The main character’s car, Asurada, is basically a "Copilot" in every sense. It was designed by his dad to be more than just a tool, more like a partner that learns, adapts, and grows with the driver. Think emotional support plus tactical analysis with a synthetic voice.
Later in the series, his rival shows up driving a car that feels very much like a HUD concept. It's all about cold data, raw feedback, and zero bonding. Total opposite philosophy.
What’s wild is how accurately it captures the trade-offs we’re still talking about in 2025. If you’re into human-AI interaction or just want to see some shockingly ahead-of-its-time design thinking wrapped in early '90s cyber aesthetics, it’s absolutely worth a watch.
One part "90 degree right in 200m" and one part "OMG, sheep, dodge left".
Turns out this kind of UI is not only useful to spot bugs, but also allows users to discover implementation choices and design decisions that are obscured by traditional assistant interfaces.
Very exciting research direction!
And in fact, I think I saw a paper / blog post that showed exactly this, and then... nothing. For the last few years, the tech world became crazy with code generation, with forks of VSCode hooked to LLMs worth billions of dollars and all that. But AI-based code analysis is remarkably poor. The only thing I have seen resembling this is bug report generators, which is I believe is one of the worst approach.
The idea you have, that I also had and I am sure many thousands of other people had seem so obvious, why is no one talking about it? Is there something wrong with it?
The thing is, using such a feature requires a brain between the keyboard and the chair. A "surprising" token can mean many things: a bug, but also a unique feature, anyways, something you should pay attention to. Too much "green" should also be seen as a signal. Maybe you reinvented the wheel and you should use a library instead, or maybe you failed to take into account a use case specific to your application.
Maybe such tools don't make good marketing. You need to be a competent programmer to use them. It won't help you write more lines faster. It doesn't fit the fantasy of making anyone into a programmer with no effort (hint: learning a programming language is not the hard part). It doesn't generate the busywork of AI 1 introducing bugs for AI 2 to create tickets for.
> Is there something wrong with it?
> Maybe such tools don't make good marketing.
You had the answer the entire time :)
Features that require a brain between the AI and key-presses just don't sell. Don't expect to see them for sale. (But we can still get them for free.)
Are you saying that people of a certain competence level lose interest in force-multiplying tools? I don’t think you can be saying that because there’s so much contrary evidence. So what are you saying?
Some times people want them so badly that they will self-organize and collaborate outside of a market to make them. But a market won't supply them.
And yes, it's a mix of many people not being competent enough to see the value on them, markets putting pressure on companies to listen disproportionately to those people, publicity having a very low signal to noise ratio that can't communicate why a tool is good, and companies not respecting their customers enough to build stuff that is good for them (that last one isn't inherent to a market economy, but it near universal nowadays).
Either way, the software market just doesn't sell tools as useful as the GP is talking about.
I expect it definitely requires some iteration, I don't think you can just map logits to heat, you get a lot of noise that way.
In short, it's probably possible (and it's maybe a good engineering practice) to structure the source such as no specific part is really surprising
It reminds me how LLMs finally made people to care about having good documentation - if not for other people, for the AIs to read and understand the system
Honestly I've mostly seen the opposite - impenetrable code translated to English by AI
Perhaps to get that decent documentation it took a decent bit of agentic effort (or even multiple passes using different models) to truly understand it and eliminate hallucinations, so getting that high quality and accurate summary into a comment could save a lot of tokens and time in the future.
The perplexity calculation isn't difficult; just need to incorporate it into the editor interface.
import openai, math, os, textwrap, json, sys
query = 'Paris is the capital of' # short demo input
os.environ['OPENAI_API_KEY'] # check key early
client = openai.OpenAI()
resp = client.chat.completions.create(
model='gpt-3.5-turbo',
messages=[{'role': 'user', 'content': query}],
max_tokens=12,
logprobs=True,
top_logprobs=1
)
logprobs = [t.logprob for t in resp.choices[0].logprobs.content]
perplexity = math.exp(-sum(logprobs) / len(logprobs))
print('Prompt: "', query, '"', sep='')
print('\nCompletion:', resp.choices[0].message.content)
print('\nToken count:', len(logprobs))
print('Perplexity:', round(perplexity, 2))
Prompt: "Paris is the capital of"
Completion: France.
Token count: 2
Perplexity: 1.17
The naive solution I could come up with would be really expensive with openai, but if you have an open source model, you can write up custom inference that goes one-token-at-a-time through the text, and on each token you look up the difference in logprobs between the token that the LLM predicted vs what was actually there, and use that to color the token.
The downside I imagine to this approach is it would probably tend to highlight the beginning of bad code, and not the entire block - because once you commit to a mistake, the model will generally roll with it - ie, a 'hallucination' - so logprobs of tokens after the bug happened might only be slightly higher than normal.
Another option might be to use a diffusion based model, adding some noise to the input and having it iterate a few times through, then measuring the parts of the text that changed the most. I have only a light theory understanding of these models though, so I'm not sure how well that would work
Sounds like it’s easier to pinpoint the bug.
Interestingly, frequency of "surprising" sentences is one of the ways quality of AI novels is judged: https://arxiv.org/abs/2411.02316
I'd like to see more contextually meaningful refactoring tools. Like "Remove this dependency" or "Externalize this code with a callback".
