Counterpoint - no it isn't.
The NP arguments are dumb and have nothing to do with thinking. I don't think Einstein was NP complete but could still think.
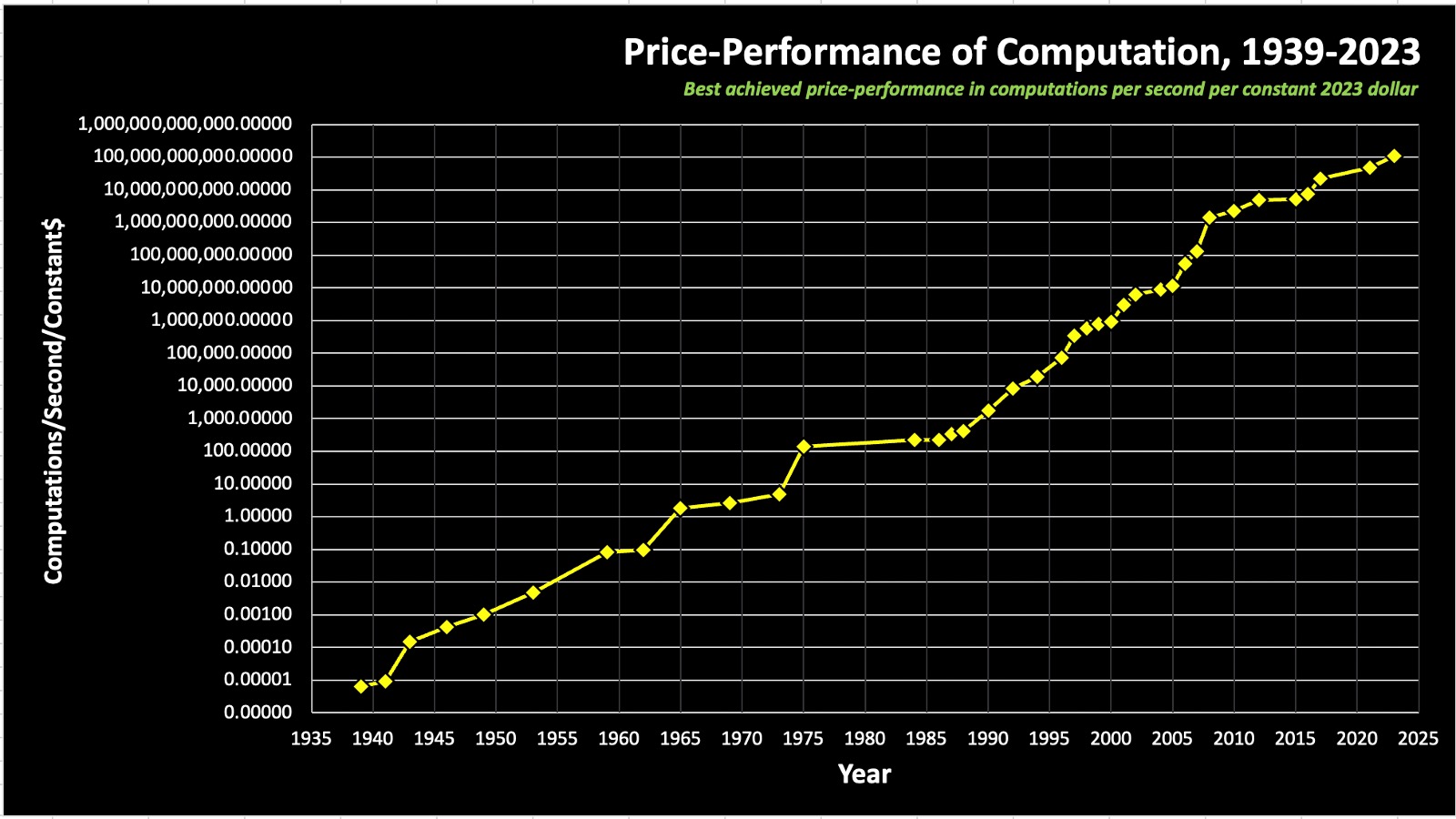
Winter summer implies sine wave like progress but what we are seeing now is a result of exponential growth in computer hardware such that it is now passing human equivalent levels https://www.bvp.com/assets/uploads/2024/03/price-performance...
LLMs having failings is a blip. Hinton got his nobel prize for work done in the 1980s but we are seeing AI takeoff now 45 years later, almost exactly when predicted by the likes of Moravec/Kurweil because of the hardware progress.
The argument that computational complexity has something to do with this could have merit but the article certainly doesn’t give indication as to why. Is the brain NP complete? Maybe maybe not. I could see many arguments about why modern research will fail to create AGI but just hand waving “reality is NP-hard” is not enough.
The fact is: something fundamental has changed that enables a computer to pretty effectively understand natural language. That’s a discovery on the scale of the internet or google search and shouldn’t be discounted… and usage proves it. In 2 years there is a platform with billions of users. On top of that huge fields of new research are making leaps and bounds with novel methods utilizing AI for chemistry, computational geometry, biology etc.
It’s a paradigm shift.
A steel man argument for why winter might be coming is all the dumb stuff companies are pushing AI for. On one hand (and I believe this) we argue it’s the most consequential technology in generations. On the other, everybody is using it for nonsense like helping you write an email that makes you sound like an empty suit, or providing a summary you didn’t ask for.
There’s still a ton of product work to cross whatever that valleys called between concept and product, and if that doesn’t happen, money is going to start disappearing. The valuation isn’t justified by the dumb stuff we do with it, it needs PMF.
I vividly remember sitting there for literally hours talking to a computer on launch day, it was a very short night. This feeling of living in the future has not left me since, it's got quieter, but it's still there. It's still magic after those three years, perhaps even more so. It wasn't supposed to work this well for decades! and yet.
3 things we know about the AI revolution in 2025:
- LLMs are amazing, but they have reached a plateau. AGI is not within reach.
- LLM investment has sacrificed many hundreds of billions of dollars, much of it from the world's pension funds.
- There is no credible path to a high-margin LLM product. Margins will be razor-thin positive at best once the free trial of the century starts to run out of steam.
This all adds up to a rather nasty crunch.
The thing about winter, though, is that it's eventually followed by another summer.
you should look at benchmarks such as ARC which went from "needs 10 years, currently at 0%" to almost solved within the least year. Also there is a revolution happening in math which the layman might be missing.
It's not about how good or useful or potentially lucrative the technology is. Every previous catalyst for an AI winter has eventually become pervasive, changed the world, and made some people a lot of money. Every single one. And I do mean pervasive. If you could poof just one of them out of existence, my cell phone would become noticeably less useful.
What it's really about is how hype cycles interact with funding for basic research.
I personally believe contemporary AI is over-hyped, but I cannot say with confidence that it is going to lead to a similar winter as the last time. It seems like today's products satisfy enough users to remain as a significant area, even if it doesn't greatly expand...
The only way I could see it fizzling as a product category is if it turns out it is not economically feasible to operate a sustainable service. Will users pay a fair price to keep the LLM datacenters running, without speculative investment subsidies?
The other aspect of the winter is government investment, rather than commercial. What could the next cycle of academic AI research look like? E.g. exploration that needs to happen in grant-funded university labs instead of venture-funded companies?
