parallel-arabic
Using the Shelly Pro EM for energy monitoring (it has 2 CT clamps, one is going on the PV output, the other on the grid input).
The data will be collected in Home Assistant on a HA Green device. Additionally, we have "smart" electricity meters here, these have a port which can be used to fine grained power & gas monitoring, should be possible to integrate that into Home Assistant as well.
It's not anything particularly challenging, it's mostly refactoring my electrical distribution board to make room for the Shelly device, routing ethernet cables, and installing some power sockets and a network switch to tie everything together.
The motivation for creating Circuitscript is to describe schematics in terms of code rather than graphical UIs. I have used different CAD packages extensively (Allegro, Altium, KiCAD) in the past and wanted to spend more time thinking about the schematic design itself rather than fiddling around with GUIs.
The main language goals are to be easy to write and reason, generated graphical schematics should be displayed according to how the designer wishes so and to encourage code reuse.
Currently trying to improve the docs and also release an online IDE. Please check it out and I look forward to feedback!
Reverse chronological is sacrosanct, and it will never have ads (there is a recently added subscription option). I plan to do a proper launch soon but I'll admit anyone who signs up to the waitlist from this post.
I've already found so many cool resources from it and we literally just got our 1000th post!
Other fun milestones:
[x] First user I don't know
[x] First paying customer
[x] First user to surpass my usage
[ ] First lynkmi marriage
Check it out at https://lynkmi.com/
A few manufacturing companies that I have a close relationship with are using it and love it, but I have kind of hit a wall with other growth avenues (Google Ads, organic promotion on the web).
I have been thinking of marketing directly to ISO 9001 auditors, because “can you get email reminders” is a question they have asked at multiple companies I have worked at. I feel like cold mailing them something branded (e.g. notepads) might work, but I am not sure how much money I want to spend on it if it doesn’t and it’s also a bit nerve-wracking to put myself out there like that.
It's a worthwhile project to build yourself. If nothing else I found out that I definitely do not like the date-fns library in JavaScript. I built it using AWS Amplify, and although I like that it scales to zero, but I think there are too many gotchas to Amplify, and especially DynamoDB, for a startup app that you want to move quickly on. I wrote up one of the major ones after I got really frustrated. [1]
Like I said in my original post, I am trying to figure out how to get it in front of the right people (who are less likely to be on HN). I have kind of decided that the B2C sales experience is not great unless you get a critical mass; my experience doing sales in manufacturing is working the booth at trade shows, talking to people about engineering, and using our process tools to develop a solution to the customer's problem. The more scattered "compete for attention" advertising/promotion sales model doesn't seem great unless you have a lot of money behind it.
I'm rambling, but if anyone likes this or feels it needs a certain feature, feel free to reach out. If you're in Boston / Providence I'll happily grab a drink with you.
[1] https://gist.github.com/rchowe/1db32f1f26d74688a9b4083a19f6a...
reddit /r/manufacturing
PracticalMachinist.com has a Metrology section and there's always a healthy discussion going on in the General forum.
This year, I started my first original content, Unmuted, which is a series of interviews with regular gamers about how gaming is part of their lives and their gaming habits. It's going pretty good so far with 2 interviews done. This is the latest one: https://www.thegamingpub.com/features/unmuted-002-mateus-kar...
The hardest part is sourcing the people to be interviewed.
I'm aiming to solve the problem of wanting to build a game but having to build all these extra "other" systems around it (leaderboards, stats/analytics, saving and loading game state).
Right now you can drop Talo into your game for player management, authentication, leaderboards, analytics, game saves and player segmentation. There's a dashboard too so you can visualise all of your game's data.
It reads from a replication stream and allows you to trim/enrich the replicated data by running SQL queries from the database, then writing the result out to another database (also using a custom SQL query, so it's easy to do upserts or joining with other data on the destination database).
It's working really well, and I'm just sprucing up logging and documentation a bit before making the source code public on github. The idea is for it to be a much simpler alternative to things like Debezium for small to medium sized projects.
Currently supports postgres for input, and postgres and clickhouse for output with more databases coming down the road.
It's an AI-powered relationship coach supported by an specialized AI swarm following integrative therapy principles. It started off by me thinking "how would an AI relationship therapist work if they could see both sides of an argument" to me reading up a lot about integrative therapy, experimenting with various AI agent architectures and landing on this approach now.
I'm pretty happy now with how it works. Even my wife, which is not really into AI and is a coach herself is using it regularly.
Since it's strings, I just render to file for backend static site generation, then frontend I use diffDom library to do efficient (enough) updates from html string without destroying dom state.
It works really well, but I also don't allow inline event listeners (they make everything much harder), so I've been learning how to leverage event delegation. All in all a pretty fun side project.
1. Async and conditional effects without hopping component boundaries with switchMap
2. React.Context ritual vs oneliner `pipe(shareReplay)` - this is easily the most useful thing, in lines of code alone
3. React is used shallowly for jsx and html, and rxjs is used for events and state and quite literally everything not writing to the dom.
4. Lazy by default, no need for suspense bc it's inherit property of observables.
5. Merge and combineLatest give you algebraic tools for constructing your logic instead of stringing components down a subtree
6. Scan but that's just inline redux reducer but I use it all the time
7. Observables are on standards track for HTMLElements in browser. - element.when('click').map/filter/takeUntil etc.
I view react as promises--. You have to do wildly hacky things using custom API ideas that change between majors, can only use sync functions, yet all your logic is async. It's like the function coloring problem on steroids.
The maiden voyage of my blog will be soon, it's first big write up will be the test page for this jsx transform, then I'm gonna be writing a field guide for how to translate between react and rxjs.
Incredibly good reference imo: https://dev.to/mfp22/rxjs-can-save-your-codebase-49fi
Tried to make this concise but I'm on mobile
So I'm working on an electron version[1] that has what I remember of the core UX. I wasn't the best user of NV – I'm sure it had features that I didn't use. If there are features that it had that you used, I'd certainly like to be aware of them.
1. Hardware a. Trying to create my own mechanical keyboard: already modeled, how finding a suitable printer. b. Waiting for a display to arrive so I can wire into my digital calendar. c. Waiting my modem HAT to arrive to go to phase 2 of my self hosted server.
1. Software a. Preparing my next blog post. b. Working on my distro.
References:
- Blog: https://blog.terminal.pink - Distro: https://terminal.pink/lin0/tree/index.html
NB: I know my certificate expired.
The theory seems to check, but I can't/won't be convinced until the tools based on it are complete and working without friction or exception. Many times it has felt like I was tilting at windmills, but every challenge eventually caved.
An epic (for me) black triangle moment approaches! (Discovered that term here on HN.) An algorithmic triad the color of space without light is a poetic, but not misleading description.
Wish me luck!
On the business side, things seem to be well lined up.
So my apologies for being indirect. Not trying to be "mysterious".
I just favorited your comment. So at any moment I feel I can be more straightforward I will reply to any comment you make in any other thread. That will be a good moment too.
I tried to make the dashboard experience really seamless and even used a physics engine in there. I think I did achieve this though, but I ended up spending more time on the UI than the dashboard contents. IMO infinite canvas UIs are not utilized enough.
Try it out and tell me what you think. Currently, it only shows what I put up there.
Currently in progress of implementing DevOps AI which will configure properly your deployment based on the source code.
- [1] https://dollardeploy.com
Product live at https://malak.vc OSS source code at https://github.com/ayinke-llc/malak
I have a use case to have a need to provision at will hyper-v instances for others to have control over fully. I've looked into proper things for things like SCVMM and Azure local and really they do suck..
So off to build a set of automation scripts to provision hyper-v inside of hyper-v attached to S2D shares and give students admin access to them and work in teams to build things on their own.
Its going to suck... I've done this exact use case using openstack, incus, proxmox and they all kinda suck...
I need project isolation, I need freedom, I need compliance.
The compliance is where I'm stuck with hyper-v due to the powers to be....
Wish me luck!
I've run the project through cline and roo. Also tried Claude 3.7 and the 1M context Gemni 2.5 pro model. I'd say Gemini is less creative. But it's still good.
I can see how it is a productivity booster. Or at least it gives you the illusion of one. Really I think best part of it is just building out detailed documentation. That's really the killer app for me.
I'd always found web app backends to eventually need something that chained background jobs together. And inevitably, it was something bespoke without a lot of observability. It was always frustrating to maintain. And while building AI RAG pipelines, I've run into the same problems.
Just 2 or 3 bugs remaining before people can start playing with both River and Freenet which hopefully means we're days away (touch wood).
[1] https://github.com/freenet/river [2] https://freenet.org/
To that end, I just did a show HN on a couple of my projects
What if google did not focus on hyper commercialisation? 10 Blue links, but sorted by how they answer your query- https://www.unlob.com
Can we answer questions with lesser hallucinations? A snippet cited answer engine which only picks links that focus on answering your query - https://www.unzoi.com
A few improvements to go, but from what I hear from other parents (without raising it) is that they'd take advantage of something like this.
It's designed to save organizers time and solve reg & timing problems I got tired of dealing with as a competitor.
Soon I'll be adding QR code support, so we can just scan a QR code on your helmet or car at lap (which helps handle multi driver cars etc).
I plan to rebrand it into other verticals later.
We are based in the SOMA neighborhood of SF and would love to help anyone with their hardware!!
http://www.iancollmceachern.com http://www.goldebgatemolders.com
My current tag line is "JS with guardrails, without footguns"
I built it because I was frustrated with how hard it was to manage a large number of channel subscriptions using YouTube’s default interface.
My algo often gets bad, and the best recommendations for YouTube videos come from friends' suggestions. And sometimes I just want to be recommended something totally different than what my algo would know about.
Would it be possible to add that feature?
Sorry, I don’t plan to add that feature.
Uses transformers.js & WebGPU for running transcription, so it's pretty fast. It's still a bit rough around the edges, so I'm looking for feedback.
What makes it different:
* Claude (and other MCP AIs) can both read from and write to your local markdown files
* Creates a connected network of notes that Claude can navigate between
* All data stays as markdown files on your computer
* When you chat with Claude, it automatically builds structure with simple patterns
* You can start a new chat and just say "Let's continue discussing X" without uploading files or copy/pasting
* Files are available locally, so you can edit them in and editor, like Obsidian, VS Code, etc.
I built this because I was tired of repeating myself to AI assistants and wanted my conversations to accumulate into something useful over time. It's basically a way to give Claude persistent memory while keeping your data local and be easily readable and editable my humans.
Some people are using it to maintain project context across sessions, document systems, and build topic maps without having to manually organize everything.
Demo video: https://basicmachines.co/images/Claude-Obsidian-Demo.mp4 GitHub: https://github.com/basicmachines-co/basic-memory
This is a tool meant for heavy users of ChatGPT who want to sync their *entire* conversation history to local markdown files. If that describes you, I invite you to check it out!
On the way, I developed lightweight image editor and 3D model viewer components, which I've open sourced [1].
Also, figuring out a way to visualise manhattan chart, score worm, wagon wheels etc using plain text ascii
[1] noscrypt - portable C cryptography library for nostr [2] vnlib - C# + C libraries for server applications, eventual high performance alternative to ASP.NET. It's really just a collection of libraries that are optimized for long running server applications. [3] vncache - vnlib cache extensions and cluster cache server over web-sockets [4] cmnext - self-hosted, vnlib based, json-file CMS + podcast 2.0 server [5] simple-bookmark - kind of deprecated, vnlib based, self hosted bookmark server
My software homepage (most up-to-date) https://www.vaughnnugent.com/resources/software/modules
I know most of yall will probably want GitHub links so here [1] https://github.com/VnUgE/noscrypt [2] https://github.com/VnUgE/vnlib.core [3] https://github.com/VnUgE/VNLib.Data.Caching [4] https://github.com/VnUgE/cmnext [5] https://github.com/VnUgE/simple-bookmark
Well I just put it live couple of days ago, now I'm just starting to post my own locations.
Had this idea when I wanted to take my drone out but didn't know where to go. And as a plus I really wanted to learn more about working with maps and geolocation for an upcoming project, so this was a perfect way to learn it and make something useful.
Would love feedback—especially on CLI features you'd find useful!
Free online database of all apps and their third party trackers.
I made an Android app that lists the trackers on your phone.
You can checkout that app by going to https://AppGoblin.info/about and clicking the link there. It is a test url for an open source ad tracking software. (ie track where an install came from, in this case the about page of the site).
Feel free to reach out if you're interested in either project.
The app will use genai to extract the details of houses listed for sale and then update my custom database.
