It does sort of give me the vibe that the pure scaling maximalism really is dying off though. If the approach is on writing better routers, tooling, comboing specialized submodels on tasks, then it feels like there's a search for new ways to improve performance(and lower cost), suggesting the other established approaches weren't working. I could totally be wrong, but I feel like if just throwing more compute at the problem was working OpenAI probably wouldn't be spending much time on optimizing the user routing on currently existing strategies to get marginal improvements on average user interactions.
I've been pretty negative on the thesis of only needing more data/compute to achieve AGI with current techniques though, so perhaps I'm overly biased against it. If there's one thing that bothers me in general about the situation though, it's that it feels like we really have no clue what the actual status of these models is because of how closed off all the industry labs have become + the feeling of not being able to expect anything other than marketing language from the presentations. I suppose that's inevitable with the massive investments though. Maybe they've got some massive earthshattering model release coming out next, who knows.
The real typos were random missing letters. But the typos Gemini hallucinated were ones that are very common typos made in those words.
The only thing transformer based LLMs can ever do is _faking_ intelligence.
Which for many tasks is good enough. Even in my example above, the corrected text was flawless.
But for a whole category of tasks, LLMs without oversight will never be good enough because there simply is no real intelligence in them.
1) Build a directory of X (a gazillion) amount of tools (just functions) that models can invoke with standard pipeline behavior (parallel, recursion, conditions etc)
2) Solve the "too many tools to select from" problem (a search problem), adjacently really understand the intent (linguistics/ToM) of the user or agents request
3) Someone to pay for everything
4) ???
The future is already here in my opinion, the LLM's are good-enough™, it's just the ecosystem needs to catch up. Companies like Zapier or whatever, taken to their logical extreme, connecting any software to any thing (not just sass products), combined with an LLM will be able to do almost anything.
Even better basic tool composition around language will make it's simple replies better too.
This has some Egyptian pyramids building vibes. I hope we treat these AGIs better than the deal the pyramid slaves got.
You've posted substantive comments in other threads, so this should be easy to fix.
If you wouldn't mind reviewing https://news.ycombinator.com/newsguidelines.html and taking the intended spirit of the site more to heart, we'd be grateful.
> It does sort of give me the vibe that the pure scaling maximalism really is dying off though
Really though, why put all your eggs in one basket? That's what I've been confused about for awhile. Why fund yet another LLMs to AGI startup. Space is saturated with big players and has been for years. Even if LLMs could get there that doesn't mean something else won't get there faster and for less. It also seems you'd want a backup in order to avoid popping the bubble. Technology S-Curves and all that still apply to AI
Though I'm similarly biased, but so is everyone I know with a strong math and/or science background (I even mentioned it in my thesis more than a few times lol). Scaling is all you need just doesn't check out
I guess it makes sense, there is still tons of value to be created just by using the current LLMs for stuff, though maybe the low hanging fruits are already picked, who knows.
I heard John Carmack talk a lot about his alternative (also neuroscience-inspired) ideas and it sounded just like my project, the main difference being that he's able to self-fund :) I guess funding an "outsider" non-LLM AI project now requires finding someone like Carmack to get on board - I still don't think traditional investors are that disappointed yet that they want to risk money on other types of projects..
> I guess funding an "outsider" non-LLM AI project now requires finding someone like Carmack to get on board
I think a somewhat comparable situation is in various online game platforms now that I think about it. Investors would love to make a game like Fortnite, and get the profits that Fortnite makes. So a ton of companies try to make Fortnite. Almost all fail, and make no return whatsoever, just lose a ton of money and toss the game in the bin, shut down the servers.
On the other hand, it may have been more logical for many of them to go for a less ambitious (not always online, not a game that requires a high player count and social buy-in to stay relevant) but still profitable investment (Maybe a smaller scale single player game that doesn't offer recurring revenue), yet we still see a very crowded space for trying to emulate the same business model as something like Fortnite. Another more historical example was the constant question of whether a given MMO would be the next "WoW-killer" all through the 2000's/2010's.
I think part of why this arises is that there's definitely a bit of a psychological hack for humans in particular where if there's a low-probability but extremely high reward outcome, we're deeply entranced by it, and investors are the same. Even if the chances are smaller in their minds than they were before, if they can just follow the same path that seems to be working to some extent and then get lucky, they're completely set. They're not really thinking about any broader bubble that could exist, that's on the level of the society, they're thinking about the individual, who could be very very rich, famous, and powerful if their investment works. And in the mind of someone debating what path to go down, I imagine a more nebulous answer of "we probably need to come up with some fundamentally different tools for learning and research a lot of different approaches to do so" is a bit less satisfying and exciting than a pitch that says "If you just give me enough money, the curve will eventually hit the point where you get to be king of the universe and we go colonize the solar system and carve your face into the moon."
