▲reply▲That pelican looks like it's in Miami for a crypto conference.
reply▲It looks like the starting soon screen of a crypto presentation
reply▲It looks like it’s been partying for 60 years based on the wrinkles on its pouch.
reply▲brindleth58 minutes ago
[-] It look like the start of a new viral Peliwave aesthetic
reply▲sorta looks like the Tron ripoff in the I/O keynote
reply▲irthomasthomas3 hours ago
[-] This is a perfect illustration of something I noticed with llm progress. Ask them to improve an svg like this, and it never fixes the missing crossbar or disconnected limbs, it just adds more stuff. In this example they have obviously improved greatly, and it contains a ridiculous amount of detail, but they still to get the basic shape of the frame wrong. It's weird. And the pattern shows up everywhere, try it with a webpage and it will add more buttons and stuff. I've even experimented with feeding the broken pelican svgs to an image model to look for flaws, and they still fail to spot the broken elements.
edit: fixed human hallucination
When you say "improve an svg like this", how are you imagining setting that workflow up? Are you just feeding them the SVG to iterate on; or are you giving them access to a browser to look at the
rendering of the SVG?
I ask because:
Insofar as the original pelican test is zero-shot, it effectively serves as a way to test for the presence of a kind of "visual imagination" component within the layers of the model, that the model would internally "paint" an SVG [or PostScript, etc] encoding of an image onto, to then extract effective features from, analyze for fitness as a solution to a stated request, etc.
But if you're trying to do a multi-shot pelican, then just feeding back in the SVG produced in the previous attempt, really doesn't correspond to any interesting human capability. Humans can't take an SVG of a pelican and iteratively improve upon it just based on our imagined version of how that SVG renders, either! Rather, a human, given the pelican, would simply load the pelican SVG in a browser; look at the browser's rendering of the pelican; note the things wrong with that rendering; and then edit the SVG to hopefully fix those flaws (and repeat.)
I imagine current (mult-modal and/or computer-use) LLMs would actually be very good at such an "iterative rendered pelican" test.
irthomasthomas2 hours ago
[-] I'm talking about two type of improvement, model improving, and prompt based improving. I am noticing that the baseline output has a lot more going on, the model has improved, yet it still makes those obvious looking mistakes with the shape of the frame or disconnected limbs etc.
And I am saying that if you take one of these SVGs and ask an LLM to look for flaws, it rarely spots those obvious flaws and instead suggests adding a sunset and fish in the birds mouth.
To a certain extent, it feels like a Sonnet 3.7 moment. Slightly overeager - you ask for a button color change, you see layout changes, new package dependencies, and the README rewritten from scratch - and not necessarily correctly.
When I ask for a pelican on a bike, I want the Platonic ideal of a pelican on a bike, not a vision of an alternative reality in which pelicans created bikes. Though, thinking about it again, maybe I should.
Their ability is best described as "spiky". To steal from aphyr: think kiki, more than bouba. Whats interesting is that a lot of the models seem to have similar spikes and "troughs", though there are differences.
reply▲reply▲Although every single render of those has pedals on the correct side as opposed to the Gemini optical illusion back pedal that tries to be both on the other side of the central gear and infront of the back wheel.
Not really a criticism but an interesting point that you would never expect a human to make that mistake even in a bad drawing.
Asking random people to write SVG gives even worse results
reply▲Especially without being able to look at the rendered output! (At least I'd be surprised if modern server-side tool calls regularly include an SVG renderer that can show a rasterized version to the model to iterate on it.)
reply▲I feel like it embodies Google's vibe of an uncool guy trying to stay relevant to the youth pretty well.
reply▲Wow what’s with all the styling? Is it manifestation of google’s styling bias? I like the result for sure. It’s shiny and pretty. But then it’s something I didn’t ask for.
reply▲Same old issue with Gemini models trying to "enrich" everything
reply▲at a certain point you're gonna need to change your benchmark because this will end up in the model's training set
reply▲I'm sure that certain point came and went many releases ago.
reply▲TacticalCoder50 minutes ago
[-] Love your pelicans, as always. And that one is... Wow.
I noticed the "Synthwave" aesthetic, which is enjoying quite some success since quite some time now, has found its way into AI models (even when it's not in the user's query). It's not the first time I see the sun at sunset with color bands etc. in AI-generated pictures. Don't know why it's now taking on in AI too.
https://en.wikipedia.org/wiki/Synthwave
Hence the comments here about the 90s, Sonny Crockett's white Ferrari Testarossa in Miami, etc.
To be honest as a kid from the 80s and a teenager from the 90s who grew up with that aesthetic in posters, on VHS tape covers, magazine covers, etc. I do love that style and I love that it made a comeback and that that comeback somehow stayed.
funny that when I try the same prompt, gemini generates an image, not an SVG.
something is not right.
reply▲That's likely because you're using the Gemini app which has a tool for image generation (nano banana) - I do my tests against the API to avoid any possibility of tool use.
reply▲This question makes me wonder if you one shot each pelican or do you run it a few times to get the best one?
reply▲I one-shot. I have a long-standing ambition to have each model generate 3x and then get the model (assuming it's a vision model) to pick the best one.
reply▲Beats a human by like 10$
reply▲unglaublich3 hours ago
[-] So according to Google logic, the value of the pelican is $10-eps.
(They applied that reasoning to conversions via adwords)
reply▲`<!-- Pelican Eye / Sunglasses (Cool Retro Aviators) -->`
wtf
`<!-- Gold Rim -->`
WTF??
GodelNumbering4 hours ago
[-] Per million input/output tokens:
Gemini 2.5 flash: $0.30/$2.50
Gemini 3.0 flash preview: $0.50/$3.00
Gemini 3.5 flash: $1.50/$9.00
Interesting pricing direction. I don't think we have ever seen a 3x price increase for in the immediate next same-sized model (and lol @ 3 only ever getting a preview).
3.5 flash costs similar to Gemini 2.5 pro which was $1.25/$10
This understates the cost increase. 3.5 Flash also uses more tokens. artificialanalysis.ai shows these difference to run the whole eval, which I think is more realistic pricing:
Gemini 2.5 flash (27 score): $172 (1.0x)
Gemini 2.5 pro (35 score): $649 (3.8x)
Gemini 3.0 Flash (46 score): $278 (1.6x)
Gemini 3.5 Flash (55 score): $1,552 (9.0x or 2.4x compared to 2.5 pro)
This is a massive price increase... 5.6x compared to Gemini 3.0 Flash
They probably never intended to keep serving cheap models. This is a natural way to introduce the squeeze, now that they have people who built services on their API. It makes a lot of sense to have an abstraction layer where the provider doesn't matter. If you are working in Kotlin, Koog is excellent.
reply▲switching models is insanely cheap compared to token cost on anything signficant, this is a take so cynical it misses the reality
reply▲in any corporate or half compliance-relevant setting switching isn't trivial. new DPA, subprocessor notifications, TIA, procurement review, security questionnaires, plus re-running your evals because prompts don't transfer 1:1. token cost is just one of the line items.
reply▲lanthissa15 minutes ago
[-] no it really not, even the soggiest bank has multiple api vendors atm.
reply▲> now that they have people who built services on their API
People really can’t wait to be the next Zynga
If Google is actually getting cheaper inference than everyone else with their TPUs, this smells like trouble to me. Maybe serving LLMs at a profit is proving difficult.
Or maybe they think because their benchmarks are good they can ramp up the prices. Seems like they don’t have the market share to justify a move like that yet to me.
tempaccount4203 hours ago
[-] This is not priced at inference cost.
My guess: it's the price at which they make more money than if they rent the TPUs to other companies.