For example I can input a youtube url and it will fetch the transcript and use llm to generate Json response based on predefined schema.
I can review and shortlist the houses based on various custom parameters using the web interface.
The mvp is done in a proprietary tech stack, I just need to port it to open source tech stack with React and FastAPI
On the frontend I'm rather happy with Angular but backend-wise I was never really happy. So it was time to build it. Been developing it for more than a year now.
Input: The website of a company. Any company. Apple.com or Ycombinator.com if you want.
Output: The verified email of every Apple/YC employee we've managed to find. Works for linkedin profiles too — put a linkedin profile in, you get a verified email out.
It's currently cheap as fuck ($10/mo) because it's a hacky piece of software. It doesn't work every time, but it gets improved every 48 hours so it'll be really good soon.
We're also teaching people how to hack sales and advertising, stuff like how to get a 30% response rate with targeted cold email. Basically everyone who's bought a subscription gets a lesson once per week. I've got 10 years of experience teaching skills, so in my opinion it's cool.
Join the discord server here if you want to talk about that: https://discord.gg/2RNwH8ta4A
If you want proof that I can even write an email as good as that: https://imgur.com/a/z9gNgGH
- Repairing an Apple II+. So far I've converted it to run on 230V and picked up the A2DVI to connect to modern displays. Next working on cleaning up the floppy drives and repairing the one that doesn't work.
- Reverse engineering the Tandy Z-PDA. I want to be able to synchronize with modern desktop Linux applications, and also eventually write my own PEN/GEOS applications for the PDA.
Got inspired by Go by Example [1] while learning Go. Realised there's nothing for Ruby like that and decided to build.
Goal is to have simple urls for one-click navigation for each topic where the page covers a single topic briefly with examples, with relevant links and historic artifacts (for example, it links to the "Programming with Nothing" talk in procs/lamdba page [3]).
It's still a work in progress and I'm not rushing it.
The examples are all my own. It's easy to do with AI, but I'm not going that way. I'm explaining things based on my own 12+ years of ruby experience.
Like GoByExample, this is also desktop only, but mobile-friendly is on the roadmap. The CSS also will change to be someting like RailsGuides. Might also add a video for each topic explaining the code.
[1] - https://rubyexamples.com/ [2] - https://gobyexample.com/ [3] - https://rubyexamples.com/p_and_l
It's an addon that allows one to modify any web page behavior. You can write rules for things like redirecting reddit to old reddit or keeping youtube videos playing in the background.
It's like Tampermonkey/Greasemonkey/etc but it works on HTTP request level and can modify scripts/styles/markup before they are ever rendered making it considerably more powerful.
Currently it only works on Firefox (and Firefox Mobile) because it's the only browser that supports the necessary APIs. It's seen its first release already but the UI is a bit lacking :)
AMO: https://addons.mozilla.org/en-US/firefox/addon/web-defuser/
Sources: https://gitlab.com/gear54/web-defuser
Example rules: https://gitlab.com/gear54/web-defuser/-/snippets
Now I'm learning AI/LLMs from the perspective of correctness. So far I have two 'maxims' to guide me:
- AI shines where humans struggle (for prompt engineering)
- An LLM is nothing but an API call (for software engineering with AI)
Here's a recent example of whats possible from one of our users [1], and a recent project I made for fun that you can try on your iOS [2] or Meta Quest [3] device.
[1]: https://www.linkedin.com/posts/matt-rice-sennep_mixedreality...
Is has helped me to address all of my problems, from mental health to productivity to learning across all domains like economics, writing, coding, marketing.
Writing daily blog posts, and then piecing together everything into the book. https://www.moderncynicism.com/
Currently heavily WIP though and only has a working Go compile/test backend (Go seems particularly easy for smaller LLMs like o3-mini to work with due to being a relatively non-complex language).
Clearly all of the info space is getting ever more polluted and I just don’t trust anyone else (with their own agenda) to manage and filter that for me. If one is to abdicate that sort of responsibility to a system wholesale then I think it has to be fully under one’s control, own data, own design, self hosted etc
As part of that, I made an ADIF (ham radio logs) parser to learn go. It's more than 2x faster than parsing the same data in json format with the go standard library.
https://github.com/Born2Root/Fast-Font
We also created some emoji fonts: https://github.com/Born2Root/Feature-Fonts
The final plugin is an equalizer which will be focused on loudness but expand the filtering to include more advanced equal loudness contours.
Also hoping to find some time to add a feature or two to my Video Hub App
https://videohubapp.com/ & https://github.com/whyboris/Video-Hub-App
Using `midiex` for Elixir I’ve written a fully fledged driver for Ableton Push, letting me use it as essentially a 4-deck version of Pioneer’s DDJ-XP2 sub controller with Rekordbox.
It implements basic statefulness so that the rotary encoders can be used, as well as a paging system so the 64 performance pads can be mapped to different functions. It also supports track browsing and loading, which is helpful if you want to use say DVS with an external mixer and don’t want to be hunched over a laptop dragging tracks around.
It’s also got some additional capabilities which I’ve not seen on other hardware like dedicated faders for stem separation levels.
It’s been a great exercise in combing two hobbies, learning about MIDI as well as being able to personalise my setup for my own use. I haven’t open sourced any of it just yet whilst I’m still tweaking things but I’d be interested in collaborating with anyone who also has one of these devices and has programmed it. I’m looking to use the display on it next, whose protocol Ableton have some (albeit scant) documentation for.
A long time ago I played around with neural net stuff and had some fun making tiny little things. To give an idea of time frame, this was before people were using ReLU.
Going back to it after the recent advances was incredible seeing how much has happened. So many times I'd see something and wondered how I could have missed it the first time only to realise it hadn't been invented yet when I did things last time.
It feels like there is a much higher focus on statistical mathematics now in a way that it permeates everything. That in itself requires a whole lot of new learning to get to grips with, but I also feel like there might be some value in looking at a lot of these things from a different perspective. I think I tend to look at things from a more geometric point of view.
In that vein I have been looking at some transformers using unit n-sphere embeddings with V values as geodesics, just to see what happens.
As I learn new things, I keep finding fun new ideas to muck around with, I'm just an amateur, so I'm not really restricted by areas I look at. Today I'm wondering about whether Wasserstein distance could be quickly approximated by a learnable method (especially if the inputs had access to parts of the ml components that generated the things being Wasserstein compared).
I'm almost certainly treading ground well explored by others, but my way of learning seems to be to rapidly jump between many different things picking up a small understanding of each as I go until I just seem to know things that I didn't before. Focusing on a topic and pushing in that direction never seemed to work for me so much. This is probably why I am an amateur :-)
This is a good thing. One requires smoothed pathways to run!
It goes beyond just plotting notes there are options to show scales using intervals, roots, note names, etc., plus a chord mode that highlights triads, voicings, and inversions. I’ve found it useful for routine practice start the built-in metronome, pick a voicing or scale pattern, and run through it in time.
There are also pages covering theory topics like modes and progressions, but the fretboard’s the main draw. It’s something I built for myself and figured others might get some use out of too. I plan to keep adding to it as I think of more things I want to reference probably adding support for additional strings or tunings next?
The other solves a very specific problem (mostly out of laziness) I do most of my playing using the standalone Neural DSP application on Windows, but I don’t really want to do any mixing in it. So I built a dead simple recording application [2] that doesn’t require firing up a DAW, but still offers a decent UX. It lets me quickly capture riffs and ideas, and later I can just send them to my Mac for mixing if anything seems promising. Haven’t shipped it yet, but I’ve been using it daily and having some friends try it out.
I think it's doable by dynamically creating lambdas based on test cases I define in one way or another, perhaps like mocked integration services, that does nothing but validate if the event from SFN matches a schema, and that the mocked response also matches a schema.
My concern is that I can't find prior projects doing this. My use case is mostly (exclusively at the moment) calling out to lambdas, so perhaps I can get away with this kind of type checking. But it's just weird that something like this doesn't already exist! Past experiences have taught me that if no one have tried it before, my idea is usually not that good.
Let me know what you think!
(Would have liked to use durable execution which totally solves the typing issue, but can't in this case)
Monokai Pro has been running for more than 5 years now for VSCode and Sublime Text, and the original Monokai almost 20 years.
e.g. you init a project (`obelisq init`) and use `obelisq set -k <key> -v <value>` (e.g. `obelisq set -k SERVICE_KEY -v ABCDEF`) to set your environment variables:
OBELISQ_PUBLIC_KEY=0344ecbf96c3e01262402247b97231a22c0197d17121dd9c7d1b999faed1d54ac4
SERVICE_KEY=047ca044c1a59114246d5c5122ad1bdecfafa3c999fae5629181df54[...]
MY_SECRET=049072d4ffc233ed77f8d682d9fe3a75114987d496b06d44269600e8be[...]
// `get` is type-safe, `mySecret` is number
// decryption of the value occurs when `get` is called
const mySecret= obelisq.get('MY_SECRET')
I was surprised that such a feature was not available on any existing calculators and so I wrote my own. Runs on macOS, iPhone, and iPad.
BVCalc Lite (free version, no ads): https://apps.apple.com/app/bvcalc-lite/id6544784034
BVCalc (paid version): https://apps.apple.com/app/bvcalc/id6560108221
I'm going back to school soon for psychology (figure financial aid can also pay room and board).
I'm wanting to build a mobile journal app with a bunch of AI guided 'games' to help learn DBT skills or work out trauma or do Shadow work or just guided CBT for a purpose.
I've changed my MBTI from intp-t to enfp-a...(I find I revert sometimes when I don't feel safe)... in other words I've become a very outgoing people person at least I'm a lot less afraid in social situations or to act like a fool on the dance floor... etc...
I also want to write a book and do videos on hacking your brain using AI... nobody seems to be doing this... there's a lot of potential for this niche I think.
I fixed hobbies, depression, and social life, all that's left is physical and financial and those are kind of easy when emotions are in check.
On March 31, 2025, Microsoft is officially shutting down the CodePush project, leaving thousands of teams without an alternative for OTA updates.
We took the open-source version of the SDK as our foundation and created a managed cloud solution. This allows both small teams and large enterprises to retain the functionality of CodePush with minimal migration effort.
Our roadmap includes further development of the project, launching a CodePush 2.0 version. In it, we'll deliver features that the community has long requested, remove legacy accumulated over the years, and adapt the SDK to modern development standards.
- A library for fast, accurate matching (geocoding) of UK addresses that uses Splink under the hood: https://github.com/RobinL/uk_address_matcher
- An npm library that generates maths mental arithmetic problems that align to the UK national curriculum, that can be used to power maths games: https://github.com/RobinL/maths-game-problem-generator
- A breakout maths game that uses the above: https://github.com/RobinL/maths-game-problem-generator
- Build dependency graph from dependency pairs.
- Generate the topological sort from the graph.
- Ordered parallel task sets (i.e. subsets of nodes that can run in parallel, within the overall topological order).
- Cycle detection and reporting the cyclical nodes.
https://github.com/williamw520/toposort
It's feature complete, but I still have problem publishing it as a library. Kept getting "unable to find module 'toposort'" error when importing it in a separate project.
Edit: Alright, finally figured out why the module was not published. The default project creation template in Zig 15 uses createModule() in the generated build.zig, which creates a private module. Switched to use addModule() to create a public module and my library can be imported and used by other projects.
I've been playing around with defining a standard that is easy to implement for serializing tabular data using the ASCII delimiters.
So far I've got:
<group> ::= GS | <record>
<record> ::= RS <group> | <unit>
<unit> ::= <high-ascii> | US <record>
<high-ascii> ::= 0x20 <unit> | ... | 0x7E <unit>
I also accidentally found another test that _all_ LLMs fail at (including all the reasoning models): the ability to decide if a given string is derivable from a grammar. I was asking for tests before I started coding and _every_ frontier model gave me obvious garbage. I've not seen such bad performance on such low hanging fruit for automated training in over a year.
Don't forget File Separator 0x1c
https://apps.apple.com/us/app/woor-vocabulary/id6740453162
Initially started as small webapp to help me learn Dutch words. Made it out of the frustration that in Duolingo I cannot specify the words I want to learn and Quizlet exercising and progression felt limited. I also wanted to target the specific meanings of the words.
Then I decided to try out CapacitorJS and wrapped it into the mobile app. For now only English is available as the target language as it was easier to validate the content, but more languages are coming.
Along with it also started the podcast with language tutors about the teaching & tech. Please find the links here: https://www.woor.app/tutorandtech
https://tendollaradventure.com
The book has been a fun endeavor in both writing the manuscript and code! On the latter, I wrote an exporter for Twinery to Org Mode and an Emacs Org export backend to do the reverse.