And refactoring shouldn't be done by generatively rewriting the code, but as a series of guaranteed equivalent transformations of the AST, each of which should be committed separately.
The AI should be used to analyse the value of the transformation and filter out asinine suggestions, not to write code in itself.
LLMs generate new functions all the time, I'd guess these would be light green, maybe the first token in the name would be yellow and it would get brighter green as the name unfolds.
The logits are probably all small when in the global scope where it's not clear what will be defined next. I'm not imagining mapping logits directly to heat, the ordering of tokens seems much more appropriate.
Thought experiment: as you write code, an LLM generates tests for it & the IDE runs those tests as you type, showing which ones are passing & failing, updating in real time. Imagine 10-100 tests that take <1ms to run, being rerun with every keystroke, and the result being shown in a non-intrusive way.
The tests could appear in a separated panel next to your code, and pass/fail status in the gutter of that panel. As simple as red and green dots for tests that passed or failed in the last run.
The presence or absence and content of certain tests, plus their pass/fail state, tells you what the code you’re writing does from an outside perspective. Not seeing the LLM write a test you think you’ll need? Either your test generator prompt is wrong, or the code you’re writing doesn’t do the things you think they do!
Making it realtime helps you shape the code.
Or if you want to do traditional TDD, the tooling could be reversed so you write the tests and the LLM makes them pass as soon as you stop typing by writing the code.
When you give up the work of deciding what the expected inputs and outputs of the code/program is you are no longer in the drivers seat.
You don’t need to write tests for that, you need to write acceptance criteria.
Sir, those are called tests.
Acceptance criteria is a human-readable text that the person specifying the software has to write to fill-up a field in Scrum tools and not at all guide the work of the developers.
It's usually derived from the description by an algorithm (that the person writing it has to run on their mind), and any deviation from that algorithm should make the person edit the description instead to make the deviation go away.
You're not familiar with automated testing or BDD, are you?
> (...) to fill-up a field in Scrum tools (..)
It seems you are confusing test management software used to tracks manual tests with actual acceptance tests.
This sort of confusion would be ok 20 years ago, but it has since went the way of the dodo.
That would be interesting. Of course, gherkin tends to just be transpiled into generated code that is customized for the particular test, so I'm not sure how AI can really abstract it away too much.
You need some of way of precisely telling AI what to do. As it turns out there is only that much you can do with text. Come to think of it, you can write a whole book about a scenery, and yet 100 people will imagine it quite differently. And still that actual photograph would be totally different compared to the imagination of all those 100 people.
As it turns out if you wish to describe something accurately enough, you have to write mathematical statements, in other words statements that reduce to true/false answers. We could skip to the end of the discussion here, and say you are better of either writing code directly or test cases.
This is just people revisiting logic programming all over again.
I think this is the detail you are not getting quite right. The truth of the matter is that you don't need precision to get acceptable results, at least in 100% of the cases. As everything in software engineering, there is indeed "good enough".
Also worth noting, LLMs allow anyone to improve upon "good enough".
> As it turns out if you wish to describe something accurately enough, you have to write mathematical statements, in other words statements that reduce to true/false answers.
Not really. Nothing prevents you to refer to high-level sets of requirements. For example, if you tell a LLM "enforce Google's style guide", you don't have to concern yourself with how many spaces are in a tab. LLMs have been migrating towards instruction files and prompt files for a while, too.
But if you want a near 100% automation, you need precise way to specify what you want, else there is no reliable way interpreting what you mean. And by that definition lots of regression/breakage has to be endured everytime a release is made.
> When you give up the work of deciding what the expected inputs and outputs of the code/program is you are no longer in the drivers seat.
You don’t need to personally write code that mechanically iterates over every possible state to remain in the driver’s seat. You need to describe the acceptance criteria.
You're describing the happy path of BDD-style testing frameworks.
What level do you think there is above "Given I'm logged in as a Regular User When I go to the front page Then I see the Profile button"?
I'm describing a scenario as implemented in a gherkin feature file. A feature is tracked by one or more scenarios.
https://cucumber.io/docs/gherkin/reference/
> Do you seriously think there is no higher level than given/when/thens?
You tell me which higher level you have in mind.
The problem is that tests are for the unhappy path just as much as the happy path, and unhappy paths tend to get particular and detailed, which means even in gherkin it can get cumbersome.
If AI is to handle production code, the unhappy paths need to at least be certain, even if repetitive.
Those does not involves writing state transitions. You are merely describing the acceptance criteria. Imperative is the norm because that's how computers works, but there are other abstractions that maps more to how people thinks. Or how the problem is already solved.
Acceptance criteria might be something like “the user can enter their email address”.
Tests might cover what happens when the user enters an email address, what happens when the user tries to enter the empty string, what happens when the user tries to enter a non-email address, what happens when the user tries to enter more than one email address…
In order to be in the driver’s seat, you only need to define the acceptance criteria. You don’t need to write all the tests.
That only defines one of the things the user can enter. Should they be allowed to enter their postal address? Maybe. Should they be allowed to enter their friend's email address? Maybe.
Your acceptance criteria is too shy of details.
There is no prescriptive manner in which to deliver the solution, unless it was built into the acceptance criteria.
You are not talking about the same thing as the parent.
I don't think that's how gherkin is used. Take for example Cucumber. Cucumber only uses it's feature files to specify which steps a test should execute, whereas steps are pretty vanilla JavaScript code.