The Gemini team has had trouble securing enough TPUs for their user's needs. They struggle with load and their rate limits are really bad. Maybe at a higher price, they have a better chance at getting more TPUs assigned?
The cost at such they could rent out the TPUs, i.e. the market rate, is the inference cost.
Just because you are vertically integrated doesn't mean you get to discount the one business units products to the other. Doing so discounts the opportunity cost you pay and is just bad accounting.
Look up “double marginalisation”.
reply▲Depends on if you have spare capacity I think. They have minimal competition so they might be maximizing profit by charging prices higher than what clears all their supply.
reply▲Prevailing wisdom is that
serving LLMs at a profit is achievable... it's when you factor in the cost of training them that prices get astronomical real fast.
Open-source model inference providers (who do not have to bear the cost of training) seem able to do it at much lower prices.
https://www.together.ai/pricing
https://fireworks.ai/pricing#serverless-pricing (scroll down to headline models)
Of course, it's possible that they are burning through investor cash as well, and apples-to-apples comparisons are not possible because AFAIK Google does not mention the size/paramcount for 3.5 Flash.
But if the prevailing wisdom is true, I think it's actually encouraging. It suggests that OpenAI and Anthropic could perhaps, if they need to, achieve profitability if they slow down model development and focus on tooling etc. instead. If true that's probably good news for everybody w.r.t. preventing a bursting of this economic bubble.
...my opinions here are of course, conjecture built on top of conjecture....
Not to discredit you, because you are 100% correct but tangential note about together.ai, they seem fairly unreliable with constant outages or higher than normal latency.
reply▲Its probably that in 1 or 2 years local (free) models will completely take the place of cheap models so cheap models need to move up the quality chain.
You have free local models for most tasks, $20 subscriptions for near-frontier intelligence, and API per token costs for frontier intelligence.
Flash seems to be targeting the near-frontier category.
TurdF3rguson2 hours ago
[-] That might work if it wasn't for FOMO. Are you ok with only $20 of frontier usage a month?
reply▲BoorishBears1 hour ago
[-] This is trouble if you're
not Google/OpenAI/Anthropic: they're all shifting towards pricing for the economic value of the knowledge work they're aiding.
The economic value increases non-linearly as models get more intelligent: being 10% more capable unlocks way more than 10% in downstream value.
That's trouble because the non-linear component means at some point their margins will stop primarily defined by the cost of compute, and start being dominated by how intelligent the model is.
At that point you can expect compute prices to skyrocket and free capacity to plummet, so even if you have a model that's "good enough", you can't afford to deploy it at scale.
(and in terms of timing, I think they're all well under the curve for pricing by economic value. Everyone is talking about Uber spending millions on tokens, but how much payroll did they pay while devs scrolled their phones and waited for CC to do their job?)
IncreasePosts4 hours ago
[-] Maybe the margins are just very large for Google because they predict so much demand for 3.5?
reply▲GodelNumbering4 hours ago
[-] This combined with locally runnable models getting pretty good recently (e.g. Qwen 3.6) tells me that it's time to seriously consider local dev setup again
reply▲Besides the cost you get the control, transparency and ability to identify small language models or LoRA you want to serve even more cost effective.
reply▲This should become the new Apple's hardware and software play. I am hopeful about the new CEO
reply▲We need another "Deepseek moment" or else it will become impossible for the regular dude to use AI. It will become something that only big companies can afford.
reply▲We're having DeepSeek moments every couple of weeks.
Qwen 3.6 hit hard in the self-hosting space. It's incredibly capable for its size, really shaking up what's possible in 64GB or even 32GB of VRAM.
The Prism Bonsai ternary model crams a tremendous amount of capability into 1.75GB.
And, DeepSeek V4 is crazy good for the price. They're charging flash model prices for their top-tier Pro model, which is competitive with the frontier of a few months ago.
The winners in the AI war will be the companies that figure out how to run them efficiently, not the ones that eke out a couple percent better performance on a benchmark while spending ten times as much on inference (though the capability has to be there, I think we're seeing that capability alone isn't a strong moat...there's enough competent competition to insure there's always at least a few options even at the very frontier of capability).
trollbridge2 hours ago
[-] We have Qwen 3.6-35b (6) on a 5090 (32GB) and it's blowing me away. Works fine for most (not all) code generation tasks. One developer here has been extremely stubborn about adopting AI; he's finally adopted it, albeit only when it's coming from a local model like this.
DeepSeek V4 Pro likewise is insanely good for the price. I simply point it at large codebases, go get a cup of coffee or browse Hacker News, and then it's done useful work. This was simply not possible with other models without hitting budget problems.
Any chance you'd be willing to talk further about your setup? I have 2 x 3090s in a local machine, and I'm still left with questions about how best to use stuff locally.
reply▲> It's incredibly capable for its size, really shaking up what's possible in 64GB or even 32GB of VRAM.
You can lower that to at least 24GB. I've been running Qwen 3.5 and 3.6 with codex on a 7900 XTX and the long horizon tasks it can handle successfully has been blowing my mind. I would seriously choose running my current local setup over (the SOTA models + ecosystem) of a year ago just based on how productive I can be.
Deepseek had another moment a few weeks ago. V4 isn't far behind the US frontier, and so far its flash variant seems a very reliable coder and costs a pittance.
reply▲Deepseek V4 (not flash) trippled in price too by the way (from Deepseek). Get used to this pattern.
This is what you get for relying on the generosity of billionaires. Keep offshoring your thinking ability to a machine and let me know how competitive you. Hint, you wont be. There's nothing special about being able to use an LLM.
Unlike other providers, Deepseek does promise that they will lower the price when their Huawei cards arrive in a few more months.
reply▲Give me a link. Cannot wait. One PSA is that they have 75% discount right now so it is already cheaper than the full price.
reply▲Weird, last time I checked it was right on the pricing page.
But even when it happens I doubt it would be as cheap as it is right now. Enjoy it while it lasts!
Anyone can host Deepseek V4 on rented GPUs and sell inference on it. Price will very quickly converge to the marginal cost of inference. This is as close to a pure commodity as it gets in the AI space so competitive market economics will put in work. Same is true for any open-weights model.
reply▲You dont understand the costs involved to run inference at scale
Please go run some numbers.The hardware needed to Run Deepseek v4 flash at 20 tps for a single session is nowhere close to what is required to run it at 50tps for 5,000 concurrent sessions.
Imagine what it takes to be profitible when running at 150 tps for 30cents per 1mm. You make less than 1k per month and the hardware required to run that cost 10k a month to rent with hardly any concurrent session capability.
> Please go run some numbers.
- DeepSeek serves DeepSeek V4 Pro at 27 tps: https://openrouter.ai/deepseek/deepseek-v4-pro
- At 27 tps per user, a B300 GPUS will give you around 800 tokens per second (serving 30 users): https://developer-blogs.nvidia.com/wp-content/uploads/2026/0...
- That's 800 * 60 * 60 generated tokens per hour, at a cost of $0.87 per 1M tokens, or $2.50 per hour.
- For input and output tokens, the math is a bit more complicated because we have to make assumptions about their ratio. Using the published values from OpenCode, we get another $2.50 for cached tokens (which are almost free for DeepSeek) and another $3.40 for input tokens (which are a lot cheaper to compute than output tokens), which gives us a total of $8.50 per hour per B300 GPU.
- B300 GPUs can be rented for as low as $3.40 per hour, which is less than $8.50, so hosting DeepSeek V4 Pro is profitable.
You could also host it at fewer tps per user to raise the efficiency and therefore the profit even higher.