The federal funding picture seems unclear, but that's true across the board right now for reasons that have nothing to do with AI per se.
But the consumer's is not the important perspective for the AI hype cycle. It's the investors' perspective. I'm going to guess that well over a trillion dollars has gone into "AI", including the major labs and all the little "agents for XYZ" startups popping up every day. From the investors' perspective, that better pay off several times over in profit, not revenue, in the next few years. Prices will go up, but competition is fierce and nobody will be able to command a high margin. How are they going to make trillions in profit with razor thin margins?
This will make the very mention of "AI" toxic for most investors sooner than later.
I'm not so sure. I agree about the exceptionally off the charts expectations rivaling only the dotcom bubble, but with the current rate of progress I'd expect AI to be pervasive enough to disappear from investor relationship materials not because it's a buzzword, but because it's assumed to be incorporated just like companies don't mention that they're running Linux servers; companies saying that they're doing stuff without AI will be something to watch for.
> - LLMs are amazing, but they have reached a plateau. AGI is not within reach.
Source/citation?
People said the same thing about ELIZA in 1967.
OP says it is because that predicting the next token can be correct or not, but it always looks plausible because that is what it calculates. Therefore it is dangerous and can not be fixed because it is how it works in essence.
Literally yesterday ChatGPT hallucinated an entire feature of a mod for a video game I am playing including making up a fake console command.
It just straight up doesn’t exist, it just seemed like a relatively plausible thing to exist.
This is still happening. It never stopped happening. I don’t even see a real slowdown in how often it happens.
It sometimes feels like the only thing saving LLMs are when they’re forced to tap into a better system like running a search engine query.
My hit/miss rate with using these models for academic questions is low, but non-trivial. I've definitely learned new math because of using them, but it's really just an indulgence because they make stuff up so frequently.
Maybe I should have asked it to write a patch that implements that feature.
The response to your query might not be what you needed, similar to interacting with an RDBMS and mistyping a table name and getting data from another table or misremembering which tables exist and getting an error. We would not call such faults "hallucinations", and shouldn't when the database is a pile of eldritch vectors either. If we persist in doing so we'll teach other people to develop dangerous and absurd expectations.
The illusion of determinism in RDBMS systems is just that, an illusion. The reason why I used the examples of failures in interacting with such systems that I did is that most experienced developers are familiar with those situations and can relate to them, while the probability for the reader to having experienced a truer apparent indeterminism is lower.
LLM:s can provide an illusion of determinism as well, some are quite capable of repeating themselves, e.g. overfitting, intentional or otherwise.
But the point is that everyone uses the phrase "hallucinations" and language is just how people use it. In this forum at least, I expect everyone to understand that it is simply the result of next token generation and not an edge case failure mode.
It hallucinates whole lives out of nothing but stereotypes.
This is actually very profound. All free models are only reasonable if they scrape 100 web pages (according to their own output) before answering. Even then they usually have multiple errors in their output.
The model expected a feature to exist because it fitted with the overall structure of the interface.
This in itself can be a valuable form of feedback. I currently don't know of any people doing it, but testing interfaces by getting LLMs to use them could be an excellent resource. Th the AI runs into trouble, it might be worth checking your designs to see if you have any inconsistencies, redundancies or other confusion causing issues.
One would assume that a consistent user interface would be easier for both AI and humas. Fixing the issues would improve it for both.
That failure could be leveraged into an automated process that identified areas to improve.
Here, the investors are investing in LLMs. Not in AlphaFold, AlphaGo, neurosymbolic, focus learning, etc. If (when) LLMs prove insufficient to the insane level of hype and if (when) experience shows that there is only so much money that you can make with LLMs, it's possible that the money will move on to other types of AI, but there are chances that it will actually go to something entirely different, perhaps quantum, leaving AI in winter.
I'd argue that it pretty effectively mimics natural language. I don't think it really understands anything, it is just the best madlibs generator that the world has ever seen.
For many tasks, this is accurate 99+% of the time, and the failure cases may not matter. Most humans don't perform any better, and arguably regurgitate words without understanding as well.
But if the failure cases matter, then there is no actual understanding and the language the model is generating isn't ever getting "marked to market/reality" because there's no mental world model to check against. That isn't going to be usable if there are real-world consequences of the LLM getting things wrong, and they can wind up making very basic mistakes that humans wouldn't make--because we can innately understand how the world works and aren't always just stringing words together that sound good.
The pace of investment in the last 2 years has been so insane that even Altman has claimed that it's a bubble.
You understand how the tech works right? It's statistics and tokens. The computer understands nothing. Creating "understanding" would be a breakthrough.
Edit: I wasn't trying to be a jerk. I sincerely wasn't. I don't "understand" how LLMs "understand" anything. I'd be super pumped to learn that bit. I don't have an agenda.
I would say that, except for the observable and testable performance, what else can you say about understanding?
It is a fact that LLMs are getting better at many tasks. From their performance, they seem to have an understanding of say python.
The mechanistic way this understanding arises is different than humans.
How can you say then it is 'not real', without invoking the hard problem of consciousness, at which point, we've hit a completely open question.
“Do chairs exist?”:
When I ask it to use a specific MCP to complete a certain task, and it proceeds to not use that MCP, this indicates a clear lack of understanding.
You might say that the fault was mine, that I didn't setup or initialize the MCP tool properly, but wouldn't an understanding AI recognize that it didn't have access to the MCP and tell me that it cannot satisfy my request, rather than blindly carrying on without it?
LLMs consistently prove that they lack the ability to evaluate statements for truth. They lack, as well, an awareness of their unknowing, because they are not trying to understand; their job is to generate (to hallucinate).
It astonishes me that people can be so blind to this weakness of the tool. And when we raise concerns, people always say
"How can you define what 'thinking' is?" "How can you define 'understanding'?"
These philosophical questions are missing the point. When we say it doesn't "understand", we mean that it doesn't do what we ask. It isn't reliable. It isn't as useful to us as perhaps it has been to you.
C'mon, this comparison seems to be very, very unscientific. No offense...
You don’t know how your own mind “understands” something. No one on the planet can even describe how human understanding works.
Yes, LLMs are vast statistical engines but that doesn’t mean something interesting isn’t going on.
At this point I’d argue that humans “hallucinate” and/or provide wrong answers far more often than SOTA LLMs.
I expect to see responses like yours on Reddit, not HN.
The standard, meaningless, HN appeal to authority. "I worked at Google, therefore I am an expert on both stringing a baroque lute and the finer points of Lao cooking. "
Gemini 3 gives a nice explanation if asked "can you explain how you don't really understand anything"
As do most humans. People lie. People make things up to look smart. People fervently believe things that are easily disproved. Some people are willfully ignorant, anti-science, anti-education, etc.
The problem isn't the transformer architecture... it is the humans who advertise capabilities that are not there yet.
The main difference is that people know when they lie and make things up to look smart, LLM doesn't.
Humans are remarkably consistent in their behavior in trained environments. That's why we trust humans to perform dangerous, precise and high stakes tasks. Humans have the meta-cognitive abilities to understand when their abilities are insufficient or when they need to reinforce their own understanding, to increase their resilience.