The book is currently open to beta readers - Happy to let a few more in through the sign up page here: https://tendollaradventure.com/#get-notified
I have an original Apple LaserWriter which I can use through the serial port (but it won't print). I've pulled the ROM's in it and got them working through the MAME game emulator. This is great as I can debug the 68000 code, for instance I was able to reverse engineer the random number generator and the password for internaldict. Ghostscript is handy as well although I try not to rely on it too much as there are some differences between the two implementations.
The plan is to keep it as close as possible to the LaserWriter so that means level 1. PostScript is quite interesting in that it starts executing PostScript code as soon as you power on the printer. That code is responsible for initialising the printer, handling errors, managing the serial ports then receiving and executing the incoming PostScript job. You can load and dump this internal code with a simple script.
The interpreter is complete along with the 125 programming operators, core types and error handlers. The next stage is the graphics operators. I'm going to target PDF for output as the drawing model is the same as PostScript. I'm assuming that handling the fonts is going to be the bulk of the work.
It's written in Rust, so far about 14,000 lines and 650 unit tests. In some ways it would have been easier in C as I could have followed the exact memory layout in the original interpreter however I really dislike C.
JavaScript works, scrolling - but layout is still being figured out! Also missing are form controls, etc etc.
It's meant to just be text (no images, etc) and to work in your terminal. It's NOT meant to alter/condense the layout to something like "reader mode" - just to be a faithful "GUI -> TUI" rendering in the terminal.
Like Lynx, but upgraded for the modern web. So maybe I'll call it Jaguar, but probably not! The idea is that other options like Brow.sh may be overcomplicated, hard to maintain, focused on a kind of graphical fidelity. Whereas this is more BBS style text only, but still usable. Minimum viable text, so to speak.
Leave your email if you want to know when it's ready to try out: https://tally.so/r/wbzYzo
I made a v1 about 5 years ago just for my daughter because I didn’t like any of the apps available. They were just games with a sprinkling of learning on top. She’d spend hours on there and learn F all except how to be addicted to dopamine.
So I made something very clean and very simple that we’d do together for 3 minutes a day. She learned to read really fast!
But… then I forgot all about it for 4 years, only remembering it when my second daughter needed to learn to read. She’s 3 and I taught her the first 26 sounds already.
At this point I wondered if it’d be good for other people so I contacted a phonics expert and they liked it too, so we spent the last 6 months making it into a proper app.
https://apps.apple.com/app/the-phonics-app/id6742649576
It’s going well so far. Lots of lovely messages from parents! If you have a 3-6 y old please let me know what you think of it!
I'm building the 2d parts of it in the GLFW library and modern OpenGL (this will eventually also be used as an overlay system when I get to the 3d portions of the project). I'm also adding in simple text menuing so I can quickly build text prototypes of the games so I can also be working on game data structures and basic mechanics while the graphical engine comes together.
So far I've started two basic games, an old school rogue-like on a large scale using tiles and a similar game that combines factory building with the rogue-like parts. I have plans to bring in some other games that will stretch different parts of the engine.
It's turn-based two-player game sorta like chess, but the pieces take up multiple spaces.
App Store: https://apps.apple.com/ca/app/kingbit/id1565583669
The idea is the app should be very easy to submit entries (entries can be small) as a way to get thoughts and emotions out of your head.
I want to focus on an interesting search functionality that aggregates entires into a single document about similar subjects.
1. https://www.oreilly.com/library/view/ai-engineering/97810981...
2. https://gist.github.com/blakesanie/dde3a2b7e698f52f389532b4b...
I think a better smart amplifier could be a good product -- and then people can bring their own speakers. Or you can make great wireless speakers and then people can bring their own amplifier. But the moment the speakers and amp become an 'integrated solution' I hear the e-waste bells toll in the distance.
People have been burned by sonos and don't expect their framework laptop to last more than a couple of years. Meanwhile my 25 year old dumb speakers are still going strong.
There are plenty of streaming audio amp solutions currently on the market - Wiim builds a nice one. But some of us don't want to run speaker wires through the walls for a home theater.
I've given a lot of thought to building a system that will work without a dedicated internet connection and this system won't require a central server to check-in to. I too have 25+ year old speakers that work just fine (Paradigm Titan's from 1998) and that's partly my inspiration. I wanted more sound from them but there's no way to upgrade traditional passive speakers. I don't want these speakers to be bricked if my company fails. They also don't need an app to work. The TV can control it through the eARC connection.
I appreciate your thoughts!
I'd love to make this a free/break-even service at some point!
At the same time I am exploring the boundary of my ability to think deeper
Thus writing a monthly newsletter that will span for 10 years. Right now it has a open rate over 70%
https://connectingdotsessay.substack.com/
Here are the essays
## Eight Grade syndrome - why grand narrative vision is killing your startup
If you think crafting a grand narratives of your idea is the crucial first step of building a startup, this essay is for you.
## Explorer Mindset - In a world where algorithms decide what we see, how can we rediscover the joy of unexpected discoveries?
If you feel trapped in a narrow view point, surrounded by the veil, and lack of creation muse, this article is for you.
## Why I show up everyday. The peddle, podium, creators and us.
If you are interested in why I started this newsletter and what I learned from it so far, this essay is for you.
Any feedback is appreciated!
Open source tools and art assets: https://github.com/swrpg-online
A quick repl.it one-shot UI using the monte carlo library: https://dice-pool-simulator-chrispan5.replit.app/
SWRPG Combat Simulator: https://swrpg-combat-sim.com/
Working on a frontend dice roller that utilizes the open source dice SVG files and rolling utility.
We could also stand to fill a slot in our online play group if you want to reach out! :)
I think it's interesting to think about how much something like that might affect the career of an athlete, especially early in their career or someone who is on the margin of getting into professional sports. Would choosing to play at a university that has a lot of natural handicaps be the difference between making it into pro sports? I wonder.
Anyway, I ended up making a page showing how much baseball teams in MLB have to travel this season: https://calcubest.com/sports/mlb2025 which I think does an OK job of highlighting how much less time athletes playing on central division teams have to travel.
Or getting real freaky with it by composing many effects deep https://shaderfrog.com/2/editor/cm1s7w23w000apar738s9d1x0
The backstory is that AI investments are proceeding, but companies seem to be struggling to get things into production, so the ROIs are beginning to slip. Where I have first party knowledge, there is a (small sample size) trend of businesses kicking off significant data modernization processes.
Most interesting to me, is that organizations finally seem to be figuring out that it is worth managing "information" for the business and "data" in their applications as separate work streams, and seem to be acting on separating those responsibilities.
Also, the biggest banks usually have the worst rates, this also goes for Kiwisaver, don't put your Kiwisaver with a bank, it'll do poorly compared to the lowest fee options we got in NZ. e.g. InvestNow (Foundation Series funds) / Kernel / Simplicity.
Still needs some work, like showing which rates are variable, or extra high risk.
Pretty quickly hacked together, to be very utilitarian, and practical. Don't see ever making money on it, made it more for me.
Bluesky API library spun off from the other project: https://github.com/tfederman/pysky
Haven't really started it yet, but a master list of RSS feeds and the code I used to source them: https://github.com/tfederman/huge-rss-list
And also a new project to fetch all links seen in the Bluesky firehose and gather metadata to build a database of sites and pages at a more granular level than the domain. For example, is account X posting video links from one YT channel or many?
Also, I just started on building a web application with golang that will make it easier for hobbyists to share their creative works (like manga, paintings, etc.) by providing a much better platform for their creativity to show. Right now it's pretty bare bones but it'll be a cross between myspace and patreon essentially. Main difference being the ease of use and the ability to showcase your work directly on the same app, without having to host your works on a separate service and promote it on another.
Lots of ideas, so little time to implement them.
https://cmringmaker.github.io/OKLCH-Picker/
https://github.com/cmRingmaker/OKLCH-Picker/
I was inspired by the article over at evilmartians[0] about OKLCH, and I loved their oklch picker. Decided I wanted to learn more about OKLCH by implementing my own tool that I've released this week. Had a lot of fun with this project, and am getting plenty of usage out of it already.
[0] https://evilmartians.com/chronicles/oklch-in-css-why-quit-rg...
In a past life I would have thought this would be the easy part given the product market fit but it's hard to figure out growth channels that are scalable and cost-effective at this stage. Burning what would otherwise be a large salary month on month in search of growth is mentally taxing when it doesn't deliver. Metrics across the board only seem to tell part of the story so it's tricky to figure out what needs changing and what's worth doubling down on.
If anyone has experience doing this sort of thing - please get in touch!
Starting with a native iOS app to to track and discover books [1]
Focusing on notetaking and cozy social this year as we try to grow from 100k to 1m+ users
Ive written a simple app [1] that crawls tech corporate sites daily looking for job postings, and sends you an email with the new jobs that match your profile.
The profile matching is currently very basic - just job title category and location(s). There is also a recommendation agent that is yet to be released (WIP).
I would be grateful for feedback and thoughts. So far I have personally (and others) found this to be very helpful in allowing me automate the daily checking of hundreds of sites.
You can also add specific companies to the crawler, which is nice if you are passively looking at specific companies. A possible feature addition might be to limit the search to only pre-defined companies that interest you.
I would appreciate any thoughts and feedback.
Not a "text editor" for code and whatnot, but a real-deal word processor for writing novels and such. I cloned Visicalc (onto the Pico-8), so my "How does a spreadsheet work?" itch has been scratched. I think it's finally time to answer for myself, "How does a word processor work?" (in pure C, to level-up those skills as well) So lately I've been working on small programmatic experiments to understand the underlying subsystems necessary to build one.
I had a daughter almost 2 years ago, and for a while I didn’t have any free time. But once I started getting a few hours in the evening, I wanted to start up side projects again. I found it frustrating to work on coding projects in 1-2 hour windows. But writing is a little easier; I feel like progress is a little more linear with writing, and having the Monday/Thursday deadline has helped me just ship.
When devs put their top languages on their resumes, they are also saying a bit about how they prefer to work and what they value. This signal is largely lost on HR since a lot of it is insight you get from actually coding over time. I strongly believe that we can get more people hired and into the right organizations and cultures if people could see beyond the surface level of the keywords on a resume.
I'm looking for first customers now and people to give feedback on the idea and the upcoming offerings. There's a proof of concept now that hints at how it all works.
The idea is to be able to ingest your logs locally and run queries against them without having to resort to a hosted prod-like environment. It's all focused on localdev-first experience. I use it when the o11y tools at work don't do what I need: I can just pull the raw logs locally and run my queries there.
It's still very rough around the edges but it gets better day by day. I want to add features like alerts and monitoring, metrics and tracing. A full o11y platform in a single binary with zero config. I would love any feedback.
(Also please excuse the poor onboarding experience, I haven't polished it as this is a side project and I have a day job)
SaaS - I'm working on this https://prfrmhq.com - see https://news.ycombinator.com/item?id=43538744 [Show HN: My SaaS for performance reviews setting goals and driving success] - Shows I can use AI and I've integrated into AWS Bedrock - Shows I can integrate with Stripe for payments
Consulting (Architecture, Strategy, Tech) - I'm working on getting my consultancy running but the market is hard atm. https://architectfwd.com
Next SaaS - Starting a SaaS for managing core strategy and tech concepts
Mortality is so hot right now so why not celebrate with a custom urn to enjoy your journey into the spirit world in style.
Recipin: https://recipin.com
Private recipe archiving/bookmarking. No ads, no AI, no javascript . Join a server or host your own (https://github.com/bradly/recipin). Screenshot: https://raw.githubusercontent.com/bradly/recipin/main/public...
Just shipped the first phase of v2 which lets you navigate Nix store objects.
Give it a spin here: https://v2.mynixos.com/nix/store/16s8kjwv6zz7xyv3hjr890n7v0d...
(Adjust settings in the upper right corner menu to control what is streamed).
More info here and in FAQ on front page: https://discourse.nixos.org/t/mynixos-v2-release-updates/622...
It's mostly feature complete at this point, but there are still some rough edges.
Notion's API is far from complete, and updates are few and far between. This has led me to work around some of its limitations in creative ways. For example, there is still no way to create top-level pages in Notion, which makes restores impossible. Instead, I ask customers to create a top-level page themselves and write backups there.
Personally, the hardest part of working on a project for an extended period is not getting burnt out repeteadly. Sometimes it helps to work on something else, and other times you just need to step away from the game entirely for a while
I also had a recent blog post [2] do fairly well on HN, and now I'm kinda thinking about a new design for version 2 of that project because I can't help it I guess.