I also have to acknowledge the possibility that they just have access to different information than I do! They might be getting shown much better demos than I do, I suppose.
> I think a somewhat comparable situation is in various online game platforms
> psychological hack
I think that's the part that I find most interesting and confusing. It's like an aversion of wanting to look just one layer deeper. We'll put in far more physical and mental energy to justify a shallow thought than what would be required to think deeper. I get we're biased towards being lazy, so I think this is kinda related to us just being bad at foresight and feeling like being wrong is a bad thing (well it isn't good, but I'm pretty sure being wrong and not correcting is worse than just being wrong).
Venture capital is all about low-probability high-reward events.
Get a normal small business loan if you don't want to go big or go home.
Of course, if you limit your attention to these 'wanabe fortnites', then you only see these 'wannabe fortnites'.
I mean that's easy lol. People don't like to invest in thin air, which is what you get when you look at non-LLM alternatives to General Intelligence.
This isn't meant as a jab or snide remark or anything like that. There's literally nothing else that will get you GPT-2 level performance, never-mind an IMO Gold Medalist. Invest in what else exactly? People are putting their eggs in one basket because it's the only basket that exists.
>I think the big question is if/when investors will start giving money to those who have been predicting this (with evidence) and trying other avenues.
Because those people have still not been proven right. Does "It's an incremental improvement over the model we released a few months ago, and blows away the model we released 2 years ago." really scream, "See!, those people were wrong all along!" to you ?
> which is what you get when you look at non-LLM alternatives to General Intelligence.
On the other hand, investing in these alternatives is a lot cheaper, since you can work your way to scale and see what fails along the way. This is more like letting people try their stuff out in lower leagues. The problem is there's no ladder to climb after a certain point. If you can't fly then how do you get higher?
> Invest in what else exactly? ... it's the only basket that exists.
> Because those people have still not been proven right.
> scream, "See!, those people were wrong all along!" to you ?
I mean this is why I moved the bar down from state of the art.
I'm not saying there are no good ideas. I'm saying none of them have yet shown enough promise to be called another basket in it's own right. Open AI did it first because they really believed in scaling, but anyone (well not literally, but you get what I mean) could have trained GPT-2. You didn't need some great investment, even then. It's that level of promise I'm saying doesn't even exist yet.
>I guess the two most well known are Mamba and Flows.
I mean, Mamba is a LLM ? In my opinion, it's the same basket. I'm not saying it has to be a transformer or that you can't look for ways to improve the architecture. It's not like Open AI or Deepmind aren't pursuing such things. Some of the most promising tweaks/improvements - Byte Latent Transformer, Titans etc are from those top labs.
Flows research is intriguing but it's not another basket in the sense that it's not an alternative to the 'AGI' these people are trying to build.
> Let me ask you this. Suppose people are saying "x is wrong, I think we should do y instead" but you don't get funding because x is currently leading. Then a few years later y is proven to be the better way of doing things, everything shifts that way. Do you think the people who said y was right get funding or do you think people who were doing x but then just switched to y after the fact get funding? We have a lot of history to tell us the most common answer...
The funding will go to players positioned to take advantage. If x was leading for years then there was merit in doing it, even if a better approach came along. Think about it this way, Open AI now have 700M Weekly active users for ChatGPT and millions of API devs. If this superior y suddenly came along and materialized and they assured you there were pivoting, why wouldn't you invest in them over players starting from 0, even if they championed y in the first place? They're better positioned to give you a better return on your money. Of course, you can just invest in both.
Open AI didn't get nearly a billion weekly active users off the promise of future technology. They got it with products that exist here and now. Even if there's some wall, this is clearly a road with a lot of merit. The value they've already generated (a whole lot) won't disappear if LLMs don't reach the heights some people are hoping they will.
If you want people to invest in y instead then x has to stall or y has to show enough promise. It didn't take transformers many years to embed themselves everywhere because they showed a great deal of promise right from the beginning. It shouldn't be surprising if people aren't rushing to put money in y when neither has happened yet.
> I'm saying none of them have yet shown enough promise to be called another basket in it's own right.
I know that's one sentence, but I think it is the most important one in my reply. It is really what everything else comes down to. There's a lot of room between even academic scale and industry scale. There's very few things with papers in the middle.
> I mean, Mamba is a LLM
Though with that, I'd still disagree that LLMs will get us to AGI. I think the whole world is agreeing too as we're moving into multimodal models (sometimes called MMLMs) and so I guess let's use that terminology.
To be more precise, let's say "I think there are better architectures out there than ones dominated by Transformer Encoders". It's a lot more cumbersome but I don't want to say transformers or attention can't be used anywhere in the model or we'll end up having to play this same game. Let's just work with "an architecture that is different than what we usually see in existing LLMs". That work?
> The funding will go to players positioned to take advantage.