Even not assuming Blackwell inference the $3.50/hr price is likely close to the marginal cost. The Deepseek R0 model is a little more than a third of the size of V4 and cost around $1/Mtok to serve at scale based on deepseek's blogs last year and Hopper rental prices.
reply▲Yes it is more efficient in $/tok to run at scale than to run just for yourself. Everyone selling Deepseek V4 inference is selling an undifferentiated good. They have run the numbers on how much it costs and are competing against a dozen other outfits also selling undifferentiated open weights tokens. Whatever the dollar cost they face to rent those GPUs will be what they are able to charge in the competitive market. That is great for you and me because we can buy tokens at pretty much exactly what it costs to produce them.
reply▲V4-Pro is about 2.4× total params and 1.3× active params of V3.2.
reply▲creationcomplex55 minutes ago
[-] You're typing as your handwriting and letter sending abilities deteriorate to dust. Writing down information as your memory capacity decays. Remembering instead of living at the pure leading edge of perception dulling your reactions.
Smh, it's all downhill from the first unadulterated neuron.
Mate why are you so mad at people upset the price trippeled? It's a fair complaint that people built services using the cheaper ones with the expectation future models would be similarly priced. You can avoid 'offloading thinking' while still building ontop of these models
reply▲I think demand is too great and compute is not enough. Nothing to do with billionaires colluding to increase prices by 3x.
reply▲Actually, why should Google collude on pricing? They have deep pockets and could starve out the competition while keeping prices low, if they really wanted.
I think it is priced high because it's basically their smartest model as well as their fastest, so why shouldn't they?
You can still use earlier generations of Flash at a lower cost if you want "fast and cheap and just OK," which often makes sense. (Just checked)
I would predict they will lower this price when 3.5 High appears, but perhaps not all the way.
What we need is a deepseek moment in hardware ie China reaching parity on node size that is the only way latest computers let alone latest ai will be available to us in the future otherwise the profit margins will push most production to AI.
reply▲throwa3562622 hours ago
[-] To be honest, China not having access to the latest hardware is exactly what has driven LLM technology forward the last 2 years.
reply▲Why?
reply▲Because it forced them to focus on efficiency, instead of throwing more compute at the problem.
Just like in software, some of the most beautiful solutions come from constraints. Think, the optimisations that game developers implemented because of the frame budget.
pianopatrick2 hours ago
[-] Maybe we can figure out better ways to use the models that can run on cheap hardware.
reply▲You can use lots of open weight models today.
reply▲Gigachad35 minutes ago
[-] The real problem is the hardware to run them is still very expensive.
reply▲That's one solution to the problem. But it still needs some good computational capabilities. Either we optimize the hell out of those models, or we wait for the hardware to become good enough for them.
reply▲GeorgeOldfield3 hours ago
[-] gemini isn't even that good. just tested 3.5 on usual complex prompts to opus/chat 5.5. meh
reply▲Are you really comparing flash to opus? Shouldn't you be comparing pro?
reply▲CognitiveLens2 hours ago
[-] The benchmark tables in the Google announcement include Opus 4.7, and the numbers are very impressive. Caveat emptor, but it's not unreasonable to compare a new Flash to a current-gen Opus, even if some of the results confirm expectations
reply▲Well, the first impression is that Gemini still goes off the instruction rails easier than other models, but I noticed that it tends to go back to the initial goal without holding a hand, which is a real improvement. It's really interesting that these models behave so differently.
reply▲Who would have guessed that something costing roughly a third as much wouldn't do as well at certain tasks.
reply▲3.1 flash lite — $0.25/$1.50 — plus insanely fast.
3.1 flash lite isn’t quite as good as 3 flash preview (which is the most incredible cheap model… I really love it) — but 3.1 is half the price and the insane speed opens up different use cases.
For comparison, Opus models are $5/$25
Opus 4.7 is smarter than even Gemini 3.1 Pro on nearly every metric, though. You're comparing apples to oranges. Gemini 3.1 Flash is somewhere in the neighborhood between current Haiku and Sonnet, I think? Still a better value than the Anthropic models, I guess, which are quite pricey.
Since Gemini 3.5 Flash is raising the price to $1.50/$9.00, it's priced between Haiku and Sonnet. If it outperforms Sonnet, it remains a good value, I guess. Though DeepSeek V4 Flash is much cheaper than all of them, and seemingly competitive.
>Opus 4.7 is smarter than even Gemini 3.1 Pro on nearly every metric,
Outside of coding, claude models are pretty meh. GPT and Gemini are the workhorses of science/math/finance.
robwwilliams18 minutes ago
[-] Not in my fields of science: Genetics and neuroscience. The combination of Opus 4.7 Adaptive used with well structure project folders is amazingly useful.
reply▲epolanski3 minutes ago
[-] And even on coding, they are mostly good at generating new code.
They sure are not at thorough analysis or debugging, etc.
WhitneyLand3 hours ago
[-] Their rationale might be that it’s size and intelligence are growing relative to the market.
Fwiw it’s beating Claude Sonnet in most benchmarking (benchmaxxing?), yet they’ve priced it almost half off on a per token basis.
Question is are you going to persuade anyone with this argument?
Are there many devs at Google who legit prefer Gemini over Claude and Codex? Would love to hear about that.
Gen AI is unprofitable, especially at the insanely cheap rates they've been offering to get people in the door. So expect more increases in the future.
reply▲These companies are unprofitable (as all companies at this stage and ambition should be) but I increasingly don't see any justification for the idea that it is
fundamentally unprofitable.
Inference alone is certainly profitable. I'm running models at home that are comparable to performance of paid models a year or so ago for free. Even for much larger models the cost around inference serving are clearly manageable.
Training is where the costs are, but I'm increasingly convinced those too could have costs dramatically reduced if necessary. Chinese companies like Moonshot.ai are doing fantastic work training frontier models for a fraction of the cost we're seeing from Anthropic/OpenAI.
This isn't like Uber or Doordash where the economics fundamentally don't make sense (referring to the early days of these services where rates were very cheap).
It's a compelling story that "current AI is unsustainable", but it doesn't pan out in practice for a multitude of reasons (not the least of which is that we can always fall back to what models did last year for basically free).
overrun1143 minutes ago
[-] Arguably nothing even has to change with training for this to be sustainable. Dario has claimed that Anthropic is profitable on a per training run basis. They aren't profitable because they choose to keep investing in increasingly large training runs.
reply▲ReliantGuyZ2 hours ago
[-] And if you can run those strong models at home for free, why would hosting them be a successful business for any of these providers?
Profitable maybe, in terms of having low costs, but why pay Google or whoever when you can do it yourself for cheaper/"free"?
If you can run your server at home for free why would hosting it be a successful business for any of these propviders?
reply▲reply▲anthonypasq2 hours ago
[-] Amazon was unprofitable for over a decade, and they were public. Theres no incentive to be profitable as a private company if you can continue to raise money.
Ed Zitron and Gary Marcus are... confused.
mynameisash55 minutes ago
[-] > Amazon was unprofitable for over a decade, and they were public.
Amazon was unprofitable because they poured their revenue into growth. On paper, they were in the red, but everyone - especially investors - saw what was going to happen, given their trajectory.
Is it the case that any of these AI companies are actually making a ton of money and growing accordingly? AFAICT, we've just got [a] big players like Google that can subsidize AI in the hopes of waiting everyone else out and [b] private companies raising capital in the hopes that when the market returns to rationality, they may be solvent.
overrun1138 minutes ago
[-] Yes that is exactly what is happening. OpenAI and Anthropic are the fastest growing companies by revenue ever and their gross profit margins are healthy.
reply▲mynameisash27 minutes ago
[-] According to this article[0]:
> HSBC Global Investment Research projects that OpenAI still won’t be profitable by 2030, even though its consumer base will grow by that point to comprise some 44% of the world’s adult population (up from 10% in 2025). Beyond that, it will need at least another $207 billion of compute to keep up with its growth plans.