[1] https://victorpoughon.github.io/torchlensmaker/
[2] https://victorpoughon.fr/i-tried-making-artificial-sunlight-...
At the moment, I've been doing very little. I had been hyperfixated on going "above and beyond" at work, doing close to 60 hours per week when I was only getting paid for 40 since January. I had been hoping that if I had been putting in an excessive amount of effort in terms of productivity, I would get some recognition for it, and more importantly: be given the opportunity to work on professional development things, in terms of, say, classes or training so I could learn more about automated testing. I really want to move towards something more intellectually stimulating the grinding manual process we have - I see so much room to improve. I really just want to learn more things, so I can become a better asset to the my employer, and so I don't feel like I'm just "treading water" in terms of industry knowledge.
Instead of things going that way, I was basically told that doing what I had been doing is... appreciated... but doesn't really change anything, because no one had asked or expected me to do it.
It was demoralizing to get the brush off in that way, but I've decided the best course of action then, is to forge my own way. Do the hours I'm required to do (and do them sincerely well), but put that creative hunger into building a website, building some repos, and finding my own way forward.
At this point, I've already bought a domain. Now I just need to figure out how to build one, and start making some cool stuff.
Its hard to set tone through text... I'm not bitter about what happened, everything they said was technically true. Heck, I'm not even angry about it. It was naive of me to get my hopes up thinking I would get my way, if I put in the effort up front. It just feels... bad to not really feel any kind of positive reinforcement for professional development, or even for working as hard as I’ve been working for the past 3-ish months. In fairness, what they said isn't unreasonable, but it sucks they don't want to invest into me, the way I invested into them.
It's still very heavy in development but the gist is: Say you have a cool idea for something small you want to automate or run - instead of thinking about hosting, workers, lambdas and what not, you just open microfn, open the editor (or the function generator), write your function, hit save - done! All the complexity is tucked away on microfn, and your place of use just has to authenticate with microfn and nothing else. We run it for you and keep you productive.
Now you can use that function from anywhere: From the terminal, periodically with a cron, add it to an AI agent as skill, use it through an MCP (not released yet), through Siri shortcuts, share it with your friends and so on.
Say you want to have an agent or function that gets the weather and sends it through Telegram: You can either quickly generate 2 functions through the AI function generator that get the weather ("I want a function that gets the weather for Tokyo") and another one for sending a message on telegram, or you can use what's already available (such as https://microfn.dev/david/getweathertokyo). Equipping them to an agent works like in a video game - each function is a new "skill" or "tool" the agent can use, and if someone else already has some cool skills, you can fork them without needint to re-implement everything from scratch.
So like a toolbox full of small composable hammers and tools that can be used across different scenarios and places, to be plugged into existing workflows, automation or to even be used in autonomous agents and through MCP.
Again, super heavy in development and not really a 1.0 yet, more like an early alpha, but wanted to share here anyway. Feedback greatly appreciated!
Exporting book highlights from a Kobo was slow and inconvenient; you’d need to connect the device to your computer via USB and run a script, or upload the onboard sqlite database to a website to extract book highlights. With Highlights.Email, you tap a button on-device and in a few seconds have a nicely formatted email with all your book highlights!
So, I’m just scratching my own itch mainly while learning how to build and launch something to the world. There’s two parts to this service: Rust program that runs on-device and a SveltKit app (w/ a Supabase backend) for auth and sending emails.
I suppose I'll post the link someday. I literally just started today.
The goal is make it easier for organizations to work with external parties that affect finances (customers, investors, vendors, etc.).
The idea was born out of personal frustration that I've faced in a variety of leadership roles in organizations, that lead to wasted effort, slower decision making, bad decisions made with equally unhygienic data.
I've solved this successfully in the past form of internal tools and a data governance layer (data warehouse with much more authority).
It's quite a mess as we have to aggregate multiple data sources that come with their own timing and sequence issues - plus we are seeing massive adoption so resource usage will be interesting for v2.
The plus side is that building massively parallel and redundant services in Elixir is, if not actually fun, at least more feasible than in other environments.
A library that procedurally generates datasets for training reasoning models (like o1/r1) with verifiable rewards.
It's a log management/processing software, with visual scripting.
Started out of frustration towards OpenObserve and its inability (at the time) to properly/easily refine/categorize logs: we had many VMs, with many Docker containers, with some containers running multiple processes. Parsing the logs and routing them to different storages was crucial to ease debugging/monitoring.
It was initially built in Go + HTMX + React Flow encapsulated in a WebComponent, I then migrated to React (no SSR). It integrates VRL using Rust+CGO.
It is by far easier to use than Logstash and similar tools, and in fact it aims to replace it.
Contributors are welcome :)
It's been tricky but interesting. VST plugins are basically packaged as DLL files of Windows COM(-ish) objects. Despite primarily being a Windows dev myself, I never worked directly with COM libraries or objects before. My app is written in C#, and .NET does have built-in "COM Interop" support, so it is possible. A few years ago, .NET added a new COM Interop Source Generator system [2, 3], and I'm trying to get it working with that. So far I've been making some progress, but it's still a lot of tedious work to setup.
(There are libraries/packages out there that implement VST in .NET already, but they mostly focus on plugin creation while I only need hosting. They're a lot heavier and more capable than I need. They also didn't use the newer Source Generator approach, so I figured I'd give it a shot myself.)
2. https://learn.microsoft.com/en-us/dotnet/standard/native-int...
The problem that I'm trying to solve is that when you are writing a lot of content as a team you often lose track of the state of things because it is passed through email or google docs (or whatever). People tend to manually manage these types of projects with spreadsheets or trello or whatever, but that means that you are manually updating the status.
Vewrite has an integrated editor and a workflow manager, meaning that as you progress through the workflow while doing the actual work, your project management status is constantly kept up to date, too.
The goal: minimal input, fast turnaround, and results good enough to use on LinkedIn or resumes. Currently experimenting with ways to reduce training time and improve accuracy with as little as 5-8 images. Also exploring automatic gender/style detection to optimize prompts while keeping everything privacy-friendly.
Would love feedback — what would you expect from a tool like this? What features or improvements would make it a no-brainer to use?
We are in open Alpha at the moment, but plan on offering affordable plans while keeping the source code available. While in open Alpha and during the upcoming Beta, it is free to use for any purpose.
We will be selling Fair-Source license, meaning that the source code will be released under MIT 2 years after release.
Check it out here: https://github.com/DelveCorp/flashlight/
Feel free to ask any questions here or open an issue in the repo.
Recently added a free tier, so working on making sure both the free subscribers and the paid ones get value out of it. I've asked people to pay for my time as a consultant and books I've written in the past, but it is pretty scary to ask folks to pay for my knowledge via a newsletter.
Finding the balance between technical dives, standards reviews, interviews, and CIAM use cases while doing this as a side hustle is an interesting balance as well. And, the weekly cadence can be brutal. But it does keep me on my toes.
this weekend specifically, setting up an in-house assembly area. decided to renovate my barn and be our own fulfillment center.
[1]: https://trmnl.ink
- Adding support to WhatsApp/Discord/Signal bridges to Communick's Matrix server. For some reason, last week I got a handful of handful of customers saying that they would be willing to pay more than the $29/year of the standard plan if they could get those bridges on Communick's Matrix server
For some clients, electronics for a low impedance guitar pickup (pick up all the signal then process it later instead of building in filtering to the pickup).
And an automated design app that turns a 3D model from Fusion into something that's easy to change the parameters on. That way people can easily just type stuff in and move on to manufacturing. This started for staircases - for companies that make like 20 sets of wood staircases on site every day they want to turn that 1hr of drawing into 60s of data input.
You can create patterns, play those patterns on a specific beats, add melodies(HTML tables of notes!) with lyrics, add chord changes to determine how the patterns are played, etc.
It's meant to be CAD-like, so you're working as high level as possible, not looking at some raw notes and having to go look up what chord it is every five seconds.
There's plenty of features that don't exist but look like they do, but it does work.
I'm happy to say I'm no longer stuck on endless little business logic decisions. Now I'm mostly stuck on essentially creating a (more) complicated google calendar interface. (React + MUI) I stopped work when everything was still wonky but i could quickly make appointments on the fly with it. A few days ago when trying to wrap my head around my own code i kind of regretted that decision. It's a bit more complex of a UI piece than what i've tried my hand at before and my current holdup is (re-)implementing proper drag & drop to edit appointments after i rewrote a piece of the underlying stuff.
https://marketplace.visualstudio.com/items?itemName=Ridvay.r...
The focus is on providing a better experience: faster, with smoother interactions, with higher information density and a lot more focused on your daily work (with features such as bookmarks and drafts).
It's web-based but there will be also desktop apps (thanks to tauri) that will integrate with your local git.
If you start using it and want to ask for feature requests or notify bug reports please go to the discord server: https://discord.gg/RHCJvUSbr5 Thanks!!
Why I think it's good: deferred deep linking has become an also-ran feature for MMPs whose primary focus is tracking users and advertising.
It's so bad that I can't even open deep links for Tiktok on my home network, because onelink links are blocked by adguard.
So that's why I built DLN. It's brand new and open for beta testing, I'd love some feedback and feature requests + to know how people use deferred deep linking.
1. Support on-device RAG to allow chatting with your own documents on mobile offline 2. Support MCP on-device, taking advantage of information that’s (only) available on your phone, like calendar events, health data, etc. These shouldn’t need to be anywhere but on-device. 3. Allow on-device AI to use shortcuts(?)
I think most of the functionality are well served on desktop front with Ollama and LM Studio, but moving these functionality to mobile offers a great learning opportunity.
You can choose from common difficult scenarios or create a custom one and get connected with a conversational AI voice agent to practice. Started out with just manager use cases but now testing out sales calls, interviews, pitches, etc.
Mostly built on Replit (would recommend - is amazing & keeps getting better) and relying on a mix of ElevenLabs / OpenAI / Anthropic for the voice & LLM tech.
I’m sure many of you were asked to engage with some product announcement, hiring post, or whatever on LinkedIn. With SocialWeaver, we remove all friction from that process by letting employees like, share, and comment directly within Slack and Teams. On top of the core use case, marketing teams also get analytics, employee leaderboards, content scheduling, etc.
https://apps.apple.com/us/app/japan-top-100/id6741251616
Only public on iOS store for now, due to Google requires larger # of testers to authenticate the app.
This app idea came from my last Japan trip. I had a hard time finding good local restaurants (not tourist traps). So I decided to build this app with Japanese-oriented lists, due to lists' lacked of maps, etc. The app actually helped me discover some great spots, since it lists places all over Japan. Please give it a try and let me know if you have any feature requests or ideas.
After using tools like Sentry on apps serving millions of users, I always felt I was missing a cheap and dead simple approach to following what happened in my apps and apis, and basically became my first customer for all of my side projects and even got some friends using it for their SaaS and apps.
HN is probably not the target audience for this, but I've become really obsessed about solving my own problem of building apps, but struggling to market them. There are very few places online that welcome you to post links, enable you to post a link quickly, and drive targeted traffic at reasonable cost.
So I'm trying to bootstrap a new ad network on Link In Bio platforms that offers this trifecta (welcoming, quick, cost effective).
Motivation for the project:
> This project was born out of the need for a lightweight analytics tool to track internal services on a resource-constrained VPS. Most SaaS analytics products either lack the scalability or exceed their free tier limits when tracking millions of events per month. Minimalytics addresses this gap by offering a minimalist, high-performance solution for resource-constrained environments.
I recently did a Show HN which you can find on my profile.
For whoever aware of recent `tj-actions/changed-files` security incident, I built a mutable-reference scanner that performs a deep scan across branches to identify all third-party GitHub actions used in organization Git projects. The output report can be exported to CSV or JSON (default).
Using mutable references (version tags, main/master/dev etc.) is a security vulnerability that can result in supply-chain attacks.
Project link:
Recon Wave basically finds and scans all their services - DNS, IPs, Apps, Ports - and notify customers when it breaks some policy (aka. "no ports than 443 should be open") or when some service is straight vulnerable.
I'm former security engineer and I hated all that "critical reports" that reported missing CSP header.
We're now playing with an idea to build LLM pentesting agent that could run agains the whole infra of our customers.
What we build is primarily focused on companies that have at least hybrid stack - some on prem, some in cloud. If you completely behind load balancer and have strict change management, we can't bring you any value.
In ideal world, we wouldn't have any business. But oh boy... Companies host wild stuff.
Every single conversation I had with clients ended up with us showing some of their infra and the response was "wow, we didn't know this is ours".
