And even if we were to agree that that's a reasonable standard, GPT 5 shouldn't be included. There is only one datapoint for all OpenAI models. That data point more indicative of the performance of OpenAI models (and the harness used) than of any progression. Once you exclude it it matches what you would expect from a logistic model. Improvements have slowed down, but not stopped
1: https://metr.org/assets/images/many-swe-bench-passing-prs-wo...
If you measure completion rate on a task where a single mistake can cause a failure, you won't see noticeable improvements on that metric until all potential sources of error are close to being eliminated, and then if they do get eliminated it causes a sudden large jump in performance.
That's fine if you just want to know whether the current state is good enough on your task of choice, but if you also want to predict future performance, you need to break it down into smaller components and track each of them individually.
> until all potential sources of error are close to being eliminated
> if you also want to predict future performance, you need to break it down into smaller components and track each of them individually.
This is fascinating. LLM community discovers PSP/TSP rules that were laid over more than twenty years ago.
What LLM community miss is that in PSP/TSP it is an individual software developer who is responsible to figure out what they need to look after.
What I see is that it is LLM users who try to harness LLMs with what they perceive as errors. It's not that LLMs are learning, it is that users of LLMs are trying to stronghold these LLMs with prompts.
It's useless and never gets better until it suddenly, unexpecty got good enough.
Things have improved a bit? Now robot shelves becomes a possibility. Map everything, use more sensors, designate humans to a particular area only. Still quite useful. It is safe by design of areas, where humans rarely walk among robots.
Improved further? Now we can do food delivery service robot. Slow down a bit, use much more sensors, think extra hard how to make it safer. Add a flag on a flagpole. Rounded body. Collisions are probably going to happen. Make the robot lighter than humans so that robot gets more damage than the human in a collision. Humans are vulnerable to falling over - make the robot hight just right to grab onto to regain balance, somewhere near waist hight.
Something like that... Now I wish this would be an actual progress requirement for a robo taxy company to do before they start releasing robo taxies onto our streets. But at least we do it as mankind, algorithm improvements, safety solutuon still benefit the whole chain. And benefit to humanity grows despite it being not quite good enough for one particular task.
1) Something happened during 2025 that made the models (or crucially, the wrapping terminal-based apps like Claude Code or Codex) much better. I only type in the terminal anymore.
2) The quality of the code is still quite often terrible. Quadruple-nested control flow abounds. Software architecture in rather small scopes is unsound. People say AI is “good at front end” but I see the worst kind of atrocities there (a few days ago Codex 5.3 tried to inject a massive HTML element with a CSS before hack, rather than proprerly refactoring markup)
Two forces feel true simultaneously but in permanent tension. I still cannot make out my mind and see the synthesis in the dialectic, where this is truly going, if we’re meaningfully moving forward or mostly moving in circles.
I have heard say that the change was better context management and compression.
200k and now 1M contexts. Better context management was enabled by improvements in structured outputs/tool calling at the model level. Also reasoning models really upped the game “plan” mode wouldn’t work well without them.
I only say that because I'm a shit frontend dev. Honestly, I'm not that bad anymore, but I'm still shit, and the AI will probably generate better code than I will.
Which is akin to driving a car - the motor vehicle itself doesn’t know where to go. It requires you to prompt via steering and braking etc, and then to review what is happening in response.
That’s not necessarily a bad thing - reviewing code ultimately matters most. As long as what is produced is more often than not correct and legible.. now this is a different issue for which there isn’t a consensus across software engineer’s.
It is therefore not important whether some intermediate version of that low-level code was completely impossible to understand.
It is not so with LLM-written high-level code. More often than not, it does need to be understood and maintained by someone or something.
These days, I mainly focus on two things in LLM code reviews:
1. Making sure unit tests have good coverage of expected behaviours.
2. Making sure the model is making sound architectural decisions, to avoid accumulating tech debt that'll need to be paid back later. It's very hard to check this with unit tests.
There are good reasons why they don't or can't do simple param upscaling anymore, but still, it makes me bearish on AGI since it's a slow, but massive shift in goal setting.
In practice this still doesn't mean 50 % of white collar can't be automated though.