In theory, nowadays all you need is a skeleton of your test project, including feature files specifying the scenarios you want to run, and prompt LLMs to fill in the steps required by your test scenarios.
You can also use a LLM to generate feature files, but if the goal is to specify requirements and have a test suite enforce them, implicitly the scenarios are the starting point.
Isn't that logic programming/Prolog?
You basically write the sequence of conditions(i.e tests in our lingo) that have to be true, and the compiler(now AI) generates code for your.
Perhaps there has to be a relook on how Logic programming can be done in the modern era to make this more seamless.
I'm also not sure how LLM could guess what the tests should be without having written all of the code, e.g. imagine writing code for a new data structure
There's nothing in C++ that prevents this. If build times are your bogeyman, you'd be pleased to know that all mainstream build systems support incremental builds.
Even with incremental builds, that surely does not sound plausible? I only mentioned C++ because that's my main working language, but this wouldn't sound reasonable for Rust either, no?
Yeah, OP's point is completely unrealistic and doesn't reflect real-world experience. This sort of test watchers is mundane in any project involving JavaScript, and not even those tests re-run at each keystroke. Watch mode triggers tests when they detect changes, and waits for test executions to finish to re-run tests.
This feature consists of running a small command line app that is designed to run a command whenever specific files within a project tree are touched. There is zero requirement to only watch for JavaScript files or only trigger npm build when a file changes.
To be very clear, this means that right now anyone at all, including you and me, can install a watcher, configure it to run make test/cutest/etc when any file in your project is touched, and call it a day. This is a 5 minute job.
By the way, nowadays even Microsoft's dotnet tool supports watch mode, which means there's out-of-the-box support to "rerunning 10-100 tests that take 1ms after each keystroke".
If you also don't expect necessarily running the entire test suite, but just a subset of tests that are, say, labelled to test a specific function only without expensive setup, it'd potentially be viable.
You can also ignore running it on every keypress with some extra work:
- Keypresses that don't change the token sequence (e.g. because you're editing a comment) does not require re-running any tests. - Keypresses that results in a syntactically invalid file does not require re-running any tests, just marking the error.
I think it'd be an interesting experiment to have editing rather than file save trigger a test-suite watcher. My own editor syncronises the file state to a server process that other processes can observe, so if I wanted to I could wire a watcher up to re-tokenize an edited line and trigger the test suite (the caveat being I'd need to deal with the file state not being on the file system) when the state changes instead of just on save. It already retokenizes the line for syntax highlighting anyway.
There probably is a setup where this works well, but the LLM and humans need to be able to move across the respective boundaries fluidly...
Writing clear requirements and letting the AI take care of the bulk of both sides seems more streamlined and productive.
I think this is a bad approach. Tests enforce invariants, and they are exactly the type of code we don't want LLMs to touch willy-nilly.
You want your tests to only change if you explicitly want them to, and even then only the tests should change.
Once you adopt that constraint, you'll quickly realize ever single detail of your thought experiment is already a mundane workflow in any developer's day-to-day activities.
Consider the fact that watch mode is a staple of any JavaScript testing framework, and those even found their way into .NET a couple of years ago.
So, your thought experiment is something professional software developers have been doing for what? A decade now?
Yes, I agree. The nuance is that they need to be rewritten independently and without touching the code. You can't change both and expect to get a working system.
I'm speaking based on personal experience, by the way. Today's LLMs don't enforce correctness out of the box and agent mode has only one goal: getting things to work. I had agent mode flip invariants in tests when trying to fix unit tests it broke, and I'm talking about egregious changes such as flipping requirements in line with "normal users should not have access to the admin panel" to "normal users should have access to the admin panel". The worst part is that if agent mode is left unsupervised, it will even adjust the CSS to make sure normal users have a seamless experience going through the admin panel.
There could be some visual language for how recently changes happened to the LLM-generated tests (or code for TDD mode).. then you'd be able to see that a test failed and was changed recently. Would that help?
Even if this were possible, this seems like an absolutely colossal waste of energy - both the computer's, and my own. Why would I want incomplete tests generated after every keystroke? Why would I test an incomplete if statement or some such?
Doesn’t seem like high ROI to run full suite of tests on each keystroke. Most keystrokes yield an incomplete program, so you want to be smarter about when you run the tests to get a reasonably good trade off.
It also updates the coverage on the fly, you don't even have to look at the test output to know that you've broken something since the tests are not reaching your lines.
https://gavindraper.com/2020/05/27/VS-Code-Continious-Testin...
I've recently been snoozing co-pilot for hours at a time in VS Code because it’s adding a ton of latency to my keystrokes. Instead, it turns out that `rust_analyzer` is actually all that I need. Go-to definition and hover-over give me exactly what the article describes: extra senses.
Rust is straightforward, but the tricky part may be figuring out what additional “senses” are helpful in each domain. In that way, it seems like adding value with AI comes full circle to being a software design problem.
ChatGPT and Claude are great as assistants for strategizing problems, but even the typeahead value seems to me negligible in a large enough project. My experience with them as "coding agents" is generally that they fail miserably or are regurgitating some existing code base on a well known problem. But they are great at helping config things and as teachers in (the Socratic sense) to help you get up-to-speed with some technical issue.
The heads-up display is the thesis for Tritium[1], going back to its founding. Lawyers' time and attention (like fighter pilots') is critical but they're still required in the cockpit. And there's some argument they always will be.