Said every security company ever. :)
YAML is prone to typos, TOML does not seem obvious to me, and JSON is not as easy to edit.
I've been designing CLEO:https://code.nicktrevino.com/cleo/
The focus is on a configuration language that a single application would use. Not a system-level configuration that might need control flow, etc.
It is at a solid state right now, though it's not officially released yet as I slowly validate it with usage.
I've always found it useful to have scratch notes about whatever's on my mind -- a mix of journaling/reflection, planning, project ideas, notes on things I'm reading, etc. But I wanted to be able to chat with an LLM that has full context & memory from these notes.
It's been surprisingly helpful for me and some of my friends! Some ways I've used it:
- Talking through fuzzy ideas & ideas to clarify them
- Having it re-inforce the healthy habits I want to build
- Using it to reflect on feelings or whatever's been bothering me
The end goal is a community-focused study/prayer/chill sound generator for an Orthodox Christian audience
I'm looking for co-founders to explore monetization routes. Feel free to reach out.
I found I was liking/bookmarking insightful content on X I rarely saw again and wanted a way to resurface them somewhere I would see multiple times per day.
Can import from X via share sheet or manually enter them. It's minimal, but I've found having:
"i hate how well asking myself "if i had 10x the agency i have what would i do" works"
there every time I unlock my phone, was worth the development effort.
If a domain is taken, it shows full ownership data with great UX — not just a raw JSON dump. Clickable links to social profiles, business info, tech stack, DNS records, and more.
Built it to streamline my own workflow for naming and branding projects. Still early, but already saving me time. More features coming!
- Uses an encrypted badgerdb to keep track of metadata - Uses rclone (with an encrypted backend) for file storage in s3 or any backend rclone supports - Automatically indexes and generates video thumbnails and transcodes to webm to be streamed in the browser - Slideshows - has a fairly decent ui that doesn’t look like it was developed by a backend engineer
The goal was to be able to attach my own s3 storage and keep all data encrypted at rest. It’s written in go and deploys as a single binary.
But for real, I've also been working on large-scale photo/video management, and the question of where to keep additionally metadata has bothered me. It seems right to want to keep it "in" the file, and so I want to write it into EXIF, or even steganography, or something.
Generated voice profiles (you can use "AI" to sell it to your bosses) to narrate text messages in the sender's voice. Many texts are already sent by speech to text, why not carry that voice to the reciever? Simply recording is not ideal due to the background noise and extra bandwidth, so regenerating the speech on the reciever side seems to be the better approach after generating the speech profile from some sample of initial messages.
I'm anticipating a really sweet perf increase (as shown by some proof-of-concepts), but now that everything is actually working on the v2 branch, I'm putting together benchmarks that show the benefit in practice.
Love to have anyone poke around/ask questions/hang out on discord.
This came about because of how awkward Cloudflare Tunnels is to use in a development environment.
It supports multiple currencies, VAT tax deductions, and lets you download PDFs in multiple languages (English and Polish for now, with more coming soon). You can also share your invoice by clicking “Generate a link to invoice” button.
Try it out: https://easyinvoicepdf.com/
Check it out on GitHub as well:
https://github.com/VladSez/easy-invoice-pdf
Would love to hear your feedback =)
https://github.com/rahuldshetty/reader-project/releases/tag/...
The video here best shows it off. The source is available and free to use for non-compete, personal use.
https://bsky.app/profile/davesnider.com/post/3lkvum6xtjs2e
Mostly a labor of love. I don't expect there to be a super large audience for this one, it was just something I needed myself.
https://play.google.com/store/apps/details?id=com.bingeclock...
https://github.com/paulmooreparks/Xfer https://github.com/paulmooreparks/Xfer/tree/master/ParksComp...
Doing it completely solo — built the product, run the ads, do the outreach, everything. Struggling with sales now. Thinking of narrowing focus and solving a more specific pain point.
Curious if anyone else here is grinding through early-stage B2B SaaS — would love to hear how you're tackling this.
IdeaFunnel - capturing, tracking and evaluating ideas in organizations; as innovation is topic that I am conducting research in and will be teaching a block course in July on. (Being rapid prototyped in PHP.)
ltools -- a set of command line tools in Rust.
Also starting a new multi-year computer science book project...
https://gitlab.com/harford/xflog
I've also built a tool in Rust for munging ADI (amateur radio contact logging) files:
https://gitlab.com/harford/adifsurgeon
After being laid off, it's given me lots of time to play on the radio :-/
The tool just does one thing "Keeps your docs upadated always"
Why am I trying to solve this?
I have dealt with the pain of keeping the docs updated. It is mundane and boring at times. so I wanted to check if the pain is universal.
I need the fourm's help to solve this, please take 30 seconds to fill this survery that will help me with some cricital insights around this problem:
https://app.youform.com/forms/apmvipej
happy to help you in any way possible in return
March was quite productive:
* there was major (somewhat breaking) upgrade to the language
* We have a working web (wasm) console again
* full binary builds with some improvements for Windows that before didn't get much attention.
* full function reference with unit tests should arrive soon
I try to post about what I'm working on on Rye's reddit group:
I am also working on Plundrio [2], a put.io Download Client for *arr.
My other project Server Radar [3] has been neglected lately, but I wanna move to D1 completely (currently still using DuckDB on the frontend).
I think this can be really useful as it allows you to maintain separate QCOW2 files for each investigation, since they can be generated in just a few seconds.
Using a Nix Flake also provides an easy way to add or remove tools, offering extensive customization based on your needs.
There are other similar tools out there—mostly web apps or CLI-based—but I found a VSCode extension to be the fastest and most convenient option for VSCode users.
Here’s the extension link: https://marketplace.visualstudio.com/items?itemName=H337.c2p
I'd love to get any feedback.
It is going pretty well, already 17k users signed up. There are many people using it daily which give me the motivation to continue working on this.
I just wish I had more time to spend on this instead of the boring CRUD app I work on for living.
As long as you don't need many advanced spatial functions (where PostGIS shines), and you make sure to minimize the use of GDAL to perform operations, it parallelizes processing quite nicely (most queries on large datasets saturate as many cores as you throw at it).
https://bsky.app/profile/jordanmorgan10.bsky.social/post/3ll...
I don't know which one I will actually implement, though.
https://www.inclusivecolors.com/
I use it myself for making branded palettes for projects because it gives you full control over the hue, saturation and lightness curves (instead of these being mostly autogenerated), and it helps you make tint/shades for multiple swatches at a time that go together (rather than a single swatch at a time).
Get in touch if you have any feature requests!
https://wohlben.github.io/factory-fractals/recipes/75?target... It's not really optimized for mobile though, and I actually forgot to give mobile users the recipe picker.
And there seems to be a strange bug only with the rare quartz recipe (it thinks it'll provide 1/4 more items then it does).
Did it also to learn rust, which made it easy to convert the engine code into webassembly and create a hand score calculator for the game :)! https://cerpins.com/mahjong-tool
Plans now are to finish the client, then freshen up the calculator with some QOL and visuals, surely a bug fix might be needed here and there as well.
I quit my job a couple years back to work on this app full-time, as well as its companion flashcard app, Manabi Flashcards. The goal is to help you learn through immersion.
What's special about it? Manabi Reader became popular as an Japanese-focused alternative to services like LingQ in that it locally tracks and analyzes all the words and kanji you read and study. It shows you which words are new and which you're currently learning via flashcards, so you can easily find content that suits your level and see what flashcards to prioritize adding. It also passively accumulates an on-device (and in your personal iCloud) corpus of example sentences from your reading.
I had built this part-time while working over many years (starting with flashcards and then the reader app) but going full-time gave me the time to do a full rewrite: SwiftUI, native iOS + macOS, and an offline-first architecture that syncs with iCloud and my server in the background.
Although it has a companion SRS algorithm (SM-2) flashcard app, it's also excellent for mining Anki cards. This works with AnkiMobile on iOS and AnkiConnect on desktop.
You can use it like a web browser for the web, or subscribe to RSS feeds. It comes with a bunch of curated content by level. Recently I added EPUB support, pitch accents, and note-taking with todos.
I'm now almost done adding a manga mode via Mokuro.
Next I plan on adding more media types (video, YouTube, PDFs), AI functionality (grammar explanations, document Q&A, etc), Yomitan/Yomichan dictionaries for bilingual/monolingual EPWING and Wiktionary support, and more service integrations such as 2-way sync for WaniKani, JPDB, and existing Anki decks. I've begun work on these items and hope to share more soon.
I'd also like to make this app much more beginner-friendly so that people with zero Japanese knowledge can start learning. Currently it assumes you can read kana at least.
Previous discussion [2023]: https://news.ycombinator.com/item?id=36674259
We're offering online memberships, event management, and a member database packed with features. Membership management is a crowded space, but it's also a low-tech space with lots of sleeping giants not willing to iterate on their product.
It's been a really fun project so far and even more rewarding to see clubs using embolt for their daily operations.
So far I've built stuff like automatically created and advanced tournament brackets with group stage, match schedules, participation queue and achievements. Not that hard, really, but helped me get into the backend side of web-development.
We currently organize 2-4 events each weekend for 300 people of different skill levels.
So far it's exclusive for our small community, but I'm thinking of offering it to similar groups of people in other cities.
vimgolf.ai
Right now, only has two levels but I soon plan to add all the Vim motions and use reasoning models as bots that start off the level with you. Apparently, reasoning models like o3-high, Claude 3.7 thinking, and Gemini 2.5 pro are good at finding new ways to transform files using Vim. Kind of silly to have them do that, but I find it kind of cool.
I've been working on a new software product (native Windows) that is for analysis of SQLite databases. It's geared towards non-technical and slightly technical who may not know anything about SQL. The software includes an ER diagram, ability to browse table data, query building, and charting (bar, column, histogram, line, pie, scatter). Trying to get it finished up so that it can be released (hopefully in next few weeks).
Working on In or Out. Anyone with Elixir Phoenix experience are welcome to help with the project.
Side project for Fantasy football offline drafting. We aren't allowed any electronics just up to date print outs. However drafting takes forever with stickers. I'm making a Elixir Phoenix liveview app to replace the board and player picks with timer and fun prizes.
The goal is to build a discovery system/algo that surfaces stickiness and fun to give developers a tighter publish/iterate feedback loop so they can really hone their craft on a shorter time frame.
If you have a prototype of a game that can be hosted as a static frontend web rotting away in your "projects/" directory feel free to toss it up on the site. Bugs beware :)
High quality translation requires context. Mainstream translation apps (Google Translate) guess based on probabilities based on what the user would commonly mean, but this can results in confusing translations.
It's a collection of small tools that run locally in your browser which, over time, I've built to serve my needs mostly. This has been living on my home NAS for a while. When I created the flashcards maker to help my 10 years old son prepare for a Spelling bee word quiz, it became popular with his schoolmates and I got some new drive to make it public.
It includes rolling correlation charts, hierarchical clustering, and a terminal-style interface with high data density. It uses a 2D windowing/virtualization approach to render only visible matrix cells to the DOM. It's early WIP. The landing page is particularly bad.
It currently just has my portfolio that I use (Innovation and Global Growth) and some other generated ones. I wanted to try out SvelteKit and Svelte to replace my Google Sheet into something cooler. Not sure if I want to monetize this.
https://rumca-js.github.io/music
https://rumca-js.github.io/search
Most language apps make you select whole words rather than type, so I made an app that focuses on text first
It's helped me find the letters on the keyboard much quicker and rattle off common responses
Check it out! Would love your feedback
Focusing on training and fine-tuning, because of lower bandwith requirements.
We're collaborating with a few AI researchers through offering a sponsorhips program for the right people. If you know anyone, send them our way.
PS. If anyone has experience with Marimo, give me shout!
I've been working to time an update and demo release with the Steam City Builder & Colony Sim fest: https://store.steampowered.com/app/2769820/Trappist/
At the moment, I am validating demand for Rank And File, a platform for employee activism. Think Institutional Investors but instead of suits, it is employees who own a large number of shares in their own company and act as a collective.
R&F aims to provide a private forum for employees to discuss company policies and act as a platform where employees can connect with legal experts and activists who will help them
It is designed for users who want to create interactive animations on their websites without the need for coding, making it easier and giving more precise control of the animations.
If you are a web developer and think you will be a good beta tester, then fill out the beta test form on the website.
+hint system for when players get stuck
+swipe navigation for easier moving
App Store: https://apps.apple.com/app/mummy-maze-pocket-edition/id67381...
Google Play: https://play.google.com/store/apps/details?id=io.itch.ksylve...