If you genuinely believe humans hallucinate more often, then I don't think you actually do understand how copilot works.
I suppose that says something about both of us.
"Apart from the sanitation, the medicine, education, wine, public order, irrigation, roads, the fresh water system and public health, what have the Romans ever done for us?" Monty Python's Life of Brian.
P.S. It is relative, but quite a lot of differences IMHO.
I’m always struck by how confidently people assert stuff like this, as if the fact that we can easily comprehend the low-level structure somehow invalidates the reality of the higher-level structures. As if we know concretely that the human mind is something other than emergent complexity arising from simpler mechanics.
I’m not necessarily saying these machines are “thinking”. I wish I could say for sure that they’re not, but that would be dishonest: I feel like they aren’t thinking, but I have no evidence to back that up, and I haven’t seen non-self-referential evidence from anyone else.
Why does the LLM need to understand anything. What today's chatbots have achieved is a software engineering feat. They have taken a stateless token generation machine that has compressed the entire internet's vocabulary to predict the next token and have 'hacked' a whole state management machinery around it. End result is a product that just feels like another human conversing with you and remembering your last birthday.
Engineering will surely get better and while purists can argue that a new research perspective is needed, the current growth trajectory of chatbots, agents and code generation tools will carry the torch forward for years to come.
If you ask me, this new AI winter will thaw in the atmosphere even before it settles on the ground.
LLMs activate similar neurons for similar concepts not only across languages, but also across input types. I’d like to know if you’d consider that as a good representation of “understanding” and if not, how would you define it?
Does a computer know if your boss is mad at you or if they had a fight with their spouse last night, or whatever other reason they may be grumpy?
Can a computer establish relationships… with anything?
How about when a computer goes through puberty? Or menopause? Or a car accident? How do those things affect them?
Don’t bother responding, I think you get the point.
LLMs aren't as good as humans at understanding, but it's not just statistics. The stochastic parrot meme is wrong. The networks create symbolic representations in training, with huge multidimensional correlations between patterns in the data, whether its temporal or semantic. The models "understand" concepts like emotions, text, physics, arbitrary social rules and phenomena, and anything else present in the data and context in the same fundamental way that humans do it. We're just better, with representations a few orders of magnitude higher resolution, much wider redundancy, and multi-million node parallelism with asynchronous operation that silicon can't quite match yet.
In some cases, AI is superhuman, and uses better constructs than humans are capable of, in other cases, it uses hacks and shortcuts in representations, mimics where it falls short, and in some cases fails entirely, and has a suite of failure modes that aren't anywhere in the human taxonomy of operation.
LLMs and AI aren't identical to human cognition, but there's a hell of a lot of overlap, and the stochastic parrot "ItS jUsT sTaTiStIcS!11!!" meme should be regarded as an embarrassing opinion to hold.
"Thinking" models that cycle context and systems of problem solving also don't do it the same way humans think, but overlap in some of the important pieces of how we operate. We are many orders of magnitude beyond old ALICE bots and MEgaHAL markov chains - you'd need computers the size of solar systems to run a markov chain equivalent to the effective equivalent 40B LLM, let alone one of the frontier models, and those performance gains are objectively within the domain of "intelligence." We're pushing the theory and practice of AI and ML squarely into the domain of architectures and behaviors that qualify biological intelligence, and the state of the art models clearly demonstrate their capabilities accordingly.
For any definition of understanding you care to lay down, there's significant overlap between the way human brains do it and the way LLMs do it. LLMs are specifically designed to model constructs from data, and to model the systems that produce the data they're trained on, and the data they model comes from humans and human processes.
Understanding is the construction of a valid model. In biological brains, it's a vast parallelized network columns and neuron clusters in coordinated asynchronous operation, orchestrated to ingest millions of data points both internal and external, which result in a complex and sophisticated construct comprising the entirety of our subjective experience.
LLMs don't have the subjective experience module, explicitly. They're able to emulate the bits that are relevant to being good at predicting things, so it's possible that every individual token inference process produces a novel "flash" of subjective experience, but absent the explicit construct and a persistent and coherent self construct, it's not mapping the understanding to the larger context of its understanding of its self in the same way humans do it. The only place where the algorithmic qualities needed for subjective experience reside in LLMs is the test-time process slice, and because the weights themselves are unchanged in relation to any novel understanding which arises, there's no imprint left behind by the sensory stream (text, image, audio, etc.) Absent the imprint mechanism, there's no possibility to perpetuate the construct we think of as conscious experience, so for LLMs, there can never be more than individual flashes of subjectivity, and those would be limited to very low resolution correlations a degree or more of separation away from the direct experience of any sensory inputs, whereas in humans the streams are tightly coupled to processing, update in real-time, and persist through the lifetime of the mind.
The pieces being modeled are the ones that are useful. The utility of consciousness has been underexplored; it's possible that it might be useful in coordination and orchestration of the bits and pieces of "minds" that are needed to operate intelligently over arbitrarily long horizon planning, abstract generalization out of distribution, intuitive leaps between domains that only relate across multiple degrees of separation between abstract principles, and so on. It could be that consciousness will arise as an epiphenomenological outcome from the successful linking together of systems that solve the problems LLMs currently face, and the things which overcome the jagged capabilities differential are the things that make persons out of human minds.
It might also be possible to orchestrate and coordinate those capabilities without bringing a new mind along for the ride, which would be ideal. It's probably very important that we figure out what the case is, and not carelessly summon a tortured soul into existence.
Understand just means “parse language” and is highly subjective. If I talk to someone African in Chinese they do not understand me but they are still conscious.
If I talk to an LLM in Chinese it will understand me but that doesn’t mean it is conscious.
If I talk about physics to a kindergartner they will not understand but that doesn’t mean they don’t understand anything.
Do you see where I am going?
Why is AGI even necessary? If the loop between teaching the AI something, and it being able to repeat similar enough tasks; if that loop becomes short enough, days or hours instead of months, who cares if some ill-defined bar of AGI is met?
What we didn't get was what had been expected, namely things like expert systems that were actual experts, so called 'general intelligence' and war waged through 'blackboard systems'.
We've had voice controlled electronics for a long time. On the other hand, machine vision applications have improved massively in certain niches, and also allowed for new forms of intense tyranny and surveillance where errors are actually considered a feature rather than a bug since they erode civil liberties and human rights but are still broadly accepted because 'computer says'.
While you could likely argue "leaps and bounds with novel methods utilizing AI for chemistry, computational geometry, biology etc." by downplaying the first part or clarifying that it is mainly an expectation, I think most people are going to, for the foreseeable future, keep seeing "AI" as more or less synonymous with synthetic infantile chatbot personalities that substitute for human contact.
Where the current wave all falls apart is on the financials. None of that makes any sense and there’s no obvious path forward.
Folks say handwavy things like “oh they’ll just sell ads” but even a cursory analysis shows that math doesn’t ad up relative to the sums of money being invested at the moment.
Tech wise I’m bullish. Business wise, AI is setting up to be a big disaster. Those that aimlessly chased the hype are heading for a world of financial pain.
In my experience, management types use the fact that AI generated + Nurse Review is faster to push a higher quota of forms generated per hour.
Eventually, from fatigue or boredom, the human in the loop just ends up being a rubber stamper. Would you trust this with your own or your children's life?