Let me ask you this, though: if we wanted to, what percentage of white collar jobs could have been automated or eliminated prior to LLMs?
Meta has nearly 80k employees to basically run two websites and three mobile apps. There were 18k people working at LinkedIn! Many big tech companies are massive job programs with some product on the side. Administrative business partners, program managers, tech writers, "stewards", "champions", "advocates", 10-layer-deep reporting chains... engineers writing cafe menu apps and pet programming languages... a team working on in-house typefaces... the list goes on.
I can see AI producing shifts in the industry by reducing demand for meaningful work, but I doubt the outcome here is mass unemployment. There's an endless supply of bs jobs as long as the money is flowing.
They build generative AI tools so people can make ads more easily.
They have some of the most sophisticated tracking out there. They have shadow profiles on nearly everyone. Have you visited a website? You have a shadow profile even if you don't have a Facebook account. They know who your friends are based on who you are near. They know what stores you visit when.
Large fractions of their staff are making imperceptible changes to ads tracking and feed ranking that are making billions of dollars of marginal revenue.
What draws you in as a consumer is a tiny tip of the iceberg of what they actually do.
The reality is that you could run LinkedIn with far, far fewer people. You probably need fewer than 100 for core engineering, and likely less than 1,000 overall if you include compliance, sales, and so on - especially since a lot of overseas compliance stuff is outsourced to consulting firms, it's not like you have a team of lawyers in every country in the world.
Before there was so much money in the system, we used to run companies that way. Two decades ago, I worked for a company that had tens of millions of users, maintained its own complex nationwide infra (no AWS back then), and had 400 full-time employees. That made coordination problems a lot easier too. We didn't need ten layers of people and project management because there just wasn't that many of us.
Keeping a website running with high uptime is not the goal. Maximizing revenue and profit is. The extra people aren't waste, they're what drive the incremental imperceptible changes that make these companies profitable.
Maybe there's a correlation there?
It sort of reminds me of The Collapse of Complex Societies by Joseph Tainter. These companies are their own microcosms of a complex society and I bet we will see mass layoffs in the future, not from AI but from those companies collapsing into a more sustainable state.
Is it a better user experience now? Yes. Has it boosted my productivity on this project? Absolutely.
But it still needs a ton of hand holding for anything complicated and I still deal with tons of "OK, this bug is fixed now!" followed by manually confirming a bug still exists.
Haiku 4.5 is already so good it's ok for 80% (95%?) of dev tasks.
It's notably lacking newer models (4.5 Opus, 4.6 Sonnet) and models from Gemini.
LLMs appear to naturally progress in short leaps followed by longer plateaus, as breakthroughs are developed such as chain-of-thought, mixture-of-experts, sub-agents, etc.
Assuming we get no better than opus 4.6, they're very capable. Even if they make up nonsense 5% of the time!
I don’t see that ever going away. Humans have learned to trust other humans over a large time scale with rules in place to control behaviour.
Once we know what they can do well and how to get them to do it well, and what they can't, you could say we "trust" them to do the first category well and just stop trying to get it to do the second category.
We've compared now more than a hundred replies to that of GPT Pro, and the quality is roughly the same. Sometimes a little worse, sometimes a little better. Always more detailed. Never unacceptable.
But how to convince our customers that we have the right technology and know how to use it appropriately? We're trying, but it's not easy.
Part of that's accountability. In the event of the LLM producing rubbish, as rare as it may be, who is accountable? There is not a person and her reputation attached to it.
You won’t be able to scale out and make as much money though. But surely you’re not only concerned about profit, right? What’s the point of life if you’re just trying to get rich.
Being able to hold someone liable for a F up has been how we have been able to function as a society and get to where we are today.
It will be wrong on a lot of details. Basically you would get a market scene that feels 18th century gb, but will use 18th century russian/french/Austrian details, or 19th century/20th century British artefacts, or a mix of both. And the further you go from western places, the higher the error rate is. Basically generating fiction scenes. That's pretty much my usecase, so that's fine, but I won't ever use it to illustrate a historical TTrpg.