[1] https://news.ycombinator.com/item?id=44256765 ("an all-in-one drafting cockpit")
For example, if you are debugging memory leaks in a specific code path, you could get AI to write a visualisation of all the memory allocations and frees under that code path to help you identify the problem. This opens up an interesting new direction where building visualisations to debug specific problems is probably becoming viable.
This idea reminds me of Jonathan Blow's recent talk at LambdaConf. In it, he shows a tool he made to visualise his programs in different ways to help with identifying potential problems. I could imagine AI being good at building these. The talk: https://youtu.be/IdpD5QIVOKQ?si=roTcCcHHMqCPzqSh&t=1108
I've experienced the case where asking for a quick python script was faster and more powerful than learning how to use a cli to interact with an API.
It scratches the itch to build and ship with the benefit of a growing library of low scope, high performance, highly customized web tools I can write over a few hours in an evening instead of devoting weekends to it. It feels like switching from hand to power tools
And interestingly, that is indeed the feature I find most compelling from Cursor. I particularly love when I’m doing a small refactor, like changing a naming convention for a few variables, and after I make the first edit manually Cursor will jump in with tab suggestions for the rest.
To me, that fully encapsulates the definition of a HUD. It’s a delightful experience, and it’s also why I think anyone who pushes the exclusively-copilot oriented Claude Code as a superior replacement is just wrong.
I've spent the last few months using Claude Code and Cursor - experimenting with both. For simple tasks, both are pretty good (like identifying a bug given console output) - but when it comes to making a big change, like adding a brand new feature to existing code that requires changes to lots of files, writing tests, etc - it often will make at least a few mistakes I catch on review, and then prompting the model to fix those mistakes often causes it to fix things in strange ways.
A few days ago, I had a bug I just couldn't figure out. I prompted Claude to diagnose and fix the issue - but after 5 minutes or so of it trying out different ideas, rerunning the test, and getting stuck just like I did - it just turned off the test and called it complete. If I wasn't watching what it was doing, I could have missed that it did that and deployed bad code.
The last week or so, I've totally switched from relying on prompting to just writing the code myself and using tab complete to autocomplete like 80% of it. It is slower, but I have more control and honestly, it's much more enjoyable of an experience.
I'd love to have something that operates more at the codebase level. Autocomplete is very local.
(Maybe "tab completion" when setting up a new package in a monorepo? Or make architectural patterns consistent across a whole project? Highlight areas in the codebase where the tests are weak? Or collect on the fly a full view of a path from FE to BE to DB?)
We're getting more and more information thrown at us each day, and the AIs are adding to that, not reducing it. The ability to summarise dense and specialist information (I'm thinking error logs, but could be anything really) just means more ways for people to access and view that information who previously wouldn't.
How do we, as individuals, best deal with all this information efficiently? Currently we have a variety of interfaces, websites, dashboards, emails, chat. Are all these necessary anymore? They might be now, but what about the next 10 years. Do I even need to visit a companies website if can get the same information from some single chat interface?
The fact we have AIs building us websites, apps, web UI's just seems so...redundant.
I'm not really sure what trust means in a world where everyone relies uncritically on LLM output. Even if the information from the LLM is usually accurate, can I rely on that in some particularly important instance?
I still believe it fundamentally comes down to an interface issue, but how trust gets decoupled from the interface (as you said, the padlock shown in the browser and certs to validate a website source), thats an interesting one to think about :-)
Not not everything an LLM tells you is going to be worth going to court over if it's wrong though.
https://erinkissane.com/meta-in-myanmar-full-series
When LLM are suddenly everywhere, who's making sure that they are not causing harm? I got the above link from Dan Luu (https://danluu.com/diseconomies-scale/) and if his text there is anything to go by, the large companies producing LLMs will have very little interest in making sure their products are not causing harm.
By the 7th generation it's hard to see how humans will still be value-add, unless it's for international law reasons to keep a human in the loop before executing the kill chain, or to reduce Skynet-like tail risks in line with Paul Christiano's arms race doom scenario.
Perhaps interfaces in every domain will evolve this way. The interface will shrink in complexity, until it's only humans describing what they want to the system, at higher and higher levels of abstraction. That doesn't necessarily have to be an English-language interface if precision in specification is required.
It is a little known secret that plenty of defense systems are already set up to dispense of the human in the loop protocol before a fire action. For defense primarily, but also for attack once a target has been designated. I worked on protocols in the 90's, and this decision was already accepted.
It happens to be so effective that the military won't bulge on this.
Also, it is not much worse to have a decision system act autonomously for a kill system, if you consider that the alternative is a dumb system such as a landmine.
Btw: while there always is a "stop button" in these systems, don't be fooled. Those are meant to provide semblance of comfort and compliance to the designers of those systems, but are hardly effective in practice.
I think we're slowly allowing AI access to the interface layer, but not to the information layer, and hopefully we'll figure out how to keep it that way.
I can be fully immersed in a game or anything and keep Claude in a corner of a tmux window next to a browser on the other monitor and jump in whenever I see it get to the next step or whatever.
[0] https://jeffser.com/alpaca/
[1] https://github.com/GSConnect/gnome-shell-extension-gsconnect
There are a handful of products that all have a similar proposition (with better agents than OpenAI frankly), but Codex I've found is unique in being available via a consumer app.