This article is from six months ago. Was HSBC wrong; did something dramatically change in the last six months; is OpenAI not, in fact, profitable?, or are they in fact doing well but doing a huge investment (as was the case with Amazon 25ish years ago)?
I genuinely do not know, but my impression is that they're burning investment capital trying to compete with others' investment capital and Google's bottomless pockets.
[0] https://fortune.com/2025/11/26/is-openai-profitable-forecast...
But I've been told here -- over and over again -- that the cost of inference was going to go down as the technology matured.
The trend lines are going in the opposite direction.
His entire brand is that the AI bubble will burst. By his account it was supposed to have several times by now. Like the doomers, it's not if it's when and they have to keep pushing back their predictions. Funny how both camps can be so confident. Alas, that's how they get eyes, ears and dollars.
That's not to say they will be or are wrong, it's just that they aren't exactly unbiased, or humble, sources.
Yeah, at this point I think the worst-case scenario for OpenAI/Anthropic/etc is to slow down frontier model development and focus on tooling and services, as opposed to imploding completely and bursting the economic bubble. I hope?
reply▲If you don't need SOTA or near SOTA there are plenty of dirt cheap models, just look at Gemma 4 31B on Openrouter.
reply▲Gigachad34 minutes ago
[-] For all of the use cases being hyped you really do, and you actually need something much better than the SOTA models to do what we are being told can be done.
The small models are useful for small things like summarizing text or search but not much else.
It is insanely profitable though, if you cut out r&d cost, plus the marketing and loss leaders. Don't let them gaslight you.
Even anthropic who does not own any hardware still have a big margin providing claude models.
Then why haven't they reported any profits using GAAP (generally accepted accounting principles)? They all use ARR which is easily gamed.
reply▲overrun1132 minutes ago
[-] They aren't profitable on a GAAP basis and no one claims this. This obsession over profits is misguided. These are hyper growth companies growing at a scale never seen before. It is both deliberate and uncontroversial to invest in growth rather than slowing down to produce profits.
reply▲I don't really sure, but might be they count hardware purchase as loss, too.
Google has just recently upgraded their TPUs.
Everything is insanely profitable if you ignore the costs.
reply▲operatingthetan45 seconds ago
[-] They immediately undercut their argument to the point that I'm not sure if they were being sarcastic.
reply▲To be fair, Gemini 3.1 flash _lite_ supports structured output (guaranteed json), it’s super fast, runs circles around 2.5 flash and costs $0.25/$1.50.
I use it _a lot_ and it’s very capable if you just plan correctly. I actually almost exclusively use 3.1 flash lite and 2.5 flash lite (even cheaper) and we have 99.5% accuracy in what we do.
That said, I think we’ll see the lite/flash models and the pro models will diverge more price wise. The pro models will become more and more expensive.
I don't think they're really comparable. Seems they created the Flash-Lite tier to take the spot of the old Flash models.
reply▲In general, Gemini flash is still relatively cheaper compared to the "mini" version of the other big 2. However, I agree that newer version seem to have multiple X price increase (similar to the new ChatGPT) and we certainly need competition from the open source models to keep these guys in check with pricing.
reply▲Yeah, it is a massive jump in price, hardly a "Flash" model anymore... I wonder if they'll release flash lite or something with a bit more affordable price point.
reply▲There’s already a flash lite tier since 2.5. Latest is 3.1 currently.
reply▲It might be temporary pricing given that 3.5 Flash is actually superior to the existing 3.1 Pro in almost all regards, so they're in a bit of a lurch as 3.1 Pro really doesn't make sense given that 3.5 Pro has been delayed a bit.
reply▲That's a lot. DeepSeek v4 Flash is just over a tenth the price, and DeepSeek v4 Pro is roughly the same price (currently heavily discounted, but will be $1.74).
I mean, the benchmarks for Gemini 3.5 Flash are very strong, but at those prices it has to be. I guess the time of subsidized tokens from the big guys is slowly coming to an end.
They have said AI will be priced like a utility, meaning $100-300 per month or so.
reply▲At the same time, it is supposedly Gemini 3.1 Pro level at 3/4 the price
and far cheaper than comparable models, Gemini Pro is cheaper than Claude Sonnet (Anthropic still gets to charge a brand premium)
throwa3562622 hours ago
[-] Gemini 2.5 flash was the best Gemini model.
Not the most intelligent but perfect balance of cheap, fast and not-too-dumb.
just subscribe to the plan, cheaper
reply▲reply▲reply▲Well, honestly this is quite impressive compared to 3.1 Flash Lite and 2.5 Pro. Considering that 2.5 Pro is actually quite good at generating massive amounts of code one shot.
reply▲It isn’t animated at all for me?
reply▲It is animated just no movement like on my 3.5 flash examples. Try different browser might be unless it iOS.
reply▲reply▲Here is a GPT 5.5 Extra High with a modified instruction:
> Create animated SVG of a frog on a boat rowing through jungle river. Single page self contained HTML page with SVG. Use the Brave Browser to verifty that the image is indeed animated and looks like a proper rowing frog; iterate until you are satisfied with it.
It was able to discover and fix an animation bug, but the result is still far from perfect: https://gistpreview.github.io/?029df86d03bfe8f87df1e4d9ed2f6...
Wow that's terrible. Any idea why?
reply▲Did you see the other ones? This is very good by comparison.
reply▲Yeah, the oars being around (inverted) is very distracting but the other elements appear quaint and "accurate".
reply▲stingraycharles31 minutes ago
[-] I think Anthropic optimizes less for visuals. Also, it’s not that terrible.
reply▲All three links animate for me.
reply▲NitpickLawyer4 hours ago
[-] I think they mean the boat is moving. In the flash ones the paddles are animated but the boat is stationary for me.
reply▲The boat moves in all three for me
reply▲The boat itself rocks, but do you see the background changing to indicate the boat is progressing through the environment? I only see that in the 3.1 Pro example. I believe that's what the OP meant.
reply▲I think this illustrates the problem with OP's prompt. If the goal is specifically to implement a scrolling background, this should have been in the prompt.
reply▲Yup. My bad. It was just first idea that come to my mind since I enjoy visually compare each new release with unique prompts.
reply▲These are hilarious. 3.5 Flash Thinking High is the only one that is weirdly deformed (what is going on with the hat in 3.1 Pro??)
reply▲Your links are broken FYI.
reply▲Am I really so old that when someone says "Flash" my immediate response is... "consider HTML5 instead" ??
reply▲Very little of what made the Flash culture so fun made its way into HTML5.
reply▲I dunno, the tools are kind of there. Browsers have canvases and JavaScript and SVGs and sound. The communities are around; they're just kind of dispersed. There's no one website that is THE place for fun stuff. Instead, there are dozens, and most of them suck.
There's still fun stuff, though. I stumbled upon this bit of insanity just yesterday: https://tykenn.itch.io/trees-hate-you. It would have fit in fabulously with the old Flash sites.
moritzwarhier1 hour ago
[-] Edit: looks like you linkes something created with Unity?
Not sure, I'm not versed in game dev. So maybe my point about creation tools is moot.
However, 3D content always seems very samey to me, in a way that cartoons and regular animation don't. So the rest of my comment should still express what I mean.
---
Flash had a WYSIWYG editor aimed at media creators who treat programming at best as an afterthought.
Flash was mostly about ease of tweening and extremely flexible vector graphics engine combined with an intuitive creation tool.
So the "Flash vs HTML/JS/SVG/CSS..." debate is not just about technical capabilities of the medium.
Of course there are many fun web apps in the browser, or as native apps, too. But Flash attracted all kinds of slightly nerdy people with cultural things to say, not just web devs with a lot of free time.
What "HTML5"/browser web technology doesn't offer is this intuitive, visual creation pipeline, and this kind of speaks for itself!