Now I am building into it some features so other people can help me to run it, such as ticketing system (with AI), and statically generated copy of the site to improve availability.
I am also working on a service management tool, based on USM method. USM method is kind of "open source" version of ITIL, although it works on a different level than ITIL.
If you know of a webhook provider not in my list - https://webhooks.fyi/docs/webhook-directory - let me know and I'll make sure it's added.
It generates interconnected learning documents, a bit like personalized wiki articles. Features include courses on any topic, generative flashcards for spaced repetition (think Anki), as well as a chat alongside each document.
Would love to hear your feedback!
I started the project 1.5 years ago after many people I spoke to expressed interest, but life got complicated and I had to focus on health among other things. It's now back on the front burner, and I'm hoping to launch it later this spring or early summer.
It's a double entry based personal finance tool, to help families and individuals, track, understand and plan their finances.
It's local first. Synched across devices via a sync server. Financial data is encrypted before it leaves your local devices. By design, we don't have access to your data.
We are still in early phase, and looking for active users, and their feedback.
to make DXFs and G-code:
https://github.com/WillAdams/gcodepreview
The next big step is a house-cleaning one, need a vendor-agnostic system for numbering tools:
https://forum.makerforums.info/t/what-tooling-are-folks-usin...
Been learning a lot in the process: brushed up on trigonometry and so-forth using _Make:Geometry/Trigonometry/Calculus_[1] and various other books, some of which I am still reading through; lots about programming, esp. useful was John Ousterhout's _A Philosophy of Software Design_[2] and the next stages are Bézier curves/NURBS, a system for single line fonts (which may get extended into an interactive METAFONT programming system), and a mastery of conic sections _and_ algorithms sufficiently efficient that the 1" x 2" x 1" test case which took ~18 minutes to calculate on an i7 and which generated a ~127MB toolpath file can be done a bit more reasonably.
The big thing it makes me thing about is whether I should try to get a Master's and then go on to get a PhD (but that's a hard sell w/ the finance committee when I'm 59 and still making house payments).
1 - https://www.goodreads.com/book/show/58059196-make https://www.goodreads.com/book/show/123127774-make https://www.goodreads.com/book/show/61739368-make
2 - https://www.goodreads.com/book/show/39996759-a-philosophy-of...
Ended up having to write a decent chunk of C using FFI mind, no wonder people write SSH servers in Go/C, and why every AI tool told me it's really difficult and shouldn't be done :D
Bit of fun though, and I know more than I would ever want to know about the SSH protocol now!
Today, it generates clean, formatted product requirements from natural language and includes templates for different use cases (bug fixes, usability adjustments, etc.).
Soon, it will use RAG to incorporate knowledge of your system into the product requirements and perform inference on key down to help product managers write better specs with AI.
This web app is an off-shoot of a command-line archiving tool I wrote to scratch my own itch.
In its current form it's tripped up by bot detection and often struggles with heavyweight pages, but it works on enough pages to be somewhat useful.
Archived pages aren't retained long-term, but you can download them as static HTML files. (So kinda like a hosted version of SingleFile.)
Hopefully getting Smart Communications to hand over my USPS Mail they blocked while I was in jail. I never agreed to the Terms and Conditions of Mailguard. That doesn’t mean I forfeited my rights. Hopefully some prisoner advocacy groups respond with guidance on what happens next.
1. User on allow list forwards suspicious email to service directly from their inbox. 2. The email is parsed, opened, and sanitized in a sandbox environment. Attachments are scanned into raw pixel data and then converted to PDF. 3. Reply email with sanitized content is sent back to original sender. 4. Server is rebuilt, forgetting all previous jobs to protect privacy.
Will be working on some LLM features soon (explain "X" in the sentence "Y" prompt). It'd be nice to get a word frequency ranking dataset integrated, so I don't waste time learning rare words.
I launched the kickstarter a month ago and am currently finalising the logistics for shipping the books out and putting together the shopify site which should launch at some point in April.
It records your sessions and is configurable with Janet, a Lisp. I'm having a lot of fun with it! (It's also the only thing I ever seem to post about on HN, heh)
I've been hacking on a similar idea since about 2016 but only recently picked it back up. I want to support walking and cycling - any activity as long as it's outdoors (no treadmills).
I have a few ideas about the narrative that I think should be fun and timely.
We don’t want to put ads in the game, but we’re exploring ways to add non-free features to make a little money from it. Has anyone done something similar? Any insights or past experiences with monetizing a casual mobile game would be really helpful!
Still a lot of features to be added, but it's already useful for simple use-cases.
Google Firebase mobile client https://apps.apple.com/us/app/littlefire-firebase-mobile/id6...
spat is a Redis-like in-memory data structure server embedded in Postgres. Data is stored in Postgres shared memory. The data model is key-value. Keys are strings, but values can be strings, lists, sets, or hashes.
It's still alpha, but it works.
Also, writing a Masters thesis on area-level and individual-level predictors of breast cancer... so a lot of applied ML.
Hope to launch it soon!
Currently adding the ability to pause checks on a schedule (for when you have scheduled maintenance on your DB and don't want alerts during that time).
LuaCAD is a scripting library which uses OpenSCAD as engine to create 2D and 3D models. The OpenSCAD language itself is quite limited and has several issues and Lua is much better suited for the job!
So if you're interested in programmatic CAD, please check it out!
Here's a demo (click on "Limiting Reactant"):
I was quite frustrated with how the original devs handled monetization going into open beta, which sparked my motivation.
Trying out Kotlin for the first time and having a blast so far!
Also using an ECS architecture for the first time. It's quite a different way of reasoning about things, but it definitely helps with the dynamic fights that need to be simulated.
Best wishes,
The former developer of Bizarre Insights
I am planning to open source it (when I am at least somewhat happy with the implementation) but without any references to the bazaar. It just so happens that it uses items with cooldown and similar systems that deal with burn, poison, haste etc. ;)
You can then bring your own items and play out the simulations and maybe your items just so happen to be based on the bazaar or maybe you create your own custom items based on lord of the rings or whatever.
Right now, the project's primary purpose is to be an interesting problem that needs to be solved and helping me learn new things.
Btw. your tool looks great! A shame that team tempo is against these kinds of community driven tools
Why? Plenty of times I've been ordering food with friends and we just pass around a phone to put in the order or someone dictates their order. Sometimes this can involve a friend who is not physically there and so they text you their order in just plain text. I thought it would be cool for everyone to be able to get on the same site, customize their order how they want, and share their link. That way there's no way that anyone misunderstood or forgot anything when placing the final order.
SEO Extension Enhancements https://www.crawlspider.com/seo-pataka/
Two more chrome extension: Youtube Transcript Summary
Wirify like extension to generate wireframes from any website
i.e. instead of them having to download demos, extract them, parse them and then only query data. I want to just have a database available so they get to skip all those steps.
Not gonna make me rich but if I can get it to cover it's own costs I'll be stoked.
https://apps.apple.com/us/app/reflect-track-anything/id64638...
https://www.nutsvolts.com/magazine/article/february2012_Noon
The thing will be browser-based and, hopefully, both entertatining and educational.
- secure and complaint as it runs on Atlassian
- easy to create automation as AI does the heavy lifting of creating the automation scripts for Jira
- unlimited which was a major limitation in native Atlassian offering.
https://github.com/Merkoba/Harambe
But the last thing I did was this function to make my irc bot program itself:
The app is very mature, yet it could still be improved in interesting ways.
Wishing you good luck with finding a maintainer.
I'm only a couple of weeks in. But it's giving me a break from my programming language that I was working on. (It's a template language, also written in C, also cross-platform, that has a jit compiler with a bytecode fallback.)
I think there's an opportunity to do novel things in this space, and LLMs might help in terms of providing summaries that people actually want.
I'm building this for me, but I think it could be useful for other people, too.
Taking a look, it seems quite underwhelming[0] :( Lack of monetization on the web gave us the ad-driven content model that LLMs are now hovering up.
Have there been any other proposals for monetization?
What we found is that we can issue certificates for a wildcard domain even without asking the user to setup TXT records. If one CNAME record is set, we can set the TXT records on our domain to validate the wildcard domain.
Very excited about it.
(The main drive behind this was not to sell it, but to have a UI for when a website changes its layout and I'm on holidays and don't have access to my terminal and/or my yubikeys)
Got the basic happy path to work, albeit still some tweaks are needed to get it working a bit better and seem more conversational.
Been dabbling in game dev and have been having a good time with a little sailing game that I think could be a cozy “A Short Hike” esque , but where you have to grock how (simplified) sailing works.
With AI eating graphic designers lunch, I started to pivot and will add features for vectorizing and editing of AI generated images. I think this can become a really exciting product.
It's fun, with good mix of interesting technologies and it seems to solve a real problem for many users in HPC community!
So I’ve been building my own YouTube app, for my own kids. Better blocking of keywords (no more 1,000 MrBeast video recommendations). Better educational themes.
Email me if you’re interested in testing.
jim.jones1@gmail.com
In many cases, other methods run faster/scale better/use less energy.
https://j-stubbs.gitlab.io/algebraic_structures/
It's all very POC right now but the idea is to eventually add many improvements including documenting the Python API.
The goal is to bring fast random read/writes to Java. Fun project with lots of great challenges around performance while maintaining a nice API.
A 2D game programming language that lets you code multiplayer like singleplayer. My dream is for it to be a super-engaging way for teenagers to get into coding because everything they make they can actually play with other people.
Pretty fun to see how easy it is to put together a decent website on a shoestring budget (R2 hosting, all react frontend)
Easyjobapps.com - autofill job forms with tailored resumes and replies.
Because I can't fucking stop myself, I created a fantasy ISA and am working on an assembler and basic interpreter for said fantasy ISA.
It does one thing and it does it well. I built it with a friend and we released the iOS app last year. Currently building the Android app
Check it out: https://github.com/amlel-el-mahrouss (it's on the pinned repositories)
It’s so effective that I can have a chord idea at noon, and a song done before the evening
And I ran my first experiment on Saturday to good effect. Ran a small ad and already got some leads. I feel super pumped about it. And excited to share out the results soon! Definitely an easy experiment to start proving the model.
https://github.com/blairjordan/codachi
I just made it possible for them to appear in the Explorer (and not just in a Panel).
Relay transforms Obsidian into a collaborative environment with real-time collaborative editing, comfortably private folder sharing, offline support, and self-hostable Relay Servers.
[0] https://relay.md
Any advices are highly appreciated.
it's Flickr but for wildlife photography. A good olde fashioned web app. Made it to learn Nextjs as much as anything which was interesting, but got some good lighthouse scores, so hooray
Neighborhood App for Indians - https://neighar.com/
But pouring my soul into building Afterhours (afths.com); Duolingo for life skills (financial independence, building muscle, writing well, parenting etc)
I threw together a UI for sending & receiving Twilio SMS messages. Was surprised by the lack of free options, FOSS or otherwise.
Maybe Meta's open source segmentation tool would be handy. Maybe you can rig the person/animal/object in the image using one of the object detection tools on HuggingFace.
This seems like a really interesting project. I'd love to check it out if you plan on open sourcing it!
1. https://github.com/SketchSeg/SketchSeg-Natural-Prior
Upload your CSV, write a prompt, and get a journal-worthy chart.
Also, got some feedback for hands.sonnet.io, so I'd like to play with it a little bit if time permits (might be hard to stay inside, Spring has just started in Portugal).
Was doing it on the Fuel Network, but now that they let 30% of staff go last week (including me), I’m thinking about starting fresh and doing it on Solana.
https://play.google.com/store/apps/details?id=com.motioncam....
https://tracker.onlyusedtesla.com/
$9 bucks a month.LakyAI will help you build your brand by creating and sharing content online.
Right now I am working on a good blogging experience, but more is coming.
https://lakyai.com x.com/laky_ai
I love how MonkeyType lets you see exactly how much you’ve improved over time at typing and it’s inspired me to take a similar approach to this hobby of mine as well
If there is uptake the plan is to build out a toolset to help with managing a portfolio of arbs.
Also want to write a client in Zig.
So fun!
Hoping it will get some viral sharing and lead to some good quality backlinks.
Currently trying to convert the SwiftUI app to Compose using Skip.
The copy on the landing page needs to be updated, as more general use cases will be supported.
Https://billabear.com HTTPS://github.com/billabear/billabear
It’s meant to be used as a middleware in game engines and designed to empower writers that are not programmers.
I’ve deleted all my social media apps. I’m trying to see what’s missing in my life in terms of interacting with friends and family and trying to build it.
a small social network to keep track of your friends birthdays
feature requests and bug reports are appreciated!