The human in the loop becomes a lot less useful when it's pressured to process a certain quota against an AI that's basically stochastic "most probable next token", aka professional bullshitter, literally trained to generate plasuible outputs with no responsibility to accurate outputs.
They can still be "bleeding money on AI" if they're making enough in other areas to make up for the loss.
The question is: "Are LLMs profitable to train and host?" OpenAI, being a pure LLM company, will go bankrupt if the answer is no. The equivalent for Google is to cut its losses and discontinue the product. Maybe Gemini will have the same fate as Google+.
While there demand at the moment, it’s also unclear what the demand would be if the prices where “real” aka what it would take to run a sustainable business.
That's great that you happened to find a way to use "AI solutions" for this, but it fits precisely inside the parents "tech wise, I'm bullish" statement. It's genuinely new tech, which can unearth some new opportunities like this, by addressing many niche problems that were either out of reach before or couldn't be done efficiently enough before. People like yourself should absolutely be looking for smart new small businesses to build with it, and maybe you'll even be able to grow that business into something incredible for yourself over the next 20 years. Congratulations and good luck.
The AI investment bubble that people are concerned about is about a whole different scale of bet being made; a bet which would only have possibly paid off if this technology completely reconfigured the economy within the next couple years. That really just doesn't seem to be in the cards.
Folks were super bullish tech wise on the internet when it was new and that turned out it be correct. It was also correct that the .com bubble wiped out a generation of companies and those that survived took a decade or more to recover.
The same thing is playing out here… tech is great and not going away but also the business side is increasingly looking like another implosion waiting to happen.
Ok, so I think there's 2 things here that people get mixed on.
First, Inference of the current state of the art is Cheap now. There's no 2 ways about it. Statements from Google, Altman as well as costs of 3rd parties selling tokens of top tier open source models paint a pretty good picture. Ads would be enough to make Open AI a profitable company selling current SOTA LLMs to consumers.
Here's the other thing that mixes things up. Right now, Open AI is not just trying to be 'a profitable company'. They're not just trying to stay where they are and build a regular business off it. They are trying to build and serve 'AGI', or as they define it, 'highly autonomous systems that outperform humans at most economically valuable work'. They believe that, to build and serve this machine to hundreds of millions would require costs order(s) of magnitudes greater.
In service of that purpose is where all the 'insane' levels of money is moving to. They don't need hundreds of billions of dollars in data centers to stay afloat or be profitable.
If they manage to build this machine, then those costs don't matter, and if things are not working out midway, they can just drop the quest. They will still have an insanely useful product that is already used by hundreds of millions every week, as well as the margins and unit economics to actually make money off of it.
The problem is they have real competition now and that market now looks like an expensive race to an undifferentiated bottom.
If someone truly invents AGI and it’s not easily copied by others then I agree it’s a whole new ballgame.
The reality is that years into this we seem to be hitting a limit to what LLMs can do with only marginal improvements with each release. On that path this get ugly fast.
We should factor in that messaging that's seamless and undisclosed in conversational LLM output will be a lot more valuable that what we think of as advertising today.
I'm not going to pretend to be on the cutting edge of news here, but isn't this where on-device models becomes relevant? It sounds like Apple's neural engine or whatever in the M5 have seen noteworthy performance improvements, and maybe in a few more generations, we don't need these openai-sized boondoggles to benefit from the tech?
The top end models with their high compute requirements probably don't but there is value in lower end models for sure.
After all, its the AWS approach. Most of AWS services is stuff you can easily get for cheaper if you just rent an EC2 and set it up yourself. But because AWS offers very simple setup, companies don't mind paying for it.
I've been programming for 30+ years and now a people manager. Claude Code has enabled me to code again and I'm several times more productive than I ever was as an IC in the 2000s and 2010s. I suspect this person hasn't really tried the most recent generation, it is quite impressive and works very well if you do know what you are doing
You have decades upon decades of experience on how to approach software development and solve problems. You know the right questions to ask.
The actual non-programmers I see on Reddit are having discussions about topics such as “I don’t believe that technical debt is a real thing” and “how can I go back in time if Claude Code destroyed my code”.
"it still requires genuine expertise to spot the hallucinations"
"works very well if you do know what you are doing"
For example, build a TUI or GUI with Claude Code while only giving it feedback on the UX/QA side. I've done it many times despite 20 years of software experience. -- Some stuff just doesn't justify me spending my time credentializing in the impl.
Hallucinations that lead to code that doesn't work just get fixed. Most code I write isn't like "now write an accurate technical essay about hamsters" where hallucinations can sneak through lest I scrutinize it; rather the code would just fail to work and trigger the LLM's feedback loop to fix it when it tries to run/lint/compile/typecheck it.
But the idea that you can only build with LLMs if you have a software engineer copilot isn't true and inches further away from true every month, so it kinda sounds like a convenient lie we tell ourselves as engineers (and understandably so: it's scary).
How about hallucinations that lead to code that doesn't work outside of the specific conditions that happen to be true in your dev environment? Or, even more subtly, hallucinations that lead to code which works but has critical security vulnerabilities?
A lot of that will come to the prompter's own foresight much like the vigilance of a beginner developer where they know they are working on a part of the system that is particularly sensitive to get right.
That said, only a subset of software needs an authentication solution or has zero tolerance to some codepath having a bug. Those don't apply to almost all of the apps/TUIs/GUIs I've built over the last few months.
If you have to restrict the domain to those cases for LLMs to be "disastrous", then I'll grant that for this convo.
What about everything else?
The author seems to have a bias. The truth is that we _do not know_ what is going to happen. It's still too early to judge the economic impact of current technology - companies need time to understand how to use this technology. And, research is still making progress. Scaling of the current paradigms (e.g. reasoning RL) could make the technology more useful/reliable. The enormous amount of investment could yield further breakthroughs. Or.. not! Given the uncertainty, one should be both appropriately invested and diversified.
The only thing I learned is that 90% of devs are code monkeys with very low expectations which basically amount to "it compiles and seems to work then it's good enough for me"
That's the issue. AI coding agents are only as good as the dev behind the prompt. It works for you because you have an actual background in software engineering of which coding is just one part of the process. AI coding agents can't save the inexperienced from themselves. It just helps amateurs shoot themselves in the foot faster while convincing them they're a marksman.
If you know what you are doing it works kind of mid. You see how anything more then a prototype will create lots of issues in the long run.
Dunning-Kruger effect in action.
Yes, there is hype.
But if you actually filter it out, instead of (over) reacting to it in either direction, progress has been phenomenal and the fact there is visible progress in many areas, including LLMs, in the order of months demonstrates no walls.
Visible progress doesn’t mean astounding progress. But any tech that is improving year to year is moving at a good speed.
Huge apparent leaps in recent years seem to have spoiled some people. Or perhaps desensitized them. Or perhaps, created frustration that big leaps don’t happen every week.
I can’t fathom anyone not using models for 1000 things. But we all operate differently, and have different kinds of lives, work and problems. So I take claims that individuals are not getting much from models at face value.
But that some people are not finding the value isn’t an argument that those of us getting value, increasing value isn’t real.