In particular GPT 5.4 is much better at not duplicating code unnecessarily. It'll take the time to refactor, to search for pre-existing utility functions, etc.
You kind of have to go on "feels" for a lot of this.
Most of us have been coding for ages. I actually find it really odd people keep trying to disprove things that are relatively obvious with LLMs
But LLMs are hamstrung by their harnesses. They are doing the equivalent of providing technical support via phone call: little to no context, and limited to a bidirectional stream of words (tokens). The best agent harnesses have the equivalent of vision-impairment accessibility interfaces, and even those are still subpar.
Heck, giving LLMs time to think was once a groundbreaking idea. Yesterday I saw Claude Code editing a file using shell redirects! It's barbaric.
I expect future improvements to come from harness improvements, especially around sub agents/context rollbacks (to work around the non-linear cost of context) and LLM-aligned "accessibility tools". That, or more synthetic training data.
entirely so. i think anthropic updated something about the compact algorithm recently, and its gone from working well over long times to basically garbage whenever a compact happens
And search engines are narrow tools that can only output copies of its dataset. An LLM is capable of surprisingly novel output, even if the exact level of creativity is heavily debated.
On a different note, LLMs are still not very wise, as displayed by all the prompt attacks and occasional inane responses like walking to the car wash.
I'm faster than a car when scrambling up a mountain. It's easy to be fast when all you do is drive on smooth roads.
I'm stronger than a hydraulic press when carrying a load over a distance. It's easy to be strong when you're limited to a few centimetres of movement.
Intelligence of LLMs is a trick; they are literally trained to sound intelligent. But it's easy to sound intelligent when all you have to do is sound intelligent. A person has to live in the real world, deal with the weather, with feelings, stress, health and, above all, consequences. We don't have the luxury of just being able to sound intelligent, or have wheels that only work on smooth roads. We have to actually be intelligent in our actions. We have to traverse difficult ground, deal with obstacles we've never encountered before. When we make mistakes, people get hurt.
We can debate whether that's real intelligence, and whether the question is fair, but this is still a real, measurable capability, that just eight years ago was a pipe dream. This capability is what OP is tracking, and what I believe is impressive but hamstrung by harnesses.
Truth is I'm probably wrong. I should keep on testing ... but at the same time I precisely gave up because I didn't think the trend was fast enough to keep on investing on checking it so frequently. Now I just read this kind of post, ask around (mainly arguing with comments asking for genuine examples that should be "surprising" and kept on being disappointed) and that seems to be enough for a proxy.
I should though, as I mentioned in another comment, keep track of failed attempts.
PS: I check solely on self-hosted models (even if not on my machine but least on machines I could setup) because I do NOT trust the scaffolding around proprietary closed sources models. I can't verify that nobody is in the loop.
When you combine models with:
tool use
planning loops
agents that break tasks into smaller pieces
persistent context / repos
the practical capability jump is huge.
So I’d say fairly flat commit acceptance numbers make sense even in the context of improving LLMs
I think the only reasonable thing to read into is Sonnet 3.5 -> 3.7 -> 4.5. But yeah, you just can't draw a line through this thing.
I will die on the hill that LLMs are getting better, particularly Anthropic's releases since December. But I can't point at a graph to prove that, I'm just drawing on my personal experience. I do use Claude Code though, so I think a large part of the improvement comes from the harness.
Regardless I'm more inclined to believe that 4.5 was the point that people started using it after having given up on copy/pasting output in 2024. If you're going from chat to agentic level of interaction it's going to feel like a leap.
I don't know if it's model, or harness improvements, or inbuilt-memory or all of the above, but it often has a step where it'll check itself that is done now before trying to build and getting an inevitable failure.
Those small things add up to a much smoother and richer experience today compared to 6 months ago.
On the other hand, LLMs tend to go for an average by their nature (if you squint enough). What's more common in their training data, it's more common in the output, so getting them better without fundamental changes, requires one to improve the training data on average too which is hard.
What did improve a lot is the tooling around them. That's gotten way better.