- rainfrog is more keyboard centric, and it's built around vim-like keybindings
- rainfrog has minimal requirements to run (harlequin requires python)
- harlequin supports a lot more DBs and has a lot more drivers right now
It was born out of a personal need in past roles and teams. I launched it last year.
So I'm updating it and putting it back online!
I built a player’s player voting tool. If you play sports, enjoy!
Anyone writing FHIR / Clinical Quality Language queries would love to give access and get some feedback.
Feel free to reach out
Thinking of doing a set of widgets for stablecoins
[1] https://vykee.co
Gives you context on upcoming meetings you scheduled a week ago but cant remember what it was about :)
There is a crawler to chase given objective and crawl/store web page results. We use Claude Haiku and Brave Search API (own API keys) and we will support local models soon.
Potential use-cases are lead generation, competitor search, product tracking, contracts search.
basically built this system when working on other projects and decided to turn this into a product in case useful to others
This is a Fibonacci example. This code evaluates to 8:
[1 1 (x-1$ + x-2$)] 5
Graffiti art.
tl;dr: A 60fps embedded browser on the frontend lets you record manual steps and AI-driven steps (to assert/extract data). It then turns those into test suites. Any test with AI queries can auto-generate an API to be queried later.
Right now, I'm working on an agentic API builder. Example use case: Say you need data from Salesforce and JIRA — you log in, navigate to what you need, add an AI query step (or select elements manually), and set an update interval. The system then handles extraction and monitoring.
Why? Because at all my previous jobs, suggesting hiring QA engineers would get you laughed out of the room. But testing was desperately needed, as well as internal tooling. Burning developer/CTO time on wrangling multiple complex API's just to build some internal tool would take much longer without this. So I'm working on something that makes both vastly simpler for small teams. Hoping to have a workable demo next week!
I am hard at work preparing the 2nd edition of Seoul SPARKS (seoulsparks.com), a 6 weeks pre-college summer program in Korea (currently aimed at US students but open to students all over the world). It is designed to be a high quality, rigorous but also as immersive as possible program, for high school students who want to deepen their understanding of Korean language, culture, and history while earning academic credit at Seoul National University. My aim is to educate the future generation of Korean Studies scholars and I hope my program can be a stepping stone for that! My program director designed a chronological history curriculum, that explores Korea’s past and present through site visits and expert-led discussions. Each week focuses on a specific era of Korean history, beginning with the Joseon Dynasty (1392–1897), where students visit palaces, wear hanbok, and learn about Confucian traditions. The following weeks cover the Japanese colonial period (1910–1945), the Korean War and its aftermath (1950s), Korea’s rapid economic rise through the Miracle on the Han River (1960s–1980s), and finally, modern Korea, including democratization, globalization, and the Hallyu wave. These themes are reinforced through guided tours of historical sites, museums, and cultural landmarks. We try to make it fun too and I think our students last year had a blast!
We try to offer a lot of other really cool things, such as a 100% Customized Cultural Activity (these have included K-pop dance training at a professional studio, Korean Sign Language classes, traditional calligraphy, culinary workshops, and even mini-internships with local businesses ), the opportunity to work on a research project under the supervision of a Korean PhD student if they'd like, and we also link them with university mentors (basically, Korean college students) who hang out with them, answer their questions about life in Korea, help them adjust to life here, and just have fun with them really.
Last year's pilot program was very successful, we were blessed to have a fantastic cohort of very bright and motivated students. The program was also highly rated by parents and students alike (the only serious negative comment we received was: why is Korea so hot and humid during summer?), and I hope we can continue to grow and keep attracting the best students from all over the globe!
Anyway applications are open until April 30th so if any of you have kids or know someone who could be interested, I would be very grateful if you could spread the word :)
Thank you for reading!
Here is one:
When the random/rand functions are called with small moduli, well under 32 bits wide, they still draw a 32 bit word from the PRNG. I fixed that. Now the random state has a 32 bit shift register which it can load from the PRNG and take bits from it (in batches of 2, 4, 8 or 16).
There is a way to do this without any additional state other than that 32 bit word to indicate that the register has run out of bits.
We pretend that the register is 33 bits wide, giving it an indicator high bit that is always 1. Thus whenever the value drops to 1 or 0, it has to be reloaded. We cannot fit that indicator bit into the register, so what we do is: when we are reloading it with a fresh value, we immediately take bits we need from that value, shift it right, which creates the space for the bit. We then mask the bit in the right spot, depending on the shift size.
I worked on enhancing brace expansion in the glob* function. The regular glob* function has brace expansion if it is provided by the POSIX C library one, but the extended glob* has its own. I added numeric and string range expansion to it. It's better than the corresponding features in bash, because you can use more than one character, as in {AA..ZZ}. Also, if you use leading zeros in numeric ranges you get leading zeros in the output, as in {000..999}. The step sizes are supported.
Inspired by the step sizes in brace expansion, I added the same to range iteration:
2> [map cons 0..10..2 "a".."z"..3]
((0 . "a") (2 . "d") (4 . "g") (6 . "j") (8 . "m"))
if that hits home, i’d love 30 mins to share what i’m building and get your thoughts. reply here or DM me if you’re up for a quick chat! Calendly link (feel free to lmk if any other times work better for you) - https://calendly.com/vibrane/30min
I know it's been tried before, but I thought I'd attack it with a few different angles - web based, no chrome extension, and thresholds to help verify the article is worth it.
You can see the proof-of-concept here: https://paperwall.io/
FPV drone production
Also making a customizable self-tracking app that can be used as a habit tracker, health log, journal or similar. Goal is to make daily manual entries efficient and worthwhile. It will be local first and without an annoying subscription.
If anyone is personally interested in it or knows someone who could profit from something like this (e.g. because of their health condition) contact me please. Looking for testers and feedback to make it useful for people of various backgrounds and health conditions.
I’m rebuilding a learning library. Webpage bookmarks (with big help from raindrop.io), PDFs (hundreds of them, mostly book chapters), images, jupyter notebooks, markdowns, etc. using a Jekyll static site generator to minimize the tech stack hairballs.
The interesting part is that nearly all of the content is tagged to associate with two or more domains ex:
Goodreads-history-truecrime
PyTorch-Jupyter
Rubyonrails-Testing
Behavior-Gaslighting
Semiconductors-GPUs
And so on.
It’s an exercise in taxonomy creation. Searching by tag doesn’t quite get it. And we all know PDF auto summaries are tough.
I’m not expecting anybody to be impressed. It keeps me occupied while learning how to be (unfortunately) retired.
[0]: https://zoningverydifferentthanours.substack.com/p/a-pattern...
This gets complicated because the reason things are the way they are is _crucial_ to efficient, easy change, and the greater united states is a place obsessed with continuing _ethnic cleansing_. it's sad and tiring to exist inside of, the dehumanization caused every day, anew, by american style road networks, supremacy.
tl;dr american road networks and american zoning is two sides of the coin some groups used to accomplish 'regimes of social control', which was a mix of ethnic cleansing for some neighborhoods, and ensuring conformity for others.
Oh, and a cool data visualization project. Here's a map of most of my travel for the last few years: https://josh.works/mobility-data
polylines for daaaaaaaaaaays
Wanted to start tracking my net worth over weeks/years but wasn't impressed with my options being 1. Boring spreadsheet 2. Half cooked self hosted budgeting app 3. Pay X/month for third party budgeting app
Just wanted simple net worth tracking with a nice easy to use web app.
Maybe in the future i'll add some Plaid syncing of accounts but currently manual inputs for all accounts
Close enough to Postgres that apps think it's Postgres, but also runnable as a library like SQLite -- best of both worlds! And then if you're willing to not limit yourself to Postgres compatibility, you also get fancy new technologies like unsigned integers in a database! (Old SQL ecosystem is sometimes ridiculous.)
My personal journey goes something like this:
I've always suffered from both SQLite and Postgres idiosyncrasies, and almost always when deploying I've wanted to start out small, not have a big dedicated database server, and have meaningful tests that don't have multi-gigabyte dependencies and runtime assumptions. The idea of having something "close enough to Postgres to not have to learn much new" database with the low-end abilities of SQLite is something I've been wanting for roughly as long as I've known about SQLite -- even more so if it could also replace Postgres and remove the fear of differences between dev/early-stage vs later.
Much later, I learned about the newly-fashionable OLAP-over-object-store architectures, and I learned about Parquet. That lead to discovering Arrow and DataFusion. Arrow is an in-memory data format intended to be a standard interchange layer. It's basically array per column, which isn't exactly point-query oriented but helps make modern-day CPUs happy; quite well aligned with SIMD processing. DataFusion is a Rust framework that's essentially a query engine, and it has a decent query planner (arguably the hardest part of writing a database). RocksDB supports transactions and does MVCC, which is probably the second hardest part of writing a database. The rest just fell in place: sqlparser-rs is a Rust SQL syntax parser with Postgres etc compatibility nicely worked out. pgwire implements the Postgres wire protocol. Non-legacy clients can use FlightSQL and Arrow IPC for faster data transfer (Postgres wire protocol kinda sucks, it's that old). In-process use from Rust is darn trivial with DataFusion, and other languages can be dealt with by writing a C bridge -- once again, Arrow is an inter-language standard already, so all we need to do is to shove the result data buffers over to a more native "dataframe" library. It looks like I can actually glue these things together with less than a decade of effort!
There's lot to still worry about, but I'm feeling pretty positive about the project. And if and when I get to replace RocksDB with a pure-Rust data store that has all the right bells and whistles (in-house or not), the end result will be pure Rust, and aligned for modern world of NVMe, io_uring, and what not. That's a world I definitely want to live in.
Current status: Getting rid of the last `todo!()`s, unwraps etc that would distract from the "look at how robust this thing is" Rust evangelism too much. I need to put in stress tests and fault injection and make sure I'm configuring RocksDB right for transaction isolation and disk persistence. There's tons of missing features, but very few bugs-as-such (0 known that aren't about C++ integration), and missing features all return a decent explanatory error message instead of eating data. The darn thing already works as a SQL database -- largely because it's just DataFusion's query engine and me feeding it table scans. I wrote a SQL database without ever debugging a JOIN! The shortcuts I've been able to take due to help from preexisting projects are huge. For someone who grew up in the world of "every C project has to write basic data structures for themselves because C isn't very modular", it's downright amazing!
Check it out at https://panino.sh
Firefox android
[Sequential thinking](https://skeet.build/docs/integrations/sequentialthinking) - it’s like enabling thinking but without the 2x cost
[Memory](https://skeet.build/docs/integrations/memory) - I use this for repo / project specific prompts and workflows
[Linear](https://skeet.build/docs/integrations/linear)- be able to find and issue, create models a branch and do a first pass, update linear with a comment on progress
[github](https://skeet.build/docs/integrations/github) - create a PR with a summary of what o just did
[slack](https://skeet.build/docs/integrations/slack) - send a post to my teams channel with the linear and GitHub PR link with a summary for review
[Postgres](https://skeet.build/docs/integrations/postgres) / [redis](https://skeet.build/docs/integrations/redis) - connect my staging dbs and get my schema to create my models and for typing. Also use it to write tests or do quick one off queries to know the Redis json I just saved.
[Sentry](https://skeet.build/docs/integrations/sentry) - pull the issue and events and fix the issue, create bug tickets in linear / Jira
[Figma](https://skeet.build/docs/integrations/figma) - take a design and implement it in cursor by right clicking copying the link selection
[Opensearch](https://skeet.build/docs/integrations/opensearch) - query error logs when I’m fixing a bug
It's essentially a small search engine for videos that runs locally on your laptop. Previously, the system just extracted information about whole video files and maintained a searchable list of those files.
I'm putting the finishing touches on a major architectural change to solve a request from someone who creates highlight reels for professional soccer matches. They needed to tag and search for specific moments within videos - like all goals scored by a particular player across dozens of camera angles of dozens of matches.
This required re-engineering the entire data model to support metadata entries that point to specific segments of a file entity rather than just the file itself.
Instead of treating each file as an atomic unit, I now separate the concept of "content" from the actual files that contain it. This distinction allows me to:
1. Create "virtual clips" - time segments within a video that have their own metadata, tags, and titles - without generating new files
2. Connect multiple files that represent the same underlying content (like a match highlight with different ad insertions for YouTube vs. Twitch)
3. Associate various resolution encodings with the same logical content
For example, a content creator might have multiple versions of the same video with different ad placements for different channels. In the old system, these were just separate, unrelated files. Now, they're explicitly modeled as variants of the same logical content, making organization and search much more powerful.