You're blind to all the negative side effects, AI generated slop ads, engagement traps, political propaganda, scams, &c. The amount of pollution is incredible, search engines are dead, blogs are dead, YouTube is dead, social medias are dead, it's virtually impossible to find non slop content, the ratio is probably already 50:1 by now
And these are only the most visible things, I know a few companies losing hundreds of hours every month replying to support tickets that are fully llm generated an more often than not don't make any sense. Another big topic is education.
I didn't comment on negative effects one way or the other.
Most of the problems you point out are enabled and motivated by conflict of interest business models. I.e. surveillance that enables and incentivizes targeted ads, targeted manipulation, and addictive media.
Parasitical, privacy violating and dark pattern business models are like bad security. We can't afford them any more. AI is going to make that already very clear point clearer and clearer ... until maybe people wake up and legislate those types of businesses away.
Blaming AI (for those kinds of problems) won't achieve anything. As with any tool, AI is just getting more effective. Might as well blame faster processors too.
And it gives the actual culprits, the people who profit from poison, a pass and cover.
Profitable, scalable, conflicts of interest are poison.
There are a couple really disingenuous bloggers out there who have big audiences themselves and are "experts" for others audiences who really push hard this narrative that AI is a joke and will never progress by where it is today, it is actually completely useless and just a scam. This is comforting for those of us that worry more than are excited about AI so some eat it up while barely trying it for themselves
Maybe they actually think this way, then, I certainly have time for this.
what I have time for? virtual bonding with fello HN ppl :)
Context: I have been writing software for 30 years. I taught myself assembly language and hacked games/apps as a kid, and have been a professional developer for 20 years. I’m not a noob.
I’m currently building a real-time research and alerting side project using a little army of assistant AI developers. Given a choice, I would never go back to how I developed software before this. That isn’t my mind poisoned by hype and marketing.
Today I pasted a screenshot of frontend dropdown menu with a prompt "add a an option here to clear the query cache". Claude found the relevant frontend files, figured out the appropriate backend routes / controllers to edit, and submitted a PR.
However, there is a real risk that AI stocks will crash and pull the entire market down, just like it happened in 2000 with the dotcom bubble. But did we see an internet or dotcom winter after 2000? No, everybody kept using the Internet, Windows, Amazon, Ebay, Facebook and all the other "useless crap". Only the stock market froze over for a few years and previously overhyped companies had a hard time, but given the exaggeration before 2000 this was not really a surprise.
What will happen is that the hype train will stop or slow down, and people will no longer get thousands, millions, billions, or trillions in funding just because they slap "AI" to their otherwise worthless project. Whoever is currently working on such a project should enjoy the time while it lasts - and rest assured that it will not last forever.
The current AI hype is fueled by public markets, and as they found out during the pandemic, the first one to blink and acknowledge the elephant in the room loses, bigly.
So, even in the face of a devastating demonstration of "AI" ineffectiveness (which I personally haven't seen, despite things being, well, entirely underwhelming), we may very well stuck in this cycle for a while yet...
People use LLMs for all kinds of things, but for coding it is absolutely not underwhelming. Can you treat it as a real independent developer, one that doesn't need supervision? No. Can it save you hours and hours of work? Yes.
Last week, when I was on PTO, I used AI to to a full redesign of a music community website I run. I touched about 40k lines of code in a week. The redesign is shipped and everyone is using it. AI let me go about 5-10x faster than if I would have done this by hand. (In fact, I have tried doing this in the past, so I really do have an apples to apples comparison for velocity. AI enabled it happening at all: I’ve tried a few other times in the past but never been able to squeeze it into a week.)
The cited 40% inaccuracy rate doesn’t track for me at all. Claude basically one-shot anything I asked for, to the point that the bottleneck was mostly thinking of what I should ask it to do next.
At this point, saying AI has failed feels like denying reality.
I don't understand the car firmware non-sequitur. I've already seen productivity gains in this domain. Why do I need to also prove them in another one? They are already demonstrated. It's like me saying "I can get places faster in a car than on foot" and you're saying "yeah but you can't get to the moon."
(and no, I don't find LLMs much use on this)
So when I read articles like this, I too am fascinated by the motivations and psychology of the author. What is going on there? The closest analogue I can think of is Climate Change denialism.
For example: https://openrouter.ai/deepseek/deepseek-chat-v3.1
But there is so much real economic value being created - not speculation, but actual business processes - billions of dollars - it’s hard to seriously defend the claim that LLMs are “failures” in any practical sense.
Doesn’t mean we aren’t headed for a winter of sobering reality… but it doesn’t invalidate the disruption either.
Most of the value of AI for our organization is the hype itself providing the activation energy, if you will, to make these projects happen. The value added by the AI systems per se has been minimal.
(YMMV but that’s what I’m seeing at the non-tech bigco I’m at—it’s pretty silly but the checks continue to clear so whatever)
Is there really a clear-cut distinction between the two in today's VC and acquisition based economy?
"We just cured cancer! All cancer! With a simple pill!"
"But you promised it would rejuvenate everyone to the metabolism of a 20 year old and make us biologically immortal!"
New headline: "After spending billions, project to achieve immortality has little to show..."
I think I will keep using it while it's cheap, but once I have to pay the real costs of training/running a flagship modell I think I will quit. It's too expensive as it is for what it does.
Go back to a older version of a LLM and then say the same. You will notice that older LLM versions do less, have more issues, write worse code etc...
There have been large jumps in the last 2 years but because its not like we go from a LLM to AGI, that people underestimate the gains.
Trust me, try it, try Claude 3.7 > 4.0 > 4.5 > Opus 4.5 ...
> I'm unconvinced that this is faster than a good search engine and writing code myself.
What i see is mostly somebody who is standoffish on LLMs ... Just like i was. I tried to shoehorn their code generation into "my" code, and while it works reasonably, you tend to see the LLM working on "your code", as a invasion. So you never really use its full capabilities.
LLMs really work the best, if you plan, plan, plan, and then have them create the code for you. The moment you try to get the LLMs work inside existing code, that is especially structured how YOU like it, people tend to be more standoffish.
> It's too expensive as it is for what it does.
CoPilot is like 27 Euro/month(year payment + dollar/euro) for 1500 requests here. We pay just for basic 100Mbit internet 45 Euro per month. I mean ... Will it get more expensive in the future, o yes, for sure. But we may also have alternatives by then. Open Source/Open Weight models are getting better and better, especially with MoE.
Pricing is how you look at it... If i do the work what takes me a months in a few days, what is the price then? If i do work that i normally need to outsource. Or code that is some monotoon repeating end me %@#$ ... in a short time by paying a few cents to a LLM, ...
Reality is, thing change, and just like the farmers that complained about the tractor, while their neighbor now did much more work thanks to that thing, LLMs are the same.
I often see the most resistance from us older programmer folks, who are set in our ways, when its us who actually are the best at wrangling LLMs the best. As we have the experience to fast spot where a LLM goes wrong, and guide it down the right path. Tell it, the direction is debugging is totally wrong and where the bug more likely is ...
For the last 2 years i paid just the basic cheap $10 subscription, and use it but never strongly. It helped with those monotoon tasks etc. Until ... a months ago, i needed a specific new large project and decided to just agent / vibe code it, just to try at first. And THEN i realized, how much i was missing out off. Yes, that was not "my" code, and when the click came in my head that "i am the manager, not the programmer", you suddenly gain a lot.