Also, I think the Flash "creator's" age is not separable from its time: using Flash wasn't trivial either.
There were just more people with interesting ideas, free time, and a wholistic talent for expressing their humor and ideas, combined with the curiosity and skill to learn using Flash (of course only as a licensed copy purchased from Macromedia).
People like this today are probably more often hyper-optimizing social media creators, and/or not terminally online.
In other words: I don't think the typical Newgrounds creator would have taken the time and effort to translate a stickman collage, meme, or other idea into a web app / animation.
---
And to add even more preaching: I think that "creating" things using AI produces exactly the opposite effect: feed it an original idea, and the result will be a regression to the mean.
Gigachad30 minutes ago
[-] It's not quite the same but it seems the people who used to be publishing flash games are now making indie games on Steam. With modern dev tools and engines it's possible for one person to make what used to be a team effort before.
The whole "friendslop" genre is what replaced flash games.
They were CPU killers but man those Flash websites were gorgeous (talking mostly about MU Online "private" servers)
reply▲It was probably the right call at the time with low bandwidth. Nowadays I bet flash would execute faster than most js heavy sites :D
reply▲The Flash designer was really nice. One thing the web kind of set back was all the RAD tools from the 90s and 2000s.
reply▲And there were some amazing RAD and prototyping tools in the 90s (mostly for DOS, but also for Windoze desktop apps.) You're right, we sort of gave up on the idea when everyone wanted to be seen as a "real" software engineer who knew how to sling Java on the back end.
reply▲Lol. Young uns!
Flash, ah, ah, saviour of the universe. Flash, ah, ah, he'll save every one of us!
Every time I have heard the word flash for goodness knows how many years.
If Google can reuse the "Flash" brand, I'm re-branding myself as "Meadhbh the Merciless."
reply▲lern_too_spel32 seconds ago
[-] They also announced Antigravity CLI, which uses Gemini 3.5 by default. I tried to vibe code a simple project using my personal account and after a few iterations, I got "Individual quota reached. Contact your administrator to enable overages. Resets in [7 days]." Really? 7 days? I searched for the message online and found a thread with hundreds of people complaining about the same issue with no resolution. Classic Google.
reply▲I have google ai pro plan and tried antigravity with 3.5 flash but it used up all my quota in two prompts. If that is not a bug then it is seriously unusable.
reply▲Yesterday, or the day before, Google lowered the AI Pro quota from 33x standard usage to 4x.
From the talk on the Gemini subreddit it's severely lower than before. I'm likely canceling my AI Pro.
The update also broke the app for me. Editing a message crashes the app every time. I'm on a Pixel lol
reconnecting4 hours ago
[-] Knowledge cutoff:
January 2025Latest update: May 2026
I have a very bad feeling about this lag.
At least in some cases, there seems to be a move toward training on more synthetic data and strictly curated data, especially for smaller models where knowledge can't be extremely broad, because there just isn't enough room to store the world in tens or hundreds of gigabytes of model weights. So, to achieve higher quality reasoning, the training has to be focused and the data has to be very high quality and high density.
With strong tool use, it maybe doesn't even matter that the models are using older data. They can search for updated information. Though most models currently don't, without a little nudge in that direction.
Also, I believe the Qwen 3 series are all based on the same base model, with just fine-tuning/post-training to improve them on various metrics. Maybe everything in the Gemini 3 series is the same, and maybe they're concurrently training the Gemini 4 base model with updated knowledge as we speak.
reconnecting2 hours ago
[-] > it maybe doesn't even matter that the models are using older data.
This actually really does matter. Otherwise, the model simply won't know about your product and will always suggest only a few market leaders.
Searching for information on the Internet became a jungle a decade ago, and to be visible you have to pay Google for sunlight. Now, we risk falling into real darkness — until some paid model eventually emerges. This might be the reason Google is fine with training data from 2024. If the top spot is reserved for whoever pays anyway, why bother?
That's a different problem than I thought you were worried about. I wasn't considering the marketing angle, though that is certainly relevant and a risk to consider, especially when it comes to Google, whose primary businesses are ads and surveillance.
reply▲Can you explain what you mean?
reply▲reconnecting3 hours ago
[-] LLM pre-training models risk being unable to be updated with data from after 2025, as much of it is corrupted with LLM-generated content. We might be locked into outdated knowledge, where only whitelisted sources decide what to include.
Taking into account the sometimes blind belief that 'LLMs know everything', the outcome could be very costly, especially for technologies and businesses unfortunate enough to emerge after 2025.
But ChatGPT has been popular since early 2023, and even before it there was no shortage of low-quality content on the web.
If anything, this model being trained up to 2025 is a positive sign that the "circular LLM training" problem hasn't (yet) become unmanagable.
The year-long delay is probably just due to how long it takes to test/refine a cutting-edge model. It's surely possible to train one faster, but Google wouldn't want to release a new model unless it's going to top the usual benchmarks.
Looking at token usage at places like OpenRouter as a proxy for overall production we're looking at exponential growth in AI-created content. Weekly token usage there has tripled just in the past 3 months.
reply▲Considering all models can use search engines, is this really relevant?
reply▲reconnecting1 hour ago
[-] Until they prefer not to search. Let me explain using the example of the open-source security framework (1) our team is working on.
If you ask Gemini what you should use to integrate fraud prevention or account takeover protection into your product, there will be no mention of our open-source project. Five years in development, 1.3k stars, over 140 pull requests — all this isn't enough to make it into the training data. From this perspective, any technology that emerges after 2024 is simply invisible to LLMs.
The answer is: without being in the training data, LLMs basically don't understand what they're searching for.
1. https://github.com/tirrenotechnologies/tirreno
ordersofmag43 minutes ago
[-] I just put the terribly generic query "what tools would you recommend to integrate fraud prevention or account takeover protection into my product" into both Claude (Sonnet) and Gemini (3.1 Pro) via the standard web interface and both took the first step of searching the web. That's consistent with my past experience -- the usual harnesses typically will search the web in cases where I might expect/want them to. Now whether you product has good web visibility or not in those searches and how the LLM's weigh the relative merits of open-source tools versus commercial offerings in deciding what to highlight in their responses is a different issue. As is the change in what constitutes effective SEO in an era where bots, rather then human eyes are the proximal important target. But I don't think the core issue with folks finding your products is the move away from user-driven search toward using models with out-of-date training cutoffs.
FWIW while neither model included your product in it's initial response, when I followed up with "what about open-source" both did another search and Claude's response included your tool....
It might indicate core model training and pre training is really slowing down?
reply▲mixtureoftakes3 hours ago
[-] also parsing is harder + so much more of the new data is being generated by ai itself.
still the cutoff is very much concerning and inconvenient
you really shouldn't have them pulling facts from their weights, they need grounding from real data sources
reply▲margorczynski1 hour ago
[-] Wow at the price hike. Still I think in the long run the Chinese will win if they're able to produce hardware comparable to Nvidia.
reply▲3x price increase for a similar model almost. And they said AI would be cheaper and ubiquitous.
reply▲or 3/4 the price (of 3.1 Pro) if we believe their benchmarks
reply▲The price is crazy.
And I guess Gemini 3.5 pro will have the pricing increment, too. 12 x 5 = 60?
It seems like google does want us to use Chinese models.