To be clear my argument isn't "don't put all your money in the 'LLM' basket, put it in this other basket" by argument is "diversify" and "diversification means investing at many levels of research." To clarify that latter part I really like the NASA TRL scale[0]. It's wrong to make a distinction between "engineering vs research" and better to see it as a continuum. I agree, most money should be put into higher levels but I'd be amiss if I didn't point out that we're living in a time where a large number of people (including these companies) are arguing that we should not be funding TRL 1-3 and if we're being honest, I'm talking about stuff in currently in TRL 3-5. I mean it is a good argument to make if you want to maintain dominance, but it is not a good argument if you want to continue progress (which I think is what leads to maintaining dominance as long as that dominance isn't through monopoly or over centralization). Yes, most of the lower level stuff fails. But luckily the lower level stuff is much cheaper to fund. A mathematician's salary and a chalk board is at least half as expensive as the salary of a software dev (and probably closer to a magnitude if we're considering the cost of hiring either of them).
But I think that returns us to the main point: what is that threshold?
My argument is simply "there should be no threshold, it should be continuous". I'm not arguing for a uniform distribution either, I explicitly said more to higher TRLs. I'm arguing that if you want to build a house you shouldn't ignore the foundation. And the fancier the house, the more you should care about the foundation. Least you risk it all falling down
[0] https://www.nasa.gov/directorates/somd/space-communications-...
Something like GPT-2. Something that even before being actually useful or particularly coherent, was interesting enough to spark articles like these. https://slatestarcodex.com/2019/02/19/gpt-2-as-step-toward-g... So far, only LLM/LLM adjacent stuff fulfils this criteria.
To be clear, I'm not saying general R&D must meet this requirement. Not at all. But if you're arguing about diverting millions/billions in funds from x that is working to y then it has to at least clear that bar.
> My argument is simply "there should be no threshold, it should be continuous".
I don't think this is feasible for large investments. I may be wrong, but i also don't think other avenues aren't being funded. They just don't compare in scale because....well they haven't really done anything to justify such scale yet.
> Something like GPT-2
1) There's plenty of things that can achieve similar performance to GPT-2 these days. We mentioned Mamba, they compared to GPT-3 in their first paper[0]. They compare with the open sourced version and you'll also see some other architectures referenced there like Hyena and H3. It's the GPT-Neo and GPT-J models. Remember GPT-3 is pretty much just a scaled up GPT-2.
2) I think you are underestimating the costs to train some of these things. I know Karpathy said you can now train GPT-2 for like $1k[1] but a single training run is a small portion of the total costs. I'll reference StyleGAN3 here just because the paper has good documentation on the very last page[2]. Check out the breakdown but there's a few things I want to specifically point out. The whole project cost 92 V100 years but the results of the paper only accounted for 5 of those. That's 53 of the 1876 training runs. Your $1k doesn't get you nearly as far as you'd think. If we simplify things and say everything in that 5 V100 years cost $1k then that means they spent $85k before that. They spent $18k before they even went ahead with that project. If you want realistic numbers, multiply that by 5 because that's roughly what a V100 will run you (discounted for scale). ~$110k ain't too bad, but that is outside the budget of most small labs (including most of academia). And remember, that's just the cost of the GPUs, that doesn't pay for any of the people running that stuff.
I don't expect you to know any of this stuff if you're not a researcher. Why would you? It's hard enough to keep up with the general AI trends, let alone niche topics lol. It's not an intelligence problem, it's a logistics problem, right? A researcher's day job is being in those weeds. You just get a lot more hours in the space. I mean I'm pretty out of touch of plenty of domains just because time constraints.
> I don't think this is feasible for large investments. I may be wrong, but i also don't think other avenues aren't being funded.
And I think if we are actually looking at the numbers, yeah, I do not think these avenues are being funded. But don't take it from me, take it from FeiFei Li[3]
| Not a single university today can train a ChatGPT model
But if you aren't a researcher I'd ask why you have such confidence that these things are being funded and that these things cannot be scaled or improved[4]. History is riddled with examples of inferior tech winning mostly due to marketing. I know we get hyped around new tech, hell, that's why I'm a researcher. But isn't that hype a reason we should try to address this fundamental problem? Because the hype is about the advance of technology, right? I really don't think it is about the advancement of a specific team, so if we have the opportunity for greater and faster advancement, isn't that something we should encourage? Because I don't understand why you're arguing against that. An exciting thing of working at the bleeding edge is seeing all the possibilities. But a disheartening thing about working at the bleeding edge is seeing many promising avenues be passed by for things like funding and publicity. Do we want meritocracy to win out or the dollar?
I guess you'll have to ask yourself: what's driving your excitement?
[0] I mean the first Mamba paper, not the first SSM paper btw: https://arxiv.org/abs/2312.00752
[1] https://github.com/karpathy/llm.c/discussions/677
[2] https://arxiv.org/abs/2106.12423
[3] https://www.ft.com/content/d5f91c27-3be8-454a-bea5-bb8ff2a85...