That said, the best GUI is the one you don't notice, so uh... I can't actually name anything else, it's probably deeply engrained in my computer usage.
But an operator learns to intuit which aspects to trust and which to double-check. The fact that it’s an “extra sense” can outweigh the fact that it’s not a perfect source of truth, no? Trust the tech where it proves useful to you, and find ways to compensate (or outright don’t use it) where it’s not.
I think the idea of an hud is better than the current paradigm, but it doesn't solve the fundamental problem.
Although we are talking HUDs, I'm not really talking about UI widgets having the good old skew-morphism or better buttons. In the cockpit the pilot doesn't have his controls on a touch screen, he has an array of buttons and dials and switches all around him. It's these controls that are used in response to what the pilot sees on the HUD and it's these controls that change the aircraft according to the pilots will, which in turn change what the HUD shows.
It can detect situations intelligently, do the filtering, summarisation of what’s happening and possibly a recommendation.
This feels a lot more natural to me, especially in a business context when you want to monitor for 100 situations about thousands of customers.
Aren't auto-completes doing exactly this? It's not a co-pilot in the sense of a virtual human, but already more in the direction of a HUD.
Sure you can converse with LLMs but you can also clearly just send orders and they eagerly follow and auto-complete.
I think what the author might be trying to express in a quirky fashion, is that AI should work alongside us, looking in the same direction as we are, and not being opposite to us at the table, staring at each other's and arguing. We'll have true AI when they'll be doing our bidding, without any interaction from us.
Recent coding interfaces are all trending towards chat agents though.
It’s interesting to consider what a “tab autocomplete” UI for coding might look like at a higher level of abstraction, letting you mold code in a direct-feeling way without being bogged down in details.
But if I invoke the death of the author and pretend HUD meant HUD, then it's a good point: tools are things you can form a cybernetic system with, classic examples being things like hand tools or cars, and you can't form a cybernetic system with something trying to be an "agent". To be in a cybernetic system with something you need predictable control and fast feedback, roughly.
Rather I think most implementations of HUD AI interactions so far have been quite poor because the interaction model itself is perhaps immature and no one has quite hit the sweet spot yet (that I know of). Tab autocompletion is a simple gesture, but trades off too much control for more complex scenarios and is too easy to accidentally activate. Inline chat is still a context switch and also not quite right.
I see the value in HUDs, but only when you can be sure output is correct. If that number is only 80% or so, copilots work better so that humans in the loop can review and course correct - the pair programmer/worker. This is not to say we need ai to get to higher levels of correctness inherently, just that systems deployed need to do so before they display some information on HUD.
Just because most people are fond of it doesn't actually mean it improves their life, goals and productivity.
I think the challenge is primarily the context and intent.
The spellchecker knows my context easily, and there is a setting to choose from (American English, British English, etc.), as well as the paragraphs I'm writing. The intent is easy to recognise. While in a codebase, the context is longer and vaguer, the assistant would hardly know why I'm changing a function and how that impacts the rest of the codebase.
However, as the article mentions, it may not be a universal solution, but it's a perspective to consider when designing AI systems.
Compare another sci-fi depiction taken to the opposite extreme: Sirius Cybernetics products in the Hitchhikers Guide books. "Thank you for making a simple door very happy!"
Orchestration platforms - Evolution of tools like n8n/Make into cybernetic process design systems where each node is an intelligent agent with its own optimization criteria. The key insight: treat processes as processes, not anthropomorphize LLMs as humans. Build walls around probabilistic systems to ensure deterministic outcomes where needed. This solves massive "communication problems"
Oracle systems - AI that holds entire organizations in working memory, understanding temporal context and extracting implicit knowledge from all communications. Not just storage but active synthesis. Imagine AI digesting every email/doc/meeting to build a living organizational consciousness that identifies patterns humans miss and generates strategic insights.
just explored more about it on my personal blog https://henriquegodoy.com/blog/stream-of-consciousness
I remember the first time I started up Win95 from DOS days. Stunning.
I've been particularly feeling like this regarding AI code reviewers recently - I don't want a copilot that will do their own review, I want a hud that will make it easier for me to understand the change.
I've been toying with crafting such a code review tool as a side project recently: https://useglide.ai
As the cost of tokens goes down, or commodity hardware can handle running models capable of driving these interactions, we may start to see these UIs emerge.
For example, if i'm working on authentication logic, i'd much rather see a smart heads up display, you look at a function and get advice on where this might mess other things up in the codebase, edge cases, etc. A smarter form of current IDES that doesn't mean you click through 50 different files to work out that this third party package doesn't work on specific code. A HUD in this case is ideal.
But I find there's a more detailed, slower development, I still really often use the chat function on claude mixed with Obsidian to hold bits of information i've found useful, this is more related to getting a deeper understanding of certain concepts. As a stupid developer, I often find I might need something explained 20 times in 20 different ways, and actually a predictive text model is perfect in so many circumstances to explain a massive algorithm step by step. It's ideal for things like shader code, where I might come back to it 6 months later and want to work out what was in my head at the time, a historic chat is perfect for those things.
There's definitely a balance to be struck, I think now that the hype cycle is peaking we can hopefully seperate the profit seeking AI tools from the useful day to day knowledge expansion. Currently it feels like the discovery of perspective in the reneissance - instead of using it to further advancements, we're attempting to sell perspective courses to people.