Its that click that is hard for most seasoned veterans. And its ironically often the seasoned guys that complain the most about AI ... when its the same folks that can get the most out of LLMs.
I started with Sonnet 4 and now using Opus 4.5. I don't see a meaningful difference. I think I'm a bit more confident to one prompt some issues but that's it. I think the main issue is that I always knew what/how to prompt (same skill as googling) so I can adjust once I learn what a modell can do. Sonnet is kinda the same for me as Opus.
> LLMs really work the best, if you plan, plan, plan, and then have them create the code for you. The moment you try to get the LLMs work inside existing code, that is especially structured how YOU like it, people tend to be more standoffish.
My project is AI code only. Around 30k lines, I never wrote a single line. I know I cannot just let it vibe code because I lost a month getting rid of AI spaghetti that it created in the beginning. It just got stuck rewriting and making new bugs as soon as it fixed one. Since then I'm doing a lot more handholding and a crazy amount of unit/e2e testing. Which btw. is a huge limiting factor. Now I want powerful dev machine again because if unit + e2e testing takes more than a couple seconds it slows down LLMs.
> Pricing is how you look at it... If i do the work what takes me a months in a few days, what is the price then?
I spent around 200 USD on subscriptions so far. I wanted to try out Opus 4.5 so I splurged on a Claude Max subscription this month. It's definitely a very expensive hobby.
> And its ironically often the seasoned guys that complain the most about AI
I think because we understand what it can do.
This means that LLMs don't do well with input where text that comes later in the input alters how text that came earlier should be interpreted. Which is really quite common in practice.
Humans like to do things where you start with a dump of information, and then ask questions about it afterward. If a human reader didn't remember something pertinent to the question, they can go back and re-read now that they know what they're looking for. An LLM can't do that by itself. You can paper over that limitation with hacks, but they're hacky and unreliable.
Humans also correct misunderstandings and resolve ambiguities after the fact. LLMs have a really hard time with this. Once one way of interpreting some text has already made it into the LLM's context vectors, it can be surprisingly difficult for subsequent text to significantly alter that interpretation.
It's these sorts of aggravating failure modes stemming from a fundamental feature of the algorithm that seem to always produce the next AI winter. Because they tend to mean the same thing: research has gone down (and then, quote often, massively over-invested in) yet another blind alley that doesn't put us on a short easy path to AGI any more than the previous 75 years' worth of breakthroughs have. And getting out of it is going to involve not only fixing that one problem, but also a huge reset on some substantial portion of whatever tools and techniques were built up to paper over the previous algorithm's limitations in an effort to generate positive ROI on all that massive over-investment.
It gets the entire input all at once. Then it generates the output one token at a time.
Anything else built around it (agents etc) might be challenged by the realities.
AI in consumer hands is no longer just a niche program in a corner of your company or government organization that can defund and shut down.
If the current purveyors of big cloud AI were to fold, their replacements are waiting in the wings to pick up the demand somehow.
Tokens/week have gone up 23x year-over-year according to https://openrouter.ai/rankings. This is probably around $500M-1B in sales per year.
The real question is where the trajectory of this rocket ship is going. Will per-token pricing be a race to the bottom against budget chinese model providers? Will we see another 20x year year over the next 3 years, or will it level out sooner?
The reason is hype deflation and technical stagnation don't have to arrive together. Once people stop promising AGI by Christmas and clamp down on infinite growth + infinite GPU spend, things will start to look more normal.
At this point, it feels more like the financing story was the shaky part not the tech or the workflows. LLMs’ve changed workflows in a way that’s very hard to unwind now.
AI tooling has only just barely reached the point where enterprise CRUD developers can start thinking about. Langchain only reached v1.0.0 in the last 60 days (Q4 2025); OpenAI effectively announced support for MCP in Q2 2025. The spec didn't even approach maturity until Q4 of 2024. Heck most LLMs didn't have support for tools in 2024.
In 2-3 years a lot of these libraries will be part way through their roadmap towards v2.0.0 to fix many of the pain points and fleshing out QOL improvements, and standard patterns evolved for integrating different workflows. Consumer streaming of audio and video on the web was a disaster of a mess until around ~2009 despite browsers having plugins for it going back over a decade. LLMs continue to improve at a rapid rate, but tooling matures more slowly.
Of course previous experiments failed or were abandoned; the technology has been moving faster than the average CRUD developer can implement features. A lot of "cutting edge" technology we put into our product in 2023 are now standard features for the free tier of market leaders like ChatGPT etc. Why bother maintaining a custom fork of 2023-era (effectively stone age) technology when free tier APIs do it better in 2025? MCP might not be the be-all, end-all, but at least it is a standard interface that's at least maintainable in a way that developers of mature software can begin conceiving of integrating it into their product as a permanent feature, rather than a curiosity MVP at the behest of a non technical exec.
A lot of AI-adjacent libraries we've been using finally hit v1.0.0 this year, or creeping close to it; providing stable interfaces for maintainable software. It's time to hit the reset button on "X% of internal AI initiatives failed"
for example, fictional stories. If you want to be entertained and it doesn’t matter if it’s true or not, there’s no downsides to “hallucinations”. you could argue that stories ARE hallucinations.
another example is advertisements. what matters is how people perceive them, not what’s actually true.
or, content for a political campaign.
the more i think about it, genAI really is a perfect match for social media companies
also, i’d like to hear your story about the human with three hands
exactly - just like 99.9873% of all codebases currently running in production worldwide :)
> Depending on the context, and how picky you need to be about recognizing good or bad output, this might be anywhere from a 60% to a 95% success rate, with the remaining 5%-40% being bad results. This just isn't good enough for most practical purposes
This seems to suggest that humans are 100%. I'd be surprised if i was anywhere close to that after 10 years of programming professionally
AI just got better and better. People thought it couldn't solve math problems without some human formalizes them first. Then it did. People thought it couldn't generate legible text. Then it did.
All while people swore it had reached a "plateau," "architecture ceiling," "inherent limit," or whatever synonym of the goalpost.
I agree that the economics of GenAI are currently upside down. The CapEx spend is eye-watering, and the path to profitability for the foundational model providers is still hazy. We are almost certainly in an age of inflated-expectations hype-cycle peak that will self-correct, and yes, "winter is harsh on tulips".
However, the claim that the technology itself is a failure is objectively disconnected from reality. Unlike crypto or VR (in their hype cycles), LLMs found immediate, massive product-market fit. I use K-means clustering and logistic regression every day; they aren't AGI either, but they aren't failures.
If 95% of corporate AI projects fail, it's not because the tech is broken; it's because middle management is aspiring to replace humans with a terminal-bound chatbot instead of giving workers an AI companion. The tech isn't going away, even if AI valuations might be questioned in the short term.