I also completely reworked the job system, moving from code running in the Electron main process to spawning Temporal in a child process. I know it sounds like overkill for a desktop app, but it's been surprisingly perfect for a desktop app that's processing hundreds of terabytes of video.
When you're running complex ML pipelines on random people's home computers, things go wrong - custom FFmpeg versions that don't support certain codecs, permission issues with mounted volumes, their local model server crashes. With Temporal, when a job fails, I just show users a link to the Temporal Web UI where they can see exactly what failed and why. They can fix their local config and retry just that specific activity instead of starting over. It's cut my support burden dramatically.
My developer experience is so much better too. The ML pipeline for face recognition has multiple stages (small model looks for faces, bigger model does pose detection, embedding generation with even larger model) that takes minutes to run. With Temporal, I can iterate on just the activity that's failing without rerunning the entire pipeline. Makes developing these data-intensive workflows so much more manageable.
My perspective is all those hours of raw footage are just raw materials waiting to be shaped into stories, highlights, or presentations. The value is concentrated in a few hotspots.
Jellyfin and Plex appear to have been built on fundamentally different technical assumptions than Video Clip Library. They expect media to remain connected and accessible to the server at all times - when drives disconnect, they often purge those entries from their databases, requiring full rescans when reconnected. It appears Jellyfin only fixed this in Oct 2024.
The reality for many isn't sleek network storage - it's often just a plastic container filled with labeled hard drives sitting in a closet.
Video Clip Library is architected specifically for the archival cold storage workflow where most media is physically offline. The database maintains complete metadata even when drives are disconnected. When you search for 'soccer highlights from 2018,' it not only tells you what file contains that footage but precisely where that physical drive is located: 'in the blue SSD in Alice's desk, bottom drawer'. You can upload pictures of each drive, print out barcodes, write detailed notes. Organization stuff.
This workflow doesn't necessarily make sense for full-time professionals with dedicated workstations, but it's ideal for the long-tail use cases that originally drove me to build this software - normal people with occasional video projects. Of course, as is often the case, people bring it to their day job and start pushing for more business-oriented features. But the genesis of this software was for the individual creator, the freelancer, or small teams of auteurs collaborating on creative projects. A tool to accommodate the stop-and-start reality of passion projects. A poor man's editing with Proxies.
So far everyone is accumulating clip annotations on video files over time.
I'm thinking of clips as essentially write-only/append-only annotations. Labels or metadata attached to sections of videos rather than new files. The system is designed to support overlapping clips and allows you to filter/view all clips for a video.
To clarify, Video Clip Library is purely a search engine - it doesn't composite or edit videos. Although it will let you re-encode to save space. I built it for scenarios like: "I have a catalog of shots from the last five years, and when working on a new project, I might want to reuse B-roll or footage I've already taken." A YouTuber doing a Then and Now will find footage from their first year.
For me personally, the virtual clips feature will improve my learning process. I'm not a professional videographer. Naturally I spend time studying work from more skilled creators, trying to understand what makes it effective. I'm excited to take notes on specific moments - "these are the places across many different videos where I feel afraid" or "interesting rack focus technique here" - with notes and tags scoped to their own clips. I was already taking these notes in Obsidian. But it wasn't great.
I find a beauty in the layering: I can create overlapping clips that represent different aspects of the same footage - one layer for emotional responses, another for technical observations. Note: here I'm creating them manually one hour here, one hour there over months as I find the time or interest waxes. I might only annotate a few thousand clips across a couple hundred films in my lifetime. That's ok. I don't need the computer to understand the videos perfectly frame by frame.
The professional use case that prompted this feature is different - teams collect footage, then editors assemble compilations and marketing materials months later. They will run AI models to annotate videos as they're ingested, or apply new models to existing catalogs. Then someone with a creative concept can quickly search: "Do we already have footage that supports this idea or do we need to shoot something new?"
This is at the very early stages where I have a design sketch and some experiments that validate the design. Below is the README:
Rio is an experimental C++ async framework. The goal is to provide a lightweight framework for writing C++ server applications that is easy to use and provides low consistent latencies.
Today, async frameworks that focus on efficiency typically use one of two architectures:
1. Shared nothing architectures, also called thread-per-core. This is used by frameworks such as Seastar and Boost.Asio. In a shared-nothing architecture, each worker thread runs its own event loop and is intended to run on its own dedicated core. The application is architected to shard its workload over multiple workers with only infrequent communication between them. When a task performs a CPU bound task, it needs to be explicitly run in a thread pool as otherwise it would block other tasks from running in the current worker (often referred to as a "reactor stall").
2. Work stealing architectures. This architecture is used by frameworks such as Tokio. In this case there are also multiple worker threads, each running their own event loop. When a specific worker gets overloaded or runs a blocking task, other threads can execute ready tasks. This goes some way to prevent reactor stalls. However, even though other threads can steal ready tasks, they do not poll the event loop for new readiness events. This means that a task that does not yield back to the runtime will increase latencies for other requests assigned to that worker.
The thesis for Rio is that in real-world server applications, it gets increasingly hard to ensure you yield back frequently to the event loop. In particular, there are many CPU bound tasks that server applications commonly perform, such parsing protocols, or performing encryption and compression. If tasks take less than ~10 microseconds it is often not worth it to offload these to a thread pool as the system call overhead of synchronization will take more time than this. Additionally, putting in various thread offloads makes it harder to develop, especially in larger teams with individuals of different experience levels. The result is that there will either be too many work pushed on thread pools or too little. The net effect will be that latencies will be less consistent.
Rio is an experiment for a work stealing architecture where completion events can also be stolen. The Rio runtime uses multiple worker threads to handle asynchronous tasks. Each worker threads runs its own io_uring, which is also registered to an eventfd. A central "stealer" thread listens to the eventfds for all workers. When an readiness event becomes available, the stealer will check if the corresponding thread is currently executing a task. If so, it will signal an idle worker with a request to process the completion event and run any tasks that results in it. The stealing logic is aware of the system topology and will try to wake up a thread that shares a higher level cache with the task.
Quite frankly, it feels great!
I'm going to speak this update because that way I can have the text written more naturally. So, let's do that. So, since October last year, this means about six months, I've been using Cursor as a non-coder. Actually, I've been coding the last time, I guess, back in the days of Flash in ActionScript. So, I used Cursor for the past six months, maybe around 12 to 15 hours a day on average, you know, some days off, more hours in other days. And I've been working together with my co-founder, who's a developer, but he's also using AI, except he's using AI less than I do. So, we've been working on several things, of which one of them is closest to being released, maybe 80% done, which is, as I said, a vibe coding platform.
So this particular vibe coding platform will actually not compete with the likes of Replit, Bold, Loveable and about 40 other platforms that are basically the same: chat + IDE + preview area. What we're doing is actually different because we are rewriting a project that we built about 10 years ago. And I guess in a way similar to how Replit and Bolt had completely pivoted because of AI. The same thing is happening with this project of ours. So the project was actually about offering interactive widgets to people for their websites, but we had to build those manually. So now we have rewritten the platform from scratch using AI. And we offer zero widgets because with AI we are able to offer an infinity of widgets. That's exciting.
So this was supposed to stay a side project and frankly I'm pretty surprised that there's so much demand and the growth is amazing for all these AI code gen platforms. And if that happens to us, to this project, I don't know exactly what we are going to do because our plan is actually to tackle a bigger project that we are also working on. And the strategy here is to do what we call compounding startups. So instead of building a larger project with many features, we actually split that in several projects and we are doing them one at a time and giving each the ability to actually generate revenue. At some point we are likely going to raise capital. We had this plan before but with AI things have completely changed. We are able to do now in a week what five developers were doing in six months.
So the other projects are Talbo, Reclona and Tradul. Talbo is the what they compound into. But I am not ready to talk too much about them right now. :)
After struggling with vague outputs from AI coding assistants, I started experimenting with MECE principles (Mutually Exclusive, Collectively Exhaustive) to organize technical documentation hierarchically. Think of it as creating a "mental model" for AI rather than just reference docs.
Some early results: - 40% reduction in back-and-forth iterations with AI assistants - Much more consistent code style and architectural patterns - Better preservation of domain knowledge across the project
Currently refining the metadata structure and creating templates for different project types. The system works especially well with Cursor AI and similar assistants that can process structured context.
If anyone else is exploring this space of "AI-optimized documentation," I'd love to exchange notes.
Its a Offline-first desktop app with auto suggestion and auto correct feature to help you type faster.
A hobby project to learn AI techniques RAG, vector databses etc. Wrote something about it haha. Its been inactive for last 2 months tho coz of travelling, but I am going to revive it this week https://bhavepant.substack.com/p/typingfast-my-journey-into-...
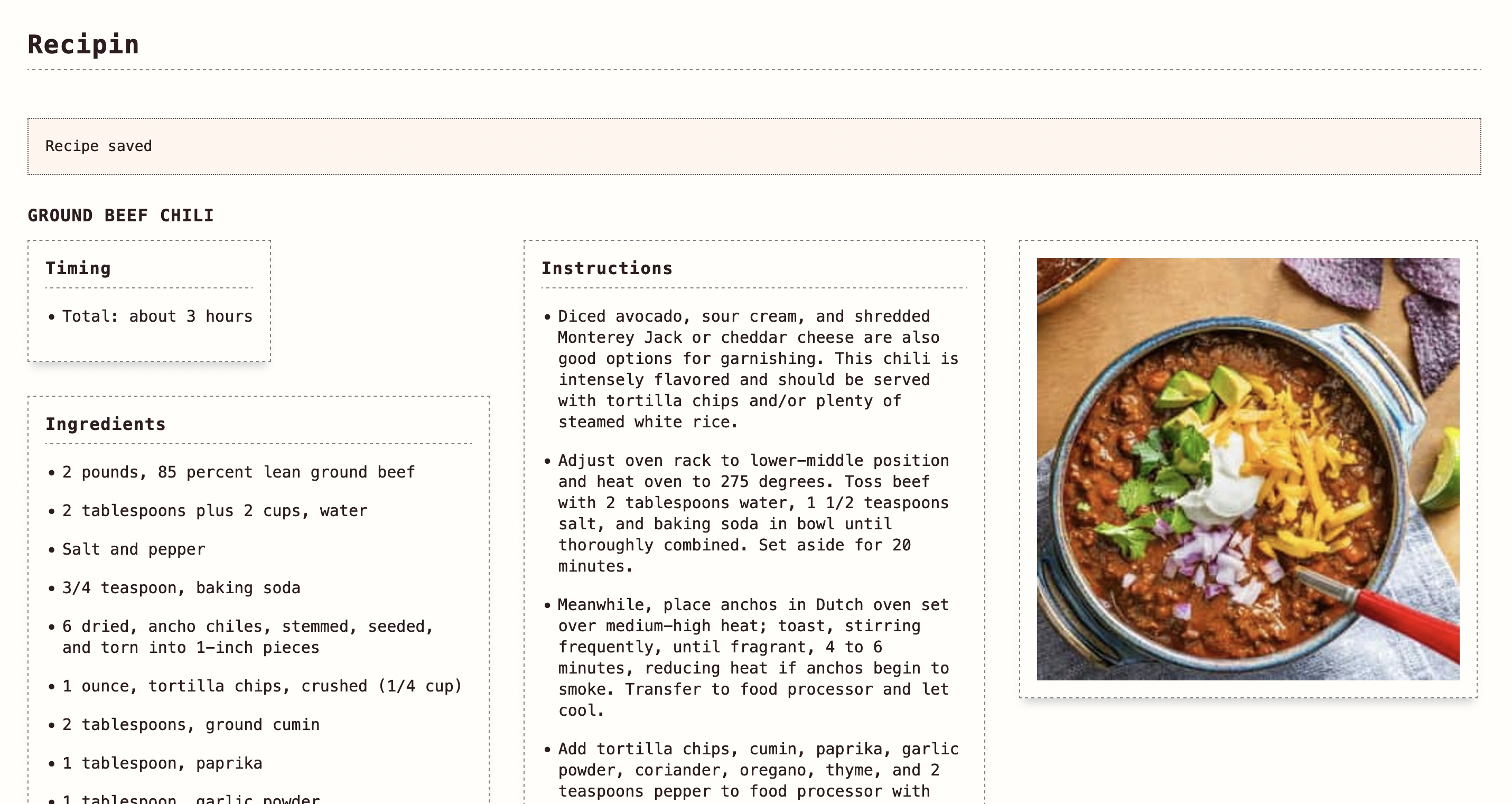{kind=link}