Supposedly model curation is a Big Deal at Big AI, and they're especially concerned about Ouroboros effects and poisoned data. Also people are still contributing to open source and open sourcing new projects, something that should have slowed to trickle by 2023, once it became clear that from now on, you're just providing the fuel for the machines that will ultimately render you unemployable (or less employable), and that these machines will completely disregard your license terms, including those of the most permissive licenses that seek only attribution, and that you're doing all of this for free.
So we got better in giving it the right context and tools to do the stuff we need to do but not the actual thinking improvements
We still have tons of gaps about how to build and maintain code with AI, but LLM themselves getting better at an unbelievable pace, even with this kind of data analysis I’m surprised anyone can even question it.
How much of that is the model and how much of that is the tooling built around it? Also why is the tooling, specifically Claude Code, so buggy?
It's my experience that opus 4, and then, particularly, 4.5, in Claude code, are head and shoulders above the competition.
I wrote an agentic coder years ago and it yielded trash. (Tried to make it do then what kiro does today).
The models are better. Now, caveat - I don't use anything but opus for coding - Sonnet doesn't do the trick. My experience with Codex and Gemini is that their top models are as good as Sonnet for coding...
Although I feel like for chasing bugs and big systems codex is even better
Without any data from the study past September I think its not unreasonable, if you want to make an argument based on evidence.
For me personally, I agree with you, I'm really seeing it as well.
well, yeah. because that's been the experience for many people.
3 years ago, trying to use ChatGPT 3.5 for coding tasks was more of a gimmick than anything else, and was basically useless for helping me with my job.
today, agentic Opus 4.6 provides more value to me than probably 2 more human engineers on my team would
I tried GPT3.5 for translating code from typescript to rust. It made many mistakes in rust. It couldn't fix borrow checker issues. The context was so small that I could only feed it small amounts of my program at a time. It also introduced new bugs into the algorithm.
Yesterday I had an idea for a simple macos app I wanted. I prompted claude code. It programmed the whole thing start to finish in 10 minutes, no problem. I asked it to optimize the program using a technique I came up with, and it did. I asked it to make a web version and it did. (Though for some reason, the web version needed several rounds of "it doesn't work, here's the console output").
I'm slowly coming to terms with the idea that my job is fundamentally changing. I can get way more done by prompting claude than I can by writing the code myself.
Yes but this blogpost argues that at least over the course of 2024 to the end of 2025, those people were mistaken.
I'm certainly getting faster and cleaner-looking solutions for certain issues on Opus 4.6 than I was 5 months ago, but I'm not sure about the ability to solve (or even weigh in) the actual hard stuff, i.e. the stuff I'm paid for.
And I'm definitely not sure about the supposed big step between 4.5 and 4.6. I'm literally not seeing any.
What's been the game changer are tools like Claude Code. Automatic agentic tool loops purpose built for coding. This is what I have seen as the impetus for mainstream adoption rather than noticeable improvements in ability.
I write a lot of C++ and QML code. Codex 5.3, only released in Feb, is the the first model I've used that would regularly generate code that passes my 25 years expert smell test and has turned generative coding from a timesap/nuisance into a tool I can somewhat rely on not to set me back.
Claude still wasn't quite there at the time, but I haven't tried 4.6 yet.
QML is a declarative-first markup language that is a superset of the JavaScript syntax. It's niche and doesn't have a giant amount of training data in the corpus. Codex 5.3 is the first model that doesn't super botch it or prefers to write reams of procedural JS embeds (yes, after steering). Much reduced is also the tendency to go overboard on spamming everything with clouds of helper functions/methods in both C++ and QML. It knows when to stop, so to speak, and is either trained or able to reason toward a more idiomatic ideal, with far less explicit instruction / AGENTS.md wrangling.
It's a huge difference. It might be the result of very specific optimization, or perhaps simultaneous advancements in the harness play a bigger role, but in my books my kneck of the woods (or place on the long tail) only really came online in 2026 as far as LLMs are concerned.
It's just a point release and it isn't a significant upgrade in terms of features or capabilities, but it works... better for me.
My own experience is that some things get better and some things get worse in perceived quality at the micro-level on each point release. i.e. 4.5->4.6
At the end of the day they still produce code that I need to manually review and fully understand before merging. Usually with a session of back-and-forth prompting or manual edits by me.