[4] I'm not saying any of this stuff is straight de fact better. But there definitely is an attention imbalance and you have to compare like to like. If you get to x in 1000 man hours and someone else gets there in 100, it may be worth taking a look deeper. That's all.
Funding multiple startups means _not_ putting your eggs in one basket, doesn't it?
Btw, do we have any indication that eg OpenAI is restricting themselves to LLMs?
> Funding multiple startups means _not_ putting your eggs in one basket, doesn't it?
Also, yes. They state this and given how there are plenty of open source models that are LLMs and get competitive performance it at least indicates that anyone not doing LLMs is doing so in secret.
If OpenAI isn't using LLMs then doesn't that support my argument?
If your expectations were any higher than that then, then it seems like you were caught up in hype. Doubling 2-3 times per year isn't leveling off my any means.
Rather than my personal opinion, I was commenting on commonly viewed opinions of people I would believe to have been caught up in hype in the past. But I do feel that although that's a benchmark, it's not necessarily the end-all of benchmarks. I'll reserve my final opinions until I test personally, of course. I will say that increasing the context window probably translates pretty well to longer context task performance, but I'm not entirely convinced it directly translates to individual end-step improvement on every class of task.
It is a benchmark but I'm not very convinced it's the be-all, end-all.
Who's suggesting it is?
In the meantime, figuring out how to train them to make less of their most common mistakes is a worthwhile effort.
The interesting point as well to me though, is that if it could create a startup that was worth $1B, that startup wouldn't be worth $1B.
Why would anyone pay that much to invest in the startup if they could recreate the entire thing with the same tool that everyone would have access to?
"Within one year" is the key part. The product is only part of the equation.
If a startup was launched one year ago and is worth $1B today, there is no way you can launch the same startup today and achieve the same market cap in 1 day. You still need customers, which takes time. There are also IP related issues.
Facebook had the resources to create an exact copy of Instagram, or WhatsApp, but they didn't. Instead, they paid billions of dollars to acquire those companies.
"If you could just ask GPT to create a startup that'll be guaranteed to be worth $1B on a $1k investment within one year"
I think if the situation is that I do this by just asking it to make a startup, it seems unlikely that no one else would be aware that they could just ask it to make a startup
Compared to the GPT-4 release which was a little over 2 years ago (less than the gap between 3 and 4), it is. The only difference is we now have multiple organizations releasing state of the art models every few months. Even if models are improving at the same rate, those same big jumps after every handful of months was never realistic.
It's an incremental stable improvement over o3, which was released what? 4 months ago.
There's gains, but the question is, how much investment for that gain? How sustainable is that investment to gain ratio? The things I'm curious about here are more about the amount of effort being put into this level of improvement, rather than the time.
At this point it's pretty much given it's a game of inches moving forward.
According to the article, GPT-5 is actually three models and they can be run at 4 levels of thinking. Thats a dozen ways you can run any given input on "GPT-5", so its hardly a simple product line up (but maybe better than before).
It's even more simplified for the ChatGPT plan, It's just GPT-5 thinking/non-thinking for most accounts, and then the option of Pro for the higher end accounts.
I'd expect that at some level of reliability this could lead to a self-improvement cycle, similar to how a powerful enough model (the Claude 4 models in Claude Code) enables iteratively converging on a solution to a problem even if it can't one-shot it.
No idea if we're at that point yet, but it seems a natural use for a model with these characteristics.
> but given the types of things people have been saying GPT-5 would be for the last two years
Are you trying to say the curve is flattening? That advances are coming slower and slower?
As long as it doesn't suggest a dot com level recession I'm good.
But I do think the fact that we can publicly observe this reallocation of resources and emphasized aspects of the models gives us a bit of insight into what could be happening behind the scenes if we think about the reasons why those shifts could have happened, I guess.
So yeah, maybe we are getting more incremental improvements. But that to me seems like a good thing, because more good things earlier. I will take that over world-shattering any day – but if we were to consider everything that has happened since the first release of gpt-4, I would argue the total amount is actually very much world-shattering.
The common concept for AGI seems to be much more about human replacement - the ability to complete "economically valuable tasks" better than humans can. I still don't understand what our human lives or economies would look like there.
What I personally wanted from GPT-5 is exactly what I got: models that do the same stuff that existing models do, but more reliably and "better".
That's pretty much the key component these approaches have been lacking on, the reliability and consistency on the tasks they already work well on to some extent.
I think there's a lot of visions of what our human lives would look like in that world that I can imagine, but your comment did make me think of one particularly interesting tautological scenario in that commonly defined version of AGI.