As with so much of Silicon Valley's output the past few decades, "AI" is not something people will pay for. It could be a new form of Trojan Horse for data collection, surveillance and ads, though, adopting a hyperfocus on "growth" at any cost (human, environmental, etc.) but this might not even be necessary^1
Time will tell
In order to raise funds in the absence of any clear business plan, "AI" cannot just be ordinary and useful. It cannot be "autocomplete on steroids". It must be "world-changing"
No one shall underestimate or discount the value of "AI". Overestimation is permitted, however. Speculation is encouraged, but only if it's wild and extreme
1. "AI" is not depending on being brought inside the gates of Troy by the city's inhabitants. It's being placed inside the gates by others. Companies with large numbers of users are installing "AI" on users' computers without the users' consent
If AI models can deliver measurably better accuracy than doctors, clearer evaluations than professors and fairer prosecutions than courts, then it should be adopted. Waymo has already shown a measurable decrease in loss of life by eliminating humans from driving.
I believe, technically, moderns LLMs are sufficiently advanced to meaningfully disrupt the aforementioned professions as Waymo has done for taxis. Waymo's success relies on 2 non-llm factors that we've yet to see for other professions. First is exhaustive collection and labelling of in-domain high quality data. Second is the destruction of the pro-human regulatory lobby (thanks to work done by Uber in the Zirp era that came before).
To me, an AI winter isn't a concern, because AI is not the bottleneck. It is regulatory opposition and sourcing human experts who will train their own replacements. Both are significantly harder to get around for high-status white collar work. The great-AI-replacement may still fail, but it won't be because of the limitations of LLMs.
> My advice: unwind as much exposure as possible you might have to a forthcoming AI bubble crash.
Hedging when you have much at stake is always a good idea. Bubble or no bubble.
Winters are when technology falls out of the vice grip of Capital and into the hands of the everyman.
Winters are when you’ll see folks abandon this AIaaS model for every conceivable use case, and start shifting processing power back to the end user.
Winters ensure only the strongest survive into the next Spring. They’re consequences for hubris (“LLMs will replace all the jobs”) that give space for new things to emerge.
So, yeah, I’m looking forward to another AI winter, because that’s when we finally see what does and does not work. My personal guess is that agents and programming-assistants will be more tightly integrated into some local IDEs instead of pricey software subscriptions, foundational models won’t be trained nearly as often, and some accessibility interfaces will see improvement from the language processing capabilities of LLMs (real-time translation, as an example, or speech-to-action).
That, I’m looking forward to. AI in the hands of the common man, not locked behind subscription paywalls, advertising slop, or VC Capital.
If you have to set up good tests [edit: and gather/generate good test data!] and get the spec hammered out in detail and well-described in writing, plus all the ancillary stuff like access to any systems you need, sign-offs from stakeholders… dude that’s more than 90% of the work, I’d say. I mean fuck, lots of places just skip half that and figure it out in the code as they go.
How’s this meaningfully speeding things up?
Assuming these claims are even partially true, we'd be stupid—at the personal and societal level—not to avail ourselves of these tools and reap the productivity gains. So I don't see AI going away any time soon. Nor will it be a passing fad like Krugman assumed the internet would be. We'd have to course-correct on its usage, but it truly is a game changer.
Lemma: any statement about AI which uses the word "never" to preclude some feature from future realization is false.
Lemma: contemporary implementations have almost always already been improved upon, but are unevenly distributed.
(Ximm's Law)
1) LLMs have failed to live up to the hype.
Maybe. Depends upon's who's hype. But I think it is fine to say that we don't have AGI today (however that is defined) and that some people hyped that up.
2) LLMs haven't failed outright
I think that this is a vast understatement.
LLMs have been a wild success. At big tech over 40% of checked in code is LLM generated. At smaller companies the proportion is larger. ChatGPT has over 800 million weekly active users.
Students throughout the world, and especially in the developed world are using "AI" at 85-90% (from some surveys).
Between 40% of professionals and 90% (depending upon survey and profession) are using "AI".
This is 3 years after the launch of ChatGPT (and the capabilities of chatGPT 3.5 were so limited compared to today that it is a shame that they get bundled together in our discussions). I would say instead of "failed outright" that they are the most successful consumer product of all time (so far).
I have a really hard time believing that stat without any context, is there a source for this?
but they do that while making the codebase substantially worse for the next person or LLM. large code size, inconsistent behavior, duplicates of duplicates of duplicates strewn everywhere with little to no pattern so you might have to fix something a dozen times in a dozen ways for a dozen reasons before it actually works, nothing handles it efficiently.
the only thing that matters in a business is value produced, and I'm far from convinced that they're even break-even if they were free in most cases. they're burning the future with tech debt, on the hopes that it will be able to handle it where humans cannot, which does not seem true at all to me.
Hopefully one of the major companies will release a comprehensive report to the public, but they seem to guard these metrics.
Assuming this is true though, how much of that 40% is boilerplate or simple, low effort code that could have been knocked out in a few minutes previously? It's always been the case that 10% of the code is particularly thorny and takes 80% of the time, or whatever.
Not to discount your overall point, LLMs are definitely a technical success.
Really? I derive a ton of value from it. For me it’s a phenomenal advancement and not a failure at all.
We should say: most rapidly adopted ... speculation.
Because this is what it is: not a technology, but speculation.
Hint: technology has repeatable results.
QED ;)
Go ahead and double check when the LLM craze started and perhaps reconsider making things up.
January 2020: Researchers: Are we on the cusp of an ‘AI winter’? (bbc.co.uk) [2]
I'm sure you can easily find more. Felt good to be called a "bro", though, made me feel younger.
[1] HN discussion, almost 500 comments: https://news.ycombinator.com/item?id=17184054
[2] HN discussion on BBC article, ~110 comments: https://news.ycombinator.com/item?id=22069204
People have figured it out by now. Generative "AI" will fail, other forms may continue, though it it would be interesting to hear from experts in other fields how much fraud there is. There are tons of material science "AI" startups, it is hard to believe they all deliver.
Well, correctness(though not only correctness) sounds convincing, the most convincing even, and ought to be information-theory-wise cheaper to generate than a fabrication, I think.
So if this assumption holds, the current tech might have some ceiling left if we just continue to pour resources down the hole.
Lol someone doesn't understand how the power structure system works "the golden rule". There is a saying if you owe the bank 100k you have a problem. If you owe the bank ten million the bank has a problem. OpenAI and the other players have made this bubble so big that there is no way the power system will allow themselves to take the hit. Expect some sort of tax subsided bailout in the near future.
What we should underscore though, is that even if there is a new AI winter, the world isn’t going back to what it was before AI. This is it, forever.
Generations ahead will gaslight themselves into thinking this AI world is better, because who wants to grow up knowing they live in a shitty era full of slop? Don’t believe it.
Put another way, the advent of industrialized steam power wasn't so much about steam per se, but rather the intersection of a number of factors (steam itself obviously being an important one). This intersection became a lot more likely as the pace of innovation in general began accelerating with the Enlightenment and the ease with which this information could be collected and synthesized.
I suspect that the LLM itself may also prove to be less significant than the density of innovation and information of the world it's developed in. It's not a certainty that there's a killer app on the scale of mechanized steam, but the odds of such significant inventions arguably increase as the basics of modern AI become basic knowledge for more and more people.
But if that analogy holds, then LLM use in software development is the "new coal mines" where it will be perfected until it spills over into other areas. We're definitely not at the "Roman stage" anymore.