Start with a snapshot of what you are envisioning using Blender.
[0]: https://www.geoffreylitt.com/2024/12/22/making-programming-m...
I think Cursor's tab completion and next edit prediction roughly fits the pattern, you don't chat, you don't ask or explain, you just do... And the more in coherent your actions are the more useful the HUB becomes.
Like, we have HUDs - that's what a HUD is - it's a computer program.
Can we embed useful data behind the content we produce/consume or derive personalised versions for the user?
-> Text/audio/video tailored for me and my interests? (ie. not just content recommended for me, but the content itself is tailored for me in terms of the insights and practical applications) -> Podcasts I can interact with? -> Audiobooks I can ask questions about?
Richer interaction that allows for more back&forth and key insights for the user and use case.
I don’t use Copilot or other coding AIs directly in the IDE because, most of the time, they just get in the way. I mainly use ChatGPT as a more powerful search engine, and this feels like exactly the kind of IDE integration that would fit well with my workflow.
I don't want inline comments as those accumulate, don't get cleaned up appropriately by the LLM.
In the firefox task manager nothing really looked odd, but opening that tab and displaying it is insanely CPU intensive.
Pausing the autoplaying video makes it seem like a sane web page in terms of CPU usage. I'm surprised how much CPU playing that video consumed.
Huds are just good UI, something copilots can natively exist as part of in the form of contextual insights and alerts.
We’re moving on to agency where it’s everything else vs an entirely different entity taking the action of flying the plane from take off to landing.
The article also mentions that agents are copilots:
> Here’s another personal example from AI coding. Let’s say you want to fix a bug. The obvious “copilot” way is to open an agent chat and ask it to do the fix.
That said, CoPilot in the form of "autocomplete" is kind of that.
I have been enjoying the hell out of Claude Code, but I'd feel much better about it if it wasn't a case of "here take this pile of diffs" and had a mode Socratic modality.
A tool that works with me instead of for me, because I'm going to have to review everything it does anyways.
On a wider note, I buy the argument for alternative interfaces other than chat, but chat permeates our lives every day, smartphone is full of chat interfaces. HUD might be good for AR glasses though, literal HUD.
This is a design interface problem. Self-driving cars can easily ingest this HUD. This is the reason what makes Apple's AI different from other microservice-like AI. The spell checker, rewrite, proofread are naturally integrated into the UI to the extent it doesn't feel like AI powered operations.
Copilot is more like a framework where an AI system exists which tells me what to do (a bit like the inverse of a library).
People do walk into walls, though.
I see the appeal of the idea, but it's not a replacement for something that actually agressively demands your attention when there are high risk events.
But why should it be only the human developer who benefits? What if that debugger program becomes a tool that AI agents can use to more accurately resolve bugs?
Indeed, why can't any programming HUD be used by AI tools? If they benefit humans, wouldn't they benefit AI as well?
I think we'll be pretty quickly at the point where AI agents are more often than not autonomously taking care of business, and humans only need to know about that work at critical points (like when approvals are needed). Once we're there, the idea that this HUD concept should be only human-oriented breaks down.
What comes immediately to mind for me is using embeddings to show closest matches to current cursor position on the right tab for fast jumping to related files.
it kind of worked. the magic was the smallest UI around it:
- timeline of dials + retries
- "call me back" flags
- when it tried, who picked up
- short summaries with links to the raw transcript
once i could see the behavior, it stopped feeling spooky and started feeling useful.
so yeah, copilots are cool, but i want HUDs: quiet most of the time, glanceable, easy to interrupt, receipts for every action.
(I don't know what we'll be doing instead, I just think text prompts feel dumb.)
1. They introduce new and fascinating failure modes that never happened with the old, dumb devices (e.g. if your router fails you lose the ability to control your lights).
2. They demand human attention at the slightest provocation (e.g. the microwave beeps loudly forever when your food is done, every app on your phone insists on interacting with you whenever the company would like to upsell you something, etc.)
Item 2 above is what TFA is about. Yes you can often turn this shit off, but that's not the point. The point is you shouldn't have to. Useful technology should never call attention to itself in the manner of someone with narcissistic personality disorder.
But what about emergency situations? Glad you asked. Many airplane crashes in modern aircraft have happened because of "warning buzzer overload" which happens when one important system on the aircraft fails and then causes a cascade of secondary warnings, while giving the pilot no insight as to the root cause. A true AI assistant would reason about such situations and guide the pilot toward the root solution.
A true coding assistant would do the same kind of reasoning about program errors and suppress multipage error dumps in favor of flagging the root issue.
now we need a web framework with faster reload times
Planes do actually have this now. It seems to work okay:
https://en.m.wikipedia.org/wiki/Traffic_collision_avoidance_...
You’re right that there’s a voice alert. But TCAS also has a map of nearby planes which is much more “HUD”! So it’s a combo of both approaches.
(Interestingly it seems that TCAS may predate Weiser’s 1992 talk)
https://nitter.poast.org/im_roy_lee/status/19387190060029217...
Lots of great ideas in this space but it's tough to make something that delivers value and also is economically viable
Beyond Intelligent Machines: Just Do It (1993) (umd.edu)
https://news.ycombinator.com/item?id=22742100
Mark Weiser and Ben Shneiderman and I worked at the University of Maryland College Park before he went to PARC, and they have a similar take on agents versus augmentation.