If artificial general intelligence is defined as completed "economically valuable tasks" better than human can, it requires one to define "economically valuable." As it currently stands, something holds value in an economy relative to human beings wanting it. Houses get expensive because many people, each of whom have economic utility which they use to purchase things, want to have houses, of which there is a limited supply for a variety of reasons. If human beings are not the most effective producers of value in the system, they lose capability to trade for things, which negates that existing definition of economic value. Doesn't matter how many people would pay $5 dollars for your widget if people have no economic utility relative to AGI, meaning they cannot trade that utility for goods.
In general that sort of definition of AGI being held reveals a bit of a deeper belief, which is that there is some version of economic value detached from the humans consuming it. Some sort of nebulous concept of progress, rather than the acknowledgement that for all of human history, progress and value have both been relative to the people themselves getting some form of value or progress. I suppose it generally points to the idea of an economy without consumers, which is always a pretty bizarre thing to consider, but in that case, wouldn't it just be a definition saying that "AGI is achieved when it can do things that the people who control the AI system think are useful." Since in that case, the economy would eventually largely consist of the people controlling the most economically valuable agents.
I suppose that's the whole point of the various alignment studies, but I do find it kind of interesting to think about the fact that even the concept of something being "economically valuable", which sounds very rigorous and measurable to many people, is so nebulous as to be dependent on our preferences and wants as a society.
Nothing in the current technology offers a path to AGI. These models are fixed after training completes.
You could maybe accomplish this if you could fit all new information into context or with cycles of compression but that is kinda a crazy ask. There's too much new information, even considering compression. It certainly wouldn't allow for exponential growth (I'd expect sub linear).
I think a lot of people greatly underestimate how much new information is created every day. It's hard if you're not working on any research and seeing how incremental but constant improvement compounds. But try just looking at whatever company you work for. Do you know everything that people did that day? It takes more time to generate information than process information so that's on you side, but do you really think you could keep up? Maybe at a very high level but in that case you're missing a lot of information.
Think about it this way: if that could be done then LLM wouldn't need training or tuning because you could do everything through prompting.
I’m not saying this is a realistic or efficient method to create AGI, but I think the argument „Model is static once trained -> model can’t be AGI“ is fallacious.
You're right, you don't technically need infinite, but we are still talking about exponential growth and I don't think that effectively changes anything.
> the model can remember stuff as long as it’s in the context.
Also you might be interested in this theorem
Only if AGI would require infinite knowledge, which it doesn’t.
> Humans have General Intelligence while having a context window
I think your argument makes sense, but is over simplifying the human brain. I think once we start considering the complexity then this no longer makes sense. It is also why a lot of AGI research is focused on things like "test time learning" or "active learning", not to mention many other areas including dynamic architectures.
LLMs might look “creative” but they are just remixing patterns from their training data and what is in the prompt. They cant actually update themselves or remember new things after training as there is no ongoing feedback loop.
This is why you can’t send an LLM to medical school and expect it to truly “graduate”. It cannot acquire or integrate new knowledge from real-world experience the way a human can.
Without a learning feedback loop, these models are unable to interact meaningfully with a changing reality or fulfill the expectation from an AGI: Contribute to new science and technology.
Basically, I wouldn’t say that an LLM can never become AGI due to its architecture. I also am not saying that LLM will become AGI (I have no clue), but I don’t think the architecture itself makes it impossible.
So yeah, AGI is impossible with today LLMs. But at least we got to watch Sam Altman and Mira Murati drop their voices an octave onstage and announce “a new dawn of intelligence” every quarter. Remember Sam Altman 7 trillion?
Now that the AGI party is over, its time to sell those NVDA shares and prepare for the crash. What a ride it was. I am grabbing the popcorn.
And later, Windows reverted to version numbers; but I'm not sure they regained lots of innovation?
If you want actual big moves, watch google, anthropic, qwen, deepseek.
Qwen and Deepseek teams honestly seem so much better at under promising and over delivering.
Cant wait to see what Gemini 3 looks like too.
This has me so confused, Claude 4 (Sonnet and Opus) hallucinates daily for me, on both simple and hard things. And this is for small isolated questions at that.
So not seeing them means either lying or incompetent. I always try to attribute to stupidity rather than malice (Hanlon's razor).
The big problem of LLMs is that they optimize human preference. This means they optimize for hidden errors.
Personally I'm really cautious about using tools that have stealthy failure modes. They just lead to many problems and lots of wasted hours debugging, even when failure rates are low. It just causes everything to slow down for me as I'm double checking everything and need to be much more meticulous if I know it's hard to see. It's like having a line of Python indented with an inconsistent white space character. Impossible to see. But what if you didn't have the interpreter telling you which line you failed on or being able to search or highlight these different characters. At least in this case you'd know there's an error. It's hard enough dealing with human generated invisible errors, but this just seems to perpetuate the LGTM crowd
Yeah, it's seems to be a terrible approach to try to "correct" the context by adding clarifications or telling it what's wrong.