It could very well that the current generation of AI has poisoned the well for any future endeavors of creating AI. You can't trivially filter out the AI slop and humans are less likely to make their handcrafted content freely available for training. In fact violating GPL code to train models on it might be ruled to be illegal as well generally stricter rules on which data you are allowed to use for training.
We might have reached a local optimum that is very difficult to escape from. There might be a long, long AI winter ahead of us, for better or worse.
> the world isn’t going back to what it was before AI. This is it, forever.
I feel this so much. I though my longing for the pre-smartphone days was bad but damn we have lost so much.
I think we'll continue to see anything be automated that can be automated in a way that reduces head count. So you have the dumb AI as a first line of defense and lay off half the customer service you had before.
In the meantime, fewer and fewer jobs (especially entry level), a rising poor class as the middle class is eliminated and a greater wealth gap than ever before. The markets are going to also collapse from this AI bubble. It's just a matter of when.
Here's a few clarifications (sorry this is so long...):
"I should explain for anyone who hasn't heard that term [AI winter]... there was much hope, as there is now, but ultimately the technology stagnated. "
The term AI winter typically refers to a period of reduced funding for AI research/development, not the technology stagnating (the technology failing to deliver on expectations was the cause of the AI winter, not the definition of AI winter).
"[When GPT3 came out, pre-ChatGPT] People were saying that this meant that the AI winter was over, and a new era was beginning."
People tend to agree there were two AI winters already, one having to do with symbolic AI disappointments/general lack of progress (70s), and the latter related to expert systems (late 80s). That AI winter has long been over. The Deep Learning revolution started in ~2012, and by 2020 (GPT 3) huge amount of talent and money were already going into AI for years. This trend just accelerated with ChatGPT.
"[After symbolic AI] So then came transformers. Seemingly capable of true AI, or, at least, scaling to being good enough to be called true AI, with astonishing capabilities ... the huge research breakthrough was figuring out that, by starting with essentially random coefficients (weights and biases) in the linear algebra, and during training back-propagating errors, these weights and biases could eventually converge on something that worked."
Transformers came about in 2017. The first wave of excitement about neural nets and backpropagation goes all the way back to the late 80s/early 90s, and AI (computer vision, NLP, to a lesser extent robotics) were already heavily ML-based by the 2000s, just not neural-net based (this changed in roughly 2012).
"All transformers have a fundamental limitation, which can not be eliminated by scaling to larger models, more training data or better fine-tuning ... This is the root of the hallucination problem in transformers, and is unsolveable because hallucinating is all that transformers can do."
The 'highest number' token is not necessarily chosen, this depends on the decoding algorithm. That aside, 'the next token will be generated to match that bad choice' makes it sound like once you generate one 'wrong' token the rest of the output is also wrong. A token is a few characters, and need not 'poison' the rest of the output.
That aside, there are plenty of ways to 'recover' from starting to go down the wrong route. A key aspect of why reasoning in LLMs works well is that it typically incorporates backtracking - going earlier in the reasoning to verify details or whatnot. You can do uncertainty estimation in the decoding algorithm, use a secondary model, plenty of things (here is a detailed survey https://arxiv.org/pdf/2311.05232 , one of several that is easy to find).
"The technology won't disappear – existing models, particularly in the open source domain, will still be available, and will still be used, but expect a few 'killer app' use cases to remain, with the rest falling away."
A quick google search shows ChatGPT currently has 800 million weekly active users who are using it for all sorts of things. AI-assisted programming is certainly here to stay, and there are plenty of other industries in which AI will be part of the workflow (helping do research, take notes, summarize, build presentations, etc.)
I think discussion is good, but it's disappointing to see stuff with this level of accuracy being on front page of HN.
> People were saying that this meant that the AI winter was over
The last AI winter was over 20 years ago. Transformers came during an AI boom.
> First time around, AI was largely symbolic
Neural networks were already hot and the state of the art across many disciplines when Transformers came out.
> The other huge problem with traditional AI was that many of its algorithms were NP-complete
Algorithms are not NP-complete. That's a type error. Problems can be NP-complete, not algorithms.
> with the algorithm taking an arbitrarily long time to terminate
This has no relationship to something being NP-complete at all.
> but I strongly suspect that 'true AI', for useful definitions of that term, is at best NP-complete, possibly much worse
I think the author means that "true AI" returns answers quickly and with high accuracy? A statement that has no relationship to NP-completeness at all.
> For the uninitiated, a transformer is basically a big pile of linear algebra that takes a sequence of tokens and computes the likeliest next token
This is wrong on many levels. A Transformer is not a linear network, linear networks are well-characterized and they aren't powerful enough to do much. It's the non-linearities in the Transformer that allows it to work. And only Decoders compute the distribution over the next token.
> More specifically, they are fed one token at a time, which builds an internal state that ultimately guides the generation of the next token
Totally wrong. This is why Transformers killed RNNs. Transformers are provided all tokens simultaneously and then produce a next token one at a time. RNNs don't have that ability to simultaneously process tokens. This is just totally the wrong mental model of what a Transformer is.
> This sounds bizarre and probably impossible, but the huge research breakthrough was figuring out that, by starting with essentially random coefficients (weights and biases) in the linear algebra, and during training back-propagating errors, these weights and biases could eventually converge on something that worked.
Again, totally wrong. Gradient descent dates back to the late 1800s early 1900s. Backprop dates back to the 60s and 70s. So this clearly wasn't the key breakthrough of Transformers.
> This inner loop isn't Turing-complete – a simple program with a while loop in it is computationally more powerful. If you allow a transformer to keep generating tokens indefinitely this is probably Turing-complete, though nobody actually does that because of the cost.
This isn't what Turing-completeness is. And by definition all practical computing is not a Turing Machine, simply because TMs require an infinite tape. Our actual machines are all roughly Linear Bounded Automata. What's interesting is that this doesn't really provide us with anything useful.
> Transformers also solved scaling, because their training can be unsupervised
Unsupervised methods predate Transformers by decades and were already the state of the art in computer vision by the time Transformers came out.
> In practice, the transformer actually generates a number for every possible output token, with the highest number being chosen in order to determine the token.
Greedy decoding isn't the default in most applications.
> The problem with this approach is that the model will always generate a token, regardless of whether the context has anything to do with its training data.
Absolutely not. We have things like end tokens exactly for this, to allow the model to stop generating.
I got tired of reading at this point. This is drivel by someone who has no clue what's going on.
I think you are too triggered and entitled in your nit-picking. Its obvious in potentially limited universe infinite tape can't exists, but for practical purpose in CS, turing-completeness means expressiveness of logic to emulate TM regardless of tape size.
> If you allow a transformer to keep generating tokens indefinitely this is probably Turing-complete, though nobody actually does that because of the cost.
Either they're equivalent to Turning machines or not. Claiming that practically they aren't because no one runs them long enough defeats the very notion of a Turning machine in the first place.
I'm shocked a post like this that isn't even at the level of an intro to computation class is getting attention.
I think this is your own conclusion, which can't be strictly derived from citation.
Here, I am just nit-picking on your nit-picking, I don't think this discussion is productive or intresting.
But that's me being a sucker. Because in reality this is just a clickbait headline for an article basically saying that the tech won't fully get us to AGI and that the bubble will likely pop and only a few players will remain. Which I completely agree with. It's really not that profound.
{kind=link}