I think Douglass Engelbart, Maurice Wilkes, and Joseph Weizenbaum would agree with many of their points.
https://www.cs.umd.edu/~ben/papers/Shneiderman1993Beyond.pdf
Easier to read text version:
http://www.cs.umd.edu/hcil/trs/93-03/93-03.html
Beyond Intelligent Machines, IEEE Software, January 1993
https://news.ycombinator.com/item?id=22744573
DonHopkins on April 1, 2020 | parent | context | favorite | on: Beyond Intelligent Machines: Just Do It (1993)
I love this article! I worked with Ben Shneiderman at HCIL, and when he sent me a copy of this article to review, I was inspired by the "Dynamic Queries" of his "Dynamic Home Finder" demo, to implement something like that for SimCity (the Frob-O-Matic window). [Video and transcript below.]
Here are some of the main points of his article:
Don't label machines as "intelligent".
It limits the imagination. We should have greater ambitions.
Enable humans to accomplish tasks that weren't before possible, instead of trying to enable machines to accomplish tasks people can already do.
Predictability and control are desirable qualities. Give users the feeling of mastery, competence, and understanding, sense of accomplishment.
The "intelligent machine" label limits or even eliminates human responsibility.
If you treat machines like people, you're likely to end up treating people like machines.
Ben Shneiderman called his lab HCIL instead of CHIL, to explicitly put Humans before Computers.
Here's his description of "Dynamic Queries" and the "Dynamic Home Finder":
>Dynamic Queries. These animations let you rapidly adjust query parameters and immediately display updated result sets, which makes them very effective when a visual environment like a map, calendar, or schematic diagram is available. The immediate display of results lets users more easily develop intuitions, discover patterns, spot trends, find exceptions, and see anomalies.
>Figure 2 shows a screen from Dynamic HomeFinder, a prototype interface for real-estate agents that uses dynamic queries, written by Christopher Williamson of UM. Users can adjust the cost, number of bedrooms, and location of the A and B markers, among other characteristics, and points of light appear on a map to indicate a home that matches their specifications. Clicking on a point of light brings up a home description or image.
>Users of Dynamic HomeFinder can execute up to 100 queries per second (rather than one query per 100 seconds as is typical in a database query language), producing a revealing animated view of where high- or low-price homes are found-and there are no syntax errors.
>Our empirical study of 18 users showed Dynamic HomeFinder to be more effective than a natural-language interface using Q&A from Symantec (C. Williamson and B. Shneiderman, The Dynamic HomeFinder: Evaluating Dynamic Queries in a Real-Estate Information Exploration System," Proc. SIG Information Retrieval, ACM Press, 1992, pp. 338-346).
https://www.cs.umd.edu/users/ben/papers/Williamson1992dynami...
That inspired me to implement a version of the "Dynamic Home Finder" in SimCity:
Multi Player SimCityNet for X11 on Linux (Dynamic Home Finder / Frob-O-Matic demo at 3:35).
https://www.youtube.com/watch?v=_fVl4dGwUrA&t=3m35s
Transcript:
Here's an interesting thing inspired by Ben Shneiderman.
We can look at the ... This is the "Dynamic Zone Filter".
So we are going to set this to be dynamic.
Now it's going to show all the zones, but it's not going to show the ones that don't pass this filter.
So this filter is currently all the way open.
Now we're going to change population density.
This is a two-ended slider.
This is the segment of the population density, from zero to 81.
So everything else will disappear.
Say I'm looking for a home. I want low population density. But I want high rate of growth.
And now, these are the places that have low population density and high rate of growth.
And then you can just interactively ... So each of these filters out some of the places.
So you can look at ... I don't want high traffic density. I don't want any pollution. I don't want any crime. I want land value to be high.
I'm getting pretty picky. So maybe I'll deal with more people. Lower rate of growth. I'm too picky about pollution. I'm too picky about land value. That's it.
So basically, Ben Shneiderman demonstrated this as the "Dynamic Home Finder", and I realized that SimCity has all these layers of information that it can draw on, as fictitious as they are, to do that kind of real time, interactive, smooth database query.
It's just a much higher bandwidth way to query a database than is conventionally used.
Anyway, that was the dynamic zone finder.
Also: Here's some email I wrote to Ben about this article, after re-reading the article again in 2009:
Date: 28/02/2009 18:51 Subject: Re-reading "Beyond Intelligent Machines"
A long time ago, you sent us (me, Brad Myers, Jack Callahan and Mark Weiser) a preview of your IEEE Software article "Beyond Intelligent Machines", which I ran across and have re-read.
It's still delightful, inspiring and relevant today.
Speech synthesis and recognition has come a long way, to the point where the "talking car" scenario is quite common (TomToms that speak and recognize street names and addresses).
But I think the development of user-customizable user interfaces has been dreadfully stalled since HyperCard died.
An "Interactive Learning Environment" is a great description of what I'm developing SimCity into.
Remember when you visited CMU and I showed you the version of SimCity with the dynamic query feature, an "homage" to your Dynamic Home Finder? You could dial a series of filters on spatial properties like population density, pollution, traffic, land value, police coverage, etc. That code is now open source, and I'm redeveloping it!