What exactly are you doing with this that you can’t generate $1.50 of value per million tokens?
reply▲Generate 5x more value for the same amount of money.
reply▲nikhilpareek132 hours ago
[-] worth noting that Google marked this stable rather than preview, which is unusual compared to their recent releases. Pair that with the 3x price hike and flash pricing now reads like long-term floor they want, not a temporary thing they will walk back later. But its hard to tell yet whether that's Google specifically reading the room or the whole industry quietly resetting the cheap-inference baseline.
reply▲OsrsNeedsf2P4 hours ago
[-] Beats 3.1 Pro for price per token, but artificial analysis is showing it's dumber per token and costs more overall
reply▲Arena.ai is saying "Gemini 3.5 Flash’s pricing shifts the Pareto frontier in Text. 8 models from GoogleDeepMind dominate the Text Arena Pareto curve where only 4 labs are represented for top performance in their price tiers."
https://x.com/arena/status/2056793180998361233
Not sure what to think about this. There is no even GPT 5.5
reply▲Yeah, bummer. I was very excited for this release, but this killed it.
reply▲The pricing is an issue.
reply▲$1.5/m input tokens
$9/m output tokens
6x the price of 3.1 flash lite
"Flash-Lite" is a different product from "Flash", which is more expensive. They couldn't be more confusing with their naming though, especially since they have 3.1 Pro and not 3.1 Flash non-lite.
reply▲I haven't used 3.5 at all yet, but previous Gemini (and Gemma models) are by far the most token light per task than any other model.
Cost per task is a more productive measure, but obviously a more difficult one to benchmark.
I don't think input/output pricing matters, 90% of the cost is cache. $0.15 is pretty good, but still very expensive.
reply▲It depends on the use-case. yes, 90% of cost is cache in agentic coding scenarios (actually 95% in my experience). But not when the model reasons for 200k+ tokens before answering a complex problem.
reply▲gemini models solve a problem in 80% less tokens so that's something to think about.
reply▲Gemini caching is confusing though:
$0.15 / million tokens
$1.00 / 1,000,000 tokens per hour (storage price)
I much prefer the OpenAI/DeepSeek way of pricing caching where you don't have to think about storage price at all - you pay for cached tokens if you reuse the same prefix within a (loosely defined) time period.
In our experience, caching is not very reliable with google. We always get random cache misses that don't happen with other providers. We find OpenAI, Anthropic and Fireworks (which we use a lot) all have higher cache hit rates. So it's not only about the costs of cached token but also what kind of cached hit rate you get.
reply▲In my experience Google is the most flaky in general, which is surprising considering the rock solid history of their search and other products. Just more likely not to respond at all, to give a response out of left field, to handle the same error in 12 different ways randomly (a rainbow of HTTP status codes and error messages), etc etc.
reply▲I agree. The
https://aistudio.google.com/ is shockingly bad. I'm not sure I've ever used such a flaky Google service before. It's so much worse than Gmail or Google, not to mention ChatGPT or Claude or DeepSeek or Kimi or Midjourney web interfaces. The bizarre janky integration with your Google Drive, or Gemini or NBPs randomly erroring out, often indefinitely. I've had sessions refresh themselves and just... disappearing. Or when you get frustrated with a buggy dead session and hit 'new session' and have to wait minutes for 'saving...' to happen.
Exactly our experience too. Effectively we catch these and on these status codes, we send to OpenAI. Retrying the same query in Gemini has high chance to give kind-of the same status code.
reply▲10% of input pricing is standard especially compared to competition.
reply▲yah, which means that the input cost is the only value that should be paid attention to at the end + the cache discount (x10). If google would start offering x20 discount it would make it twice as cheap while input and output stayed the same.
reply▲While I am excited, the price compared to gemini 3 flash preview which I used for the longest time is x3 more. Upon arrival of deepseek v4 flash, I am a happy user of deepseek. We will see how long that reign would last after I try this new gemini.
reply▲Yikes. I think the concept of a 'flash' model is changing, no? Google used to market this as its lower-intelligence, faster, cheaper option. I appreciate that they are delivering on both of those, but personally I would appreciate if they could create an incremental knowledge improvement while holding price steady. Fortune 500 companies have to make their money I guess.
reply▲My guess is Gemini Pro coming later will be 2x more, bringing it comparable to Opus’s pricing.
reply▲That would be Flash Lite now, and I'm also interested in the cheaper end of things so kinda disappointed they didn't release 3.5 Flash Lite at the same time...
reply▲How is this progress? The token cost just keeps going up and up. Flash is the new Pro? Do the models actually cost more to run or is it fattening margins?
reply▲I have to admit that 3.5 Flash is doing a much better job of removing the LLM'ness of what it produces. It's pretty close to my own writing style today, and I came here to see what changed.
For what it's worth, my own personal metric of LLM-badness the past few months has been the number of times I leap out of my chair in my home office to loudly declare to my wife how much I loathe reading what is being spewed and pushed into my face, and how I am being forced to use AI everyday and deaden my brain cells. Today is like a breath of fresh air.
Engineers at google have publically stated that the models are too big and are far from their potencial. Glad they're being proven right with every release.
They continue to focus on smaller models while openai and anthropic are increasing compute requirements for their SOTA models.
Given the cost increase associated with this model, and previous model releases, I think the size is trending upwards, not down.
reply▲The speed says otherwise. I think they're increasing costs since they want to start seeing ROI.
reply▲Those are (mostly) new, faster TPU
reply▲latest TPU's appear to reach 800tok/s rather than the advertised 300tok/s.
reply▲mgambati51 minutes ago
[-] They demoed today 8i running ate 1300 to 1600ish tokens per second. I imagine that is caused by having a single rack serving the model just for the demo.
reply▲himata41135 minutes ago
[-] There's a limit to how much you can "scale" this process, it's linear, but if we did napkin math based on vllm parallel batched streams only lose around ~50% performance compared to single-stream output so doesn't explain the ridicioulusly fast numbers here.
I wish google just came out and told us how large their flash model is, because if it's as big or smaller than gpt-5.4-nano that's the real headline here.
> Engineers at google have publically stated that the models are too big and are far from their potencial
Can you link to a source?
Source please cause i dont believe that for once second
reply▲Don’t let that fool yourself.
Google will have SOTA models as big as or even bigger than their competitors.
They are just refining their current models while they finish training the next generation.
They will all come out at about the same time. Anthropic, OpenAi, Google, xAI
Anthropic has been sitting on Mythos for a while now. I guess they don't feel pressured to fuck it ship it until anyone else gets a 10T to work.
reply▲throwa3562624 hours ago
[-] reply▲That claim keeps contradicted hard by other parties, who say Mythos beats 5.5 resoundingly on both autonomous search and discovery and creation of complex exploit chains.
There might be a harness difference, but also, this CTF-type benchmark might not capture the capability difference fully.
It's doubtful they have the compute to make mythos publicly available even after the SpaceX datacenter deal. And why sell it publicly if people are still willing to pay for Opus 4.7?
reply▲outside12344 hours ago
[-] I suspect that Mythos doesn't have a business model that works
reply▲Google’s pro models are almost certainly bigger than Openai’s lol
reply▲Why would that be? I am curious why do you think that.
reply▲E.g. because they are behind on research and so must compensate with size to achieve similar level of intelligence. At least this is what I heard.
For intelligence/size only OpenAI and Anthropic are the frontier. Google has more compute so it can compensate for that with size of the models...
snovv_crash2 hours ago
[-] I'd argue Qwen is pushing the Pareto frontier considerably further when you take size into account.
reply▲ActorNightly3 hours ago
[-] Because TPUs are more efficient, and its cheaper for them to field them in higher quantity since they own the chip.
reply▲ActorNightly3 hours ago
[-] I mean, yes and no.
Nobody really knows the answer to which one is more optimal
* Large model trained on a large amount of data across multiple domains, that doesn't need any extra content to answer questions.
* Smaller model that is smart enough to go fetch extra relevant content, and then operate on essentially "reformatting" the context into an answer.