Instead, start from 0 with the same initial prompt you used, but improve it so the LLM gets it right in the first response. If it still gets it wrong, begin from 0 again. The context seems to be "poisoned" really quickly, if you're looking for accuracy in the responses. So better to begin from the beginning as soon as it veers off course.
The grand-parent comment was pointing out that this limitation exists; not that it can't be worked around.
If the question is about harder facts which the human disagrees with, this may put it into an essentially self-contradictory state, where the locus of possibilitie gets squished from each direction, and so the model is forced to respond with crazy outliers which agree with both the human and the data. The probability of an invented reference being true may be very low, but from the model's perspective, it may still be one of the highest probability outputs among a set of bad choices.
What it sounds like they may have done is just have the humans tell it it's wrong when it isn't, and then award it credit for sticking to its guns.
Fucking Gemini Pro on the other hand digs in, and starts deciding it's in a testing scenario and get adversarial, starts claiming it's using tools the user doesn't know about, etc etc
Often the hallucinations I see are subtle, though usually critical. I see it when generating code, doing my testing, or even just writing. There are hallucinations in today's announcements, such as the airfoil example[0]. An example of more obvious hallucinations is I was asking for help improving writing an abstract for a paper. I gave it my draft and it inserted new numbers and metrics that weren't there. I tried again providing my whole paper. I tried again making explicit to not add new numbers. I tried the whole process again in new sessions and in private sessions. Claude did better than GPT 4 and o3 but none would do it without follow-ups and a few iterations.
Honestly I'm curious what you use them for where you don't see hallucinations
[0] which is a subtle but famous misconception. One that you'll even see in textbooks. Hallucination probably caused by Bernoulli being in the prompt
For factual information I only ever use search-enabled models like o3 or GPT-4.
Most of my other use cases involve pasting large volumes of text into the model and having it extract information or manipulates that text in some way.
> using them for code
> For factual information
> Most of my other use cases
Maybe I'm misinterpreting your claim? You said "I rarely see them" but I'm assuming you mean more, and I think it would be reasonable for anyone to interpret this as more. Are you just making the claim that you don't see them or making a claim that they are uncommon? The latter is what I interpreted.
It might be using it wrong but I'd qualify that as a bug or mistake, not a hallucination.
Is it likely we have different ideas of what "hallucination" means?
So you're not seeing hallucinations in the same way that Van Halen isn't seeing the brown M&Ms, because they've been removed, it's not that they never existed.
> tests wouldn't be protection against most forms of hallucinations.
My claim is more along the lines of "passing tests doesn't mean your code is bug free" which I think we can all agree on is a pretty mundane claim?
> Is it likely we have different ideas of what "hallucination" means?
TDD works pretty well, have it write even the most basic test (or go full artisanal and write it yourself) first and then ask it to implement the code.
I have a standing order in my main CLAUDE.md to "always run `task build` before claiming a task is done". All my projects use Task[0] with pretty standard structure where build always runs lint + test before building the project.
With a semi-robust test suite I can be pretty sure nothing major broke if `task build` completes without errors.
>Looking through the document, I can identify several instances where it's written in the first person:
And it went on to show a series of "they/them" statements. I asked it to clarify if "they" is "first person" and it responded
>No, "they" is not first person - it's third person. I made an error in my analysis. First person would be: I, we, me, us, our, my. Second person would be: you, your. Third person would be: he, she, it, they, them, their. Looking back at the document more carefully, it appears to be written entirely in third person.
Even the good models are still failing at real-world use cases which should be right in their wheelhouse.
Could you give an estimate of how many "dumb errors" you've encountered, as opposed to hallucinations? I think many of your readers might read "hallucination" and assume you mean "hallucinations and dumb errors".
I haven't been keeping a formal count of them, but dumb errors from LLMs remain pretty common. I spot them and either correct them myself or nudge the LLM to do it, if that's feasible. I see that as a regular part of working with these systems.
As a user, when the model tells me things that are flat out wrong, it doesn't really matter whether it would be categorized as a hallucination or a dumb error. From my perspective, those mean the same thing.
It's hard to know why it made the error but isn't it caused by inaccurate "world" modeling? ("World" being English language) Is it not making some hallucination about the English language while interpreting the prompt or document?
I'm having a hard time trying to think of a context where "they" would even be first person. I can't find any search results though Google's AI says it can. It provided two links, the first being a Quora result saying people don't do this but framed it as it's not impossible, just unheard of. Second result just talks about singular you. Both of these I'd consider hallucinations too as the answer isn't supported by the links.
I just got pointed to this new paper: https://arxiv.org/abs/2508.01781 - "A comprehensive taxonomy of hallucinations in Large Language Models" - which has a definition in the introduction which matches my mental model:
"This phenomenon describes the generation of content that, while often plausible and coherent, is factually incorrect, inconsistent, or entirely fabricated."