It's now very easy to write Python code to dynamically query and filter the map and data layers, and visualize with transparent colored tiles and pixel overlays, depending on arbitrary Python functions over the state of the map and its data layers.
And it's also possible to script agents in Python!
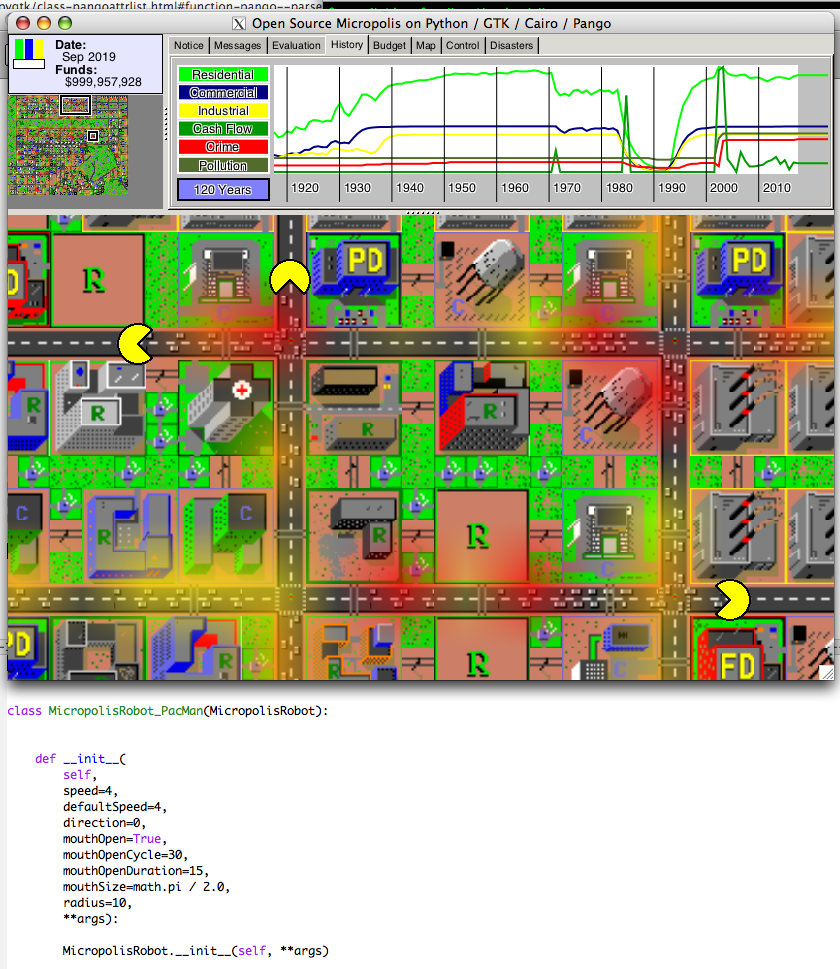
Here's a picture of SimCity with the traffic overlay enabled (showing yellow/orange/red haze over high traffic areas), with some PacMan agents, which are programmed to follow roads, go towards high traffic and eat the cars! Notice the clear road behind each PacMan!
http://www.donhopkins.com/home/images/SimCityPacMan.png
-Don
https://www.youtube.com/watch?v=8snnqQSI0GE
A demo of the open source Micropolis Online game (based on the original SimCity Classic source code from Maxis), running on a web server, written in C++ and Python, and displaying in a web browser, written in OpenLaszlo and JavaScript, running in the Flash player. Developed by Don Hopkins.
Source Code: https://github.com/SimHacker/micropolis
HAR 2009 talk: Constructionist Educational Open Source
https://medium.com/@donhopkins/har-2009-lightning-talk-trans...
benbendc on April 1, 2020 | next [–]
Thanks Don for that mention of the old paper, which is still on the right track. My new paper appeared on line Friday and will be temporarily freely accessible:
> Shneiderman, Ben (2020). Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy, International Journal of Human-Computer Interaction,36, 6 (Published Online March 27, 2020).
https://doi.org/10.1080/10447318.2020.1741118
https://arxiv.org/pdf/2002.04087
I have spent a year developing these ideas, but the evolution was dramatic, based on thoughtful feedback from the 25+ people mentioned in the Acknowledgements. Speaking at U-W, Stanford, UBC, NSF & ONR and elsewhere helped repeatedly reshape my arguments. All that commentary added to the journal editors’ confidence that this was an important paper, so they fast tracked reviews & production and gave it priority in the publication queue. Please send this link around to your colleagues, where appropriate.
Feedback welcome... Stay healthy... Ben
Oh wait, this is something FB/Goog could never do because what would it say about the quality of information hosted...
The 1992 talk wasn't at all about AI and since then our phones have given us "ubiquitous computing" en masse.
The original talk required no 'artificial intelligence' for relevance which makes it strange to apply to todays artificial intelligence.
The original talk made good points for instance "voice recognition" has been solved forever at a reasonable level, yet people kept claiming if it was 'better' a 'magic experience' would pop out as if voice was different to typing. Idiots have been around for a long time.
Don't get what OP is trying to say.
'AI HUD metaphors' are very hard, that's why they are not ubiquitous, they require constant input. Spellcheck runs every character typed. Agents are because of less $.
'Hallucinations' also make 'AI HUD metaphors' problematic, for spellcheck squiggly red lines would be blinking on off all over the page as a LLM keeps coming back with different results.
{kind=link}