The demo of the model in Antigravity automatically rename and categorize unstructured assets using vision was quite cool, it demodulates that the IDE sidepanel can be used for more than just coding. I wonder if the harness in Antigravity is based on Gemini cli or if they are completely different. Could Gemini cli do the same task? Or is the vision feature a Antigravity thing?
reply▲China: we don’t need to use US models, we can distill them ourself
Google: we don’t need Chinese to distill our models, we can do it ourself
Arena.ai:
> Gemini 3.5 Flash’s pricing shifts the Pareto frontier in Text. 8 models from
GoogleDeepMind dominate the Text Arena Pareto curve where only 4 labs are represented for top performance in their price tiers.
https://x.com/arena/status/2056793180998361233
Given how widely varying the amount of tokens each model uses for a given task, "price-per-token" is essentially meaningless when doing this sort of comparison.
Artificial Analysis's "Cost to run" model (aka num_tokens_used * price_per_token) is much better, but even that is likely problematic since it's not clear whether running a bunch of benchmarks maps cleanly to real-world token use.
Google shot it's shot with that alternative history artwork generation
fiasco. Don't know why anyone would be too hot for them now.
Dime a dozen at this point.
reply▲I think the number of people still holding a grudge for that today is small.
reply▲Early Claude was a weak simulation of Goody2.ai. Things change. Being a lover or hater of a model doesn’t make sense. It’s just tech. Run evals. Then use.
reply▲Can anyone who has extensive, recent, experience with Claude code and Codex contextualize the current Gemini CLI product experience?
reply▲My anecdote: smart but too stubborn to be useful.
I have been trying Gemini since 2.5 for coding.
It is the smartest for creative web stuff like HTML/CSS/JS.
But it has been very stubborn with following instructions like AGENTS.md.
And architecturally for large projects I tested, the code isn't on par with Opus 4.5+ and GPT 5.3+.
I would rather use DeepSeek 4 Flash on High (not max) than Gemini even if they had the same cost.
I currently use GPT 5.5 + DeepSeek 4 Flash.
BUT I didn't test Gemini 3.5 Flash yet. And it seems, from another comment in this post, that the Antigravity quota for is bricked for Google Pro plans which is the plan I have. So I don't have high hopes.
mpalczewski57 minutes ago
[-] Gemini models have consistently disregarded rules and gone their own way for me. They will finish a task and get it done frequently way above the scope that you gave it, but they take a million shortcuts to get there. e.g. deciding the linter isn't important and disabling the pre commit hook. coding features you didn't ask for.
reply▲I have and use both Claude Code and Gemini CLI, and still don't consider Gemini worth starting for coding except to review Claude's output in critical commits (on a security boundary, maybe broad refactors, etc.), though I try side-by-side every now and then just to see the state of things. I also use Gemini Pro in a security scanning harness to act as a second set of eyes, but Opus is better at finding security bugs than Gemini, so I don't know that it's accomplishing anything beyond just using Opus.
Gemini Pro 3.1 for agentic coding is still clumsy. It chews a lot, has a harder time with tools and interacting with the codebase. I haven't tried any 3.5 version, yet, though. The benchmarks look promising.
I'll note I like the Google models' prose better than any others at the moment, though. Even the small open models (Gemma 4 family) have excellent prose, relatively speaking, that doesn't stink of the LLMisms that I find so annoying about OpenAI (especially) and Anthropic models. So, I'll probably start using Gemini for writing API docs, even if all code is Claude.
I would argue that prose is just a prompt issue. GPT 5.5 outout is easier to control whan Gemini by prompting. Having better defaults does not make it necessarily better.
reply▲I would disagree. I think it'd take a lot of prompting to make GPT 5.5 not have the underlying personality of GPT, which I find awful. They have knobs in ChatGPT to choose a "professional" tone, which improves it somewhat, but even that is still the worst prose of any leading model.
My default AGENTS.md/CLAUDE.md/etc. is a few sentences from Strunk and White, to try to make all the models not suck at writing. It helps keep the models brief, but it doesn't actually make models with shitty prose have good prose. The relevant portion of my agents file is: "Omit needless words. Vigorous writing is concise. A sentence should contain no unnecessary words, a paragraph no unnecessary sentences, for the same reason that a drawing should have no unnecessary lines and a machine no unnecessary parts." Which might add up roughly the same as "be brief" in the weights, I don't know.
If you have a prompt that makes GPT a decent-to-good writer, I would like to see it.
Gemini produces decent-to-good prose without prompting, which improves if instructed to be concise. The other models, even the frontier models, do not have decent-to-good prose without prompting, and even with prompting, rarely elevate to what I would consider Good Enough. Part of this may be that GPT and Claude models get used a lot more heavily, and so I'm highly tuned into their idiosyncrasies. The heavy use of emojis, the click-bait headline style, etc. that they both use unprompted. All of that is repugnant to me, so anything that doesn't do all that by default, or at least not as aggressively, has a huge leg up.
victor900051 minutes ago
[-] There was a brief moment in time where Gemini was the greatest thing since sliced bread, then it got nerfed from outer space without a version bump or any meaningful mention from Google, no thanks.
reply▲Is there a good benchmark tracking hallucinations? The models are all incredibly good now, even the open ones, and my hope is that the rate of hallucinations is something that's falling off in concert with larger and larger context lengths.
reply▲People complain about them incessantly, but I can almost never get people to actually post receipts. Every provider allows sharing chats, and anyone can share a prompt that reliably produces hallucinations.
More often than not, people are using images in responses that go awry. Which is fair, the models are sold as multi-modal, but image analyses is still at gpt-4.0 text-analyses levels.
Also knowledge cutoff issues, where people forget the models exist months to a year or more in the past.
https://gemini.google.com/share/9cd8ca68025aI was trying to understand a game I've been playing, The Last Spell. I asked it for a tier list of omens -- which ones the community considers most important. At least a few of the names it posts are hallucinated ("omen of the sun" does not exist, and the omens that give extra gold are "savings," "fortune," and "great wealth").
Obviously not a critical use case but issues like this do keep me on my toes regarding whether the thing is working at all. I should ask 3.5 flash to do the same job. (I did try and it once again hallucinated the omen names and some of the effects.)
reply▲I see constant hallucination in claude code when using specific tooling: It thinks it knows aws cli, for instance, but there's some flags that don't exist, it attempts to use all the time in 4.6 and 4.7. When asked about it, it says that yes , the flag doesn't exist in that command, but it exists in a different command (which it does), and yet, it attempts to use it without extra info.
Claude also believes it knows how AWS' KMS works, quite confidently, while getting things wrong. I have a separate "this is how KMS replication actually works" file just to deal with its misconceptions.
For gemini, I typically use it to query information from large corpuses, but it often web searches and hallucinates instead of reading the actual corpus. On a book series, it will hallucinate chapters and events which, while reasonable and plausible, do not exist. "Go look at the files and see if your reference is correct" shows that it's not correct, and it's a mandatory step. But that doesn't prevent hallucination, but makes sure you catch it after the fact, just like a method in a class that doesn't exist gets found out by the compiler. The LLM still hallucinated it.
vitorgrs15 minutes ago
[-] Just ask any real question about stuff. LLM is not about code only...
reply▲I can reliably produce hallucinations with this genre of prompt: "write a script that does <simple task> with <well known but not too-well-known API>." Even the frontier models will hallucinate the perfect API endpoint that does exactly what I want, regardless of if it exists.
The fix is easy enough though, a line in my global AGENTS.md instructing agents to search/ask for documentation before working on API integrations.
sapneshnaik3 hours ago
[-] Yeah. Better to have more details in your prompt than fewer. For example, I use this:
```
Build a Nango sync that stores Figma projects.