That was true 2 years ago, and it’s true now (except 2 years ago I was copy/pasting from the browser chat window and we have some nicer IDE integration now).
This is why you have to reach to things that penalize adding parameters to models when running model comparisons.
That actually helps.
I mean, sure. but it's obvious in that graph that the single openai model is dragging down the right side. Wouldn't it be better to just stick to analyzing models from only one lab so that this was showing change over time rather than differences between models?
As they said, ragebait used to be believable.
There's only so much data to train on, and we are unlikely to see giant leaps in performance as we did in 2023/2024.
2026-27 will be the years of primarily ecosystem/agentic improvements and reducing costs.
Because it's not true. They have improved tremendously in the last year, but it looks like they've hit a wall in the last 3 months. Still seeing some improvements but mostly in skills and token use optimization.
I have heard rumors that token use optimization has been a recent focus to try to tidy up the financials of these companies before they IPO. take that with a grain of salt though
There was a long flat line before the step, models improve, but PR pass rate without human intervention is inherently a staircase function
> OpenAI’s leading researchers have not completed a successful full-scale pre-training run that was broadly deployed for a new frontier model since GPT-4o in May 2024 [1]
That's evidence against "intrinsically better". They've also trained on the entire internet - we only have 1 internet, so.
However, late 2024 was the introduction of o1 and early 2025 was Deepseek R1 and o3. These were definitely significant reasoning models - the introduction of test time compute and significant RL pipelines were here.
Mid 2025 was when they really started getting integrated with tool calling.
Late 2025 is when they really started to become agentic and integrate with the CLI pretty well (at least for me). For example, codex would at least try and run some smoke tests for itself to test its code.
In early 2026, the trend now appears to be harness engineering - as opposed to "context engineering" in 2025, where we had to preciously babysit 1 model's context, we make it both easier to rebuild context (classic CS trick btw: rebooting is easier than restoring stale state [2]) and really lean into raw cli tool calling, subagents, etc.
[1] https://newsletter.semianalysis.com/p/tpuv7-google-takes-a-s...
[2] https://en.wikipedia.org/wiki/Kernel_panic
FWIW, AI programming has still been as frustrating as it was when it was just TTC in 2025. Maybe because I don't have the "full harness" but it still has programming styles embedded such as silent fallback values, overly defensive programming, etc. which are obvoiusly gleaned from the desire to just pass all tests, rather than truly good programming design. I've been able to do more, but I have to review more slop... also the agents are really unpleasant to work with, if you're trying to have any reasonable conversation with them and not just delegate to them. It's as if they think the entire world revolves around them, and all information from the operator is BS, if you try and open a proper 2-way channel.
It seems like 2026 will go full zoom with AI tooling because the goal is to replace devs, but hopefully AI agents become actually nice to work with. Not sycophantic, but not passively aggressively arrogant either.
>To study how agent success on benchmark tasks relates to real-world usefulness, we had 4 active maintainers from 3 SWE-bench Verified repositories review 296 AI-generated pull requests (PRs). We had maintainers (hypothetically) accept or request changes for patches as well as provide the core reason they were requesting changes: core functionality failure, patch breaks other code or code quality issues.
I would also advise taking a look at the rejection reasons for the PRs. For example, Figure 5 shows two rejections for "code quality" because of (and I quote) "looks like a useless AI slop comment." This is something models still do, but that is also very easily fixable. I think in that case the issue is that the level of comment wanted hasn't been properly formalized in the repo and the model hasn't been able to deduce it from the context it had.
As for the article, I think mixing all models together doesn't make sense. For example, maybe a slope describe the increasing Claude Sonnet better than a step function.
I also wonder how much of the jump in early 2025 comes from cultural acceptance by devs, rather than an improvement in the tools themselves.
Perhaps we won't see a phase change like improvement as we did from gpt-2 through to 3 until there is several more orders of magnitude parameters and/or training. Perhaps we will never see it again!
What is getting rapidly better is scaffolding but this seems to be more about understanding and building tools around LLMs than the LLMs themselves improving.
I'm still excited about AI but not constantly hyped to the rafters as some.