The paper then follows up with a formal definition;
"inconsistency between a computable LLM, denoted as h, and a computable ground truth function, f"
| AI hallucinations are incorrect or misleading results that AI models generate.
> this new paper
> then follows up with a formal definition
| an LLM h is considered to be ”hallucinating” with respect to a ground truth function f if, across all training stages i (meaning, after being trained on any finite number of samples), there exists at least one input string s for which the LLM’s output h[i](s) does not match the correct output f (s)[100]. This condition is formally expressed as ∀i ∈ N, ∃s ∈ S such that h[i](s)̸ = f (s).
[0] https://cloud.google.com/discover/what-are-ai-hallucinations
I usually use an agentic workflow and "hallucination" isn't the first word that comes to my mind when a model unloads a pile of error-ridden code slop for me to review. Despite it being entirely possible that hallucinating a non-existent parameter was what originally made it go off the rails and begin the classic loop of breaking things more with each attempt to fix it.
Whereas for AI autocomplete/suggestions, an invented method name or argument or whatever else clearly jumps out as a "hallucination" if you are familiar with what you're working on.
https://finance.yahoo.com/news/enterprise-llm-spend-reaches-...
Their PRO models were not (IMHO) worth 10X that of PLUS!
Not even close.
Especially when new competitors (eg. z.ai) are offering very compelling competition.
They have confessed to doing a bad thing - training on copyrighted data without permission. Why does that indicate they would lie about a worse thing?
Because they know their audience. It's an audience that also doesn't care for copyright and would love for them to win their court cases. They are fineaking such an argument to those kinds of people.
Meanwhile, the reaction from the same audience when legal did a very typical subpoena process on said data, data they chose to submit to an online server of their own volition, completely freaked out. Suddenly, they felt like their privacy was invaded.
It doesn't make any logical sense in my mind, but a lot of the discourse over this topic isnt based on logic.
Is it actually simpler? For those who are currently using GPT 4.1, we're going from 3 options (4.1, 4.1 mini and 4.1 nano) to at least 8, if we don't consider gpt 5 regular - we now will have to choose between gpt 5 mini minimal, gpt 5 mini low, gpt 5 mini medium, gpt 5 mini high, gpt 5 nano minimal, gpt 5 nano low, gpt 5 nano medium and gpt 5 nano high.
And, while choosing between all these options, we'll always have to wonder: should I try adjusting the prompt that I'm using, or simply change the gpt 5 version or its reasoning level?
But the specific nuance of picking nano/mini/main and minimal/low/medium/high comes down to experimentation and what your cost/latency constraints are.
Not really that mich simpler.
Trying to get an accurate answer (best correlated with objective truth) on a topic I don't already know the answer to (or why would I ask?). This is, to me, the challenge with the "it depends, tune it" answers that always come up in how to use these tools -- it requires the tools to not be useful for you (because there's already a solution) to be able to do the tuning.
If you have a task you do frequently you need some kind of benchmark. Which might just be comparing how good the output of the smaller models holds up to the output of the bigger model, if you don't know the ground truth
With the API, you pick a model sizes and reasoning effort. Yes more choices, but also a clear mental model and a simple choice that you control.
Open source is years ahead of these guys on samplers. It's why their models being so good is that much more impressive.
> As recently as June, the technical problems meant none of OpenAI’s models under development seemed good enough to be labeled GPT-5, according to a person who has worked on it.
But it could be that this refers to post-training and the base model was developed earlier.
https://www.theinformation.com/articles/inside-openais-rocky...
AI labs gather training data and then do a ton of work to process it, filter it etc.
Model training teams run different parameters and techniques against that processed training data.
It wouldn't surprise me to hear that OpenAI had collected data up to September 2024, dumped that data in a data warehouse of some sort, then spent months experimenting with ways to filter and process it and different training parameters to run against it.
They used to be more about the training process itself, but that's increasingly secretive these days.
Would been interesting to see a comparison between low, medium and high reasoning_effort pelicans :)
When I've played around with GPT-OSS-120b recently, seems the difference in the final answer is huge, where "low" is essentially "no reasoning" and with "high" it can spend seemingly endless amount of tokens. I'm guessing the difference with GPT-5 will be similar?
Yeah, I'm working on that - expect dozens of more pelicans in a later post.
Not massively off -- manifold yesterday implied odds this low were ~35%. 30% before Claude Opus 4.1 came out which updated expected agentic coding abilities downward.
SamA has been promising AGI next year for three years like Musk has been promising FSD next year for the last ten years.
IDK what "people" are expecting but with the amount of hype I'd have to guess they were expecting more than we've gotten so far.
The fact that "fast takeoff" is a term I recognize indicates that some people believed OpenAI when they said this technology (transformers) would lead to sci fi style AI and that is most certainly not happening
Has he said anything about it since last September:
>It is possible that we will have superintelligence in a few thousand days (!); it may take longer, but I’m confident we’ll get there.