I guess at least this person https://www.tomshardware.com/tech-industry/artificial-intell... might disagree. I think already to know what Kubernetes even is requires quite a bit of knowledge. Using a tool that manipulate its configuration files IN PRODUCTION without risking data loss is another ball game entirely.
Because hype makes money.
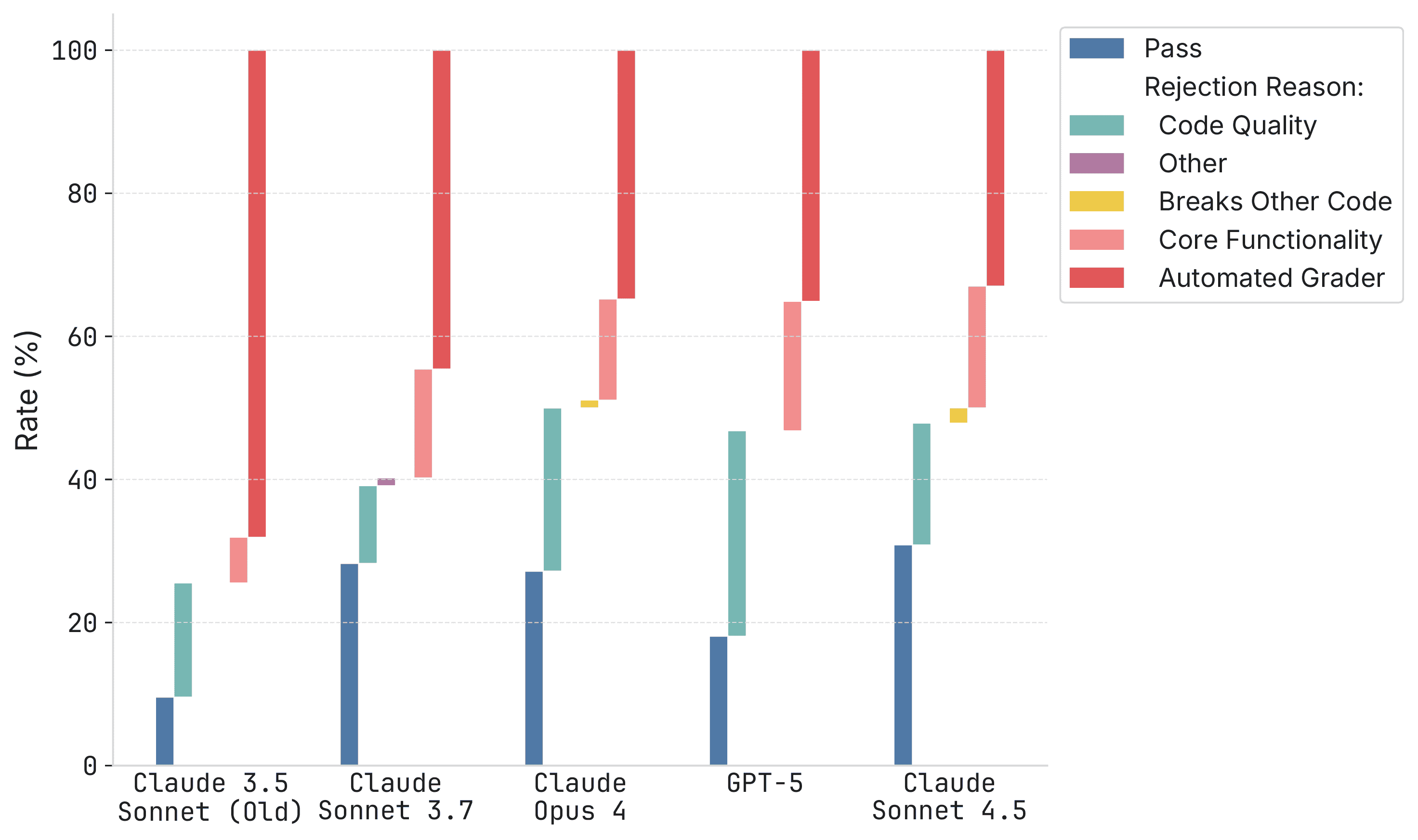{kind=link}