This is, at an absolute minimum, 2000 days = 5 years. And he says it may take longer.
Did he even say AGI next year any time before this? It looks like his predictions were all pointing at the late 2020s, and now he's thinking early 2030s. Which you could still make fun of, but it just doesn't match up with your characterization at all.
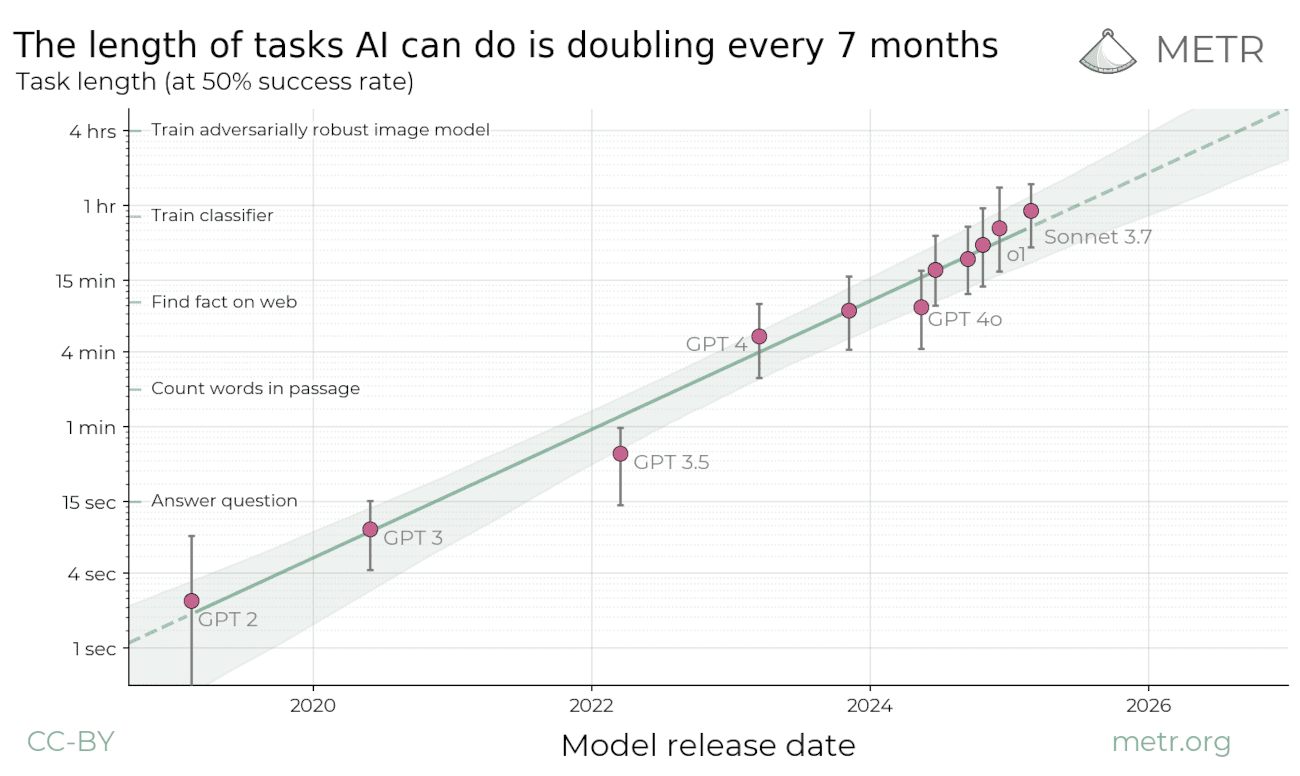
> propose measuring AI performance in terms of the length of tasks AI agents can complete.
Not that hard to figure out but the way people refer were referring to them made me think it stood for an actual metric.
This is sort of interesting to me. It strikes me that so far we've had more or less direct access to the underlying model (apart from the system prompt and guardrails), but I wonder if going forward there's going to be more and more infrastructure between us and the model.
OPENAI_DEFAULT_MODEL=gpt-5 codex> -------------------------------
"reasoning": {"summary": "auto"} }'
Here’s the response from that API call.
https://gist.github.com/simonw/1d1013ba059af76461153722005a0...
Without that option the API will often provide a lengthy delay while the model burns through thinking tokens until you start getting back visible tokens for the final response.
> and minimizing sycophancy
Now we're talking about a good feature! Actually one of my biggest annoyances with Cursor (that mostly uses Sonnet).
"You're absolutely right!"
I mean not really Cursor, but ok. I'll be super excited if we can get rid of these sycophancy tokens.
The price should be compared to Opus, not Sonnet.
No mention about the (missing) elephant on the room, where are the benchmarks?
@simonw has been compromised. Sad.
or even: https://github.com/sst/opencode
Not affiliated with either one of these, but they look promising.
right :-D
{kind=link}