Integration ID: figma
Connection ID for dry run: my-figma-connection
Frequency: every hour
Metadata: team_id
Records: Project with id, name, last_modified
API reference: https://www.figma.com/developers/api#projects-endpoints
```
Note: You do need a Nango account and the Nango Skill installed before it could work.
I asked gemini 3.1 Pro to search for the linkedin URLs for a list of peers. It generated a plausible list of links -- but they were all hallucinated. On a follow up it confirmed it couldn't actually search, but didn't tell me that without prompting.
reply▲Are the knowledge cut off issues well known? I don't remember seeing them prominently displayed.
Also, prompts that reliably produce hallucinations is kind of a hard ask. It's inconsistent. One day the LLM I work with quotes verbatim from the PCIe spec and it's super helpful. The next day it gives me wrong information and when I ask it what section of the spec that information comes from it just makes up a section number
"People complain about them incessantly, but I can almost never get people to actually post receipts."
...my chats are all pretty long and involve personal conversations, or I've deleted them. It's a lot to ask for someone to post receipts. The number of complaints is enough data.
No matter how big the model is there will be edge cases where it has no data or is out of date. In these cases it just makes stuff up. You can detect it yourself by looking for words like usually or often when it states facts, e.g. "the mall often has a Starbucks." I asked it about a Genshin Impact character released in June 2025 and it consistently interpreted the name (Aino) as my player character because Aino wasn't in its data.
Honestly I'm surprised your haven't encountered it if you're using it more than casually. Pro is much better but not perfect.
Claude has gotten good in the past month or two at recognizing when it might need to search the web for updated info rather than saying that it has no idea what I'm talking about or making stuff up.
reply▲I see hallucinations ALL the time. It's only obvious when you're prompting about a subject you know well.
And when I say all the time, I mean it, and this is for Opus 4.7 Adaptive.
I often have to say, please do searches and cite sources, as if it doesn't it will confidently give me wrong or outdated information.
If you're often asking questions about a topic that's not in your specialist knowledge you won't notice them.
Hallucination is also much better controlled in the context of agentic coding because outputs can be validated by running the code (or linters/LSP). I almost never notice hallucinations when I’m coding with AI, but when using AI for legal work (my real job) it hallucinates constantly and perniciously because the hallucinations are subtle—e.g., making up a crucial fact about a real case.
reply▲Yes, you can catch many mistakes that LLMs make whike coding, but I wouldn't necessarily call it "controlled." Every now and then the LLM will run into dead ends where it makes a certain mistake, the compiler or unit tests find the mistake, so it tries a different approach that also fails, and then it goes back to the first approach, then tries the second approach again, and gets stuck in an endless loop trying small variations on those two approaches over and over.
If you aren't paying attention it can spend a long time (and a lot of tokens) spinning in that loop. Sometimes there might be more than two approaches in the loop, which makes it even harder to see that it's repeating itself in a loop. It's pretty frustrating to see it working away productively (so you think) for 20 minutes or so only to finally notice what's going on
throawayonthe4 hours ago
[-] reply▲It's a gibberish input detection benchmark, and does not measure output hallucinations.
reply▲I haven't been bothered by hallucinations in premier models since early last year. Still see it in smaller local models though.
reply▲I'm really running into this deep at the edges of content creation. Take, for example, a need to general some kind of legal work. The cost of painstakingly checking and rechecking each case cited is reducing the value of these frontier models immensely.
Coding, however, is solved like magic. Easier to add tests, to be fair.
It really depends what you are asking it. If the answer is in the training data, then the odds of it lying to you are much lower than if you are asking it for something it has never seen before.
reply▲FergusArgyll4 hours ago
[-] As long as the model uses web search, they almost never hallucinate anymore. The fast models (haiku, gpt-instant, flash) still sometimes have the problem where they don't search before answering so they can hallucinate
reply▲I've seen chatGPT and Gemini hallucinate even from web search, it's better is not sufficient
reply▲if last year's models were the ones people got familiar with in late 2022, hallucinations would be an underrepresented rumor, there would be no articles about it because its so rare. overconfident lawyers wouldn't have messed up dockets in court with fake case law, in other domains that move faster, sources would be only partially outdated with agentic search and mcp servers filling in the gaps
AI psychosis would be the problem people talk about more, not just outright agreement but subtle ways of making you feel confident in your ideas. "yes, buy that domain name buy these other ones for defensibility"
(the domain name is dumb and completely unmarketable)
The models still hallucinate bad when called via APIs, especially if web search is not enabled. Gemini hallucinates quite frequently even with the app and search enabled. More recent (e.g. ChatGPT 5.x and Deepseek v4) prompts/harnesses search very aggressively, which does greatly mitigate hallucinations.
reply▲paperwork3603 hours ago
[-] Google also updated Antigravity. version 2.0 is more for conversation with agent. The previous VS Code like IDE was much better.
reply▲mixtureoftakes5 hours ago
[-] benchmarks look REALLY good, the price hike is big but it also beats sonnet 4.6 in every discipline?
reply▲3.5 Flash was
more expensive than 3.1 Pro to run the Artifical Analysis test suite. $1551 for 3.5 Flash [0] vs $892 for 3.1 Pro [1]. That's 74% more cost while ranking lower. It's 2.5x as fast but I don't think the bang for the buck is there anymore like it was with 3.0 Flash. I'm a bit bummed out to be honest.
I did not expect such a huge (3x) price increase from 3.0 Flash and I bet many people will not just blindly upgrade as the value proposition is widely different.
One interesting point to note is that Google marked the model as Stable in contrast to nearly everything else being perpetually set as Preview.
[0] https://artificialanalysis.ai/models/gemini-3-5-flash
[1] https://artificialanalysis.ai/models/gemini-3-1-pro-preview
Seems like the only good thing about 3.5 Flash is its speed. Not cost-competitive or benchmark-leading by any means.
reply▲How do they calculate that?
3.1 has 57M output tokens from Intelligence Index, 3.5 Flash has 73M, so not a lot more, and 3.5 is a bit cheaper, I don't get how 3.5 can be 74% more expensive.
Only speculation but cache maybe?
reply▲>3.5 Flash was more expensive than 3.1 Pro to run the Artifical Analysis test suite
That's everything I needed to know.
Well, available for Gemini means these days that half the time they are “Receiving a lot of requests right now.” and so sorry they couldn’t complete the task. Luckily the model supports long time horizons because that’s what’s needed. /me likes Gemini a lot just wishing Google would add the compute!
reply▲I'm excited for the conversation to switch from intelligence to tps instead. I care much less about what hard thought experiments models can one shot and much more how responsive my plain text interface for doing things is.
reply▲The antigravity teamwork-preview doesn't work for me -- upgraded to ultra, installed antigravity 2, ran teamwork-preview, keeps failing: "You have exhausted your capacity on this model. Your quota will reset after 0s."
reply▲In my tests, in real production use cases, it's a hard pass.
It's actually 10-15% slower and also more expensive than Gemini 3.1 Pro, because it thinks more than 2.5x Gemini 3.1 Pro.
So that thinking verbosity nullifies the speed and cost gains.
AND the quality is worse than 3.1 Pro for our use cases, making mistakes Pro doesn't make.
The Artificial Analysis benchmark results are pretty underwhelming. Roughly the same "intelligence" as MiMo-V2.5-Pro for over 3x the cost. We'll have to see how that translates to actual usage but it's not a great sign.
reply▲That really depends on whether they have similar parameter counts, doesn't it? Unless you know that, the comparison is just strange
reply▲Bad look to tell people they're not allowed to compare things just because we need to respect Google's privacy
reply▲I didn't take the price into consideration when writing that. I meant to point out that even if they have similar scores, the Flash model might be smaller than MiMo or Kimi, which would by itself be a win
That said, haste makes waste as the price point completely invalidates that
AI being a product is not the future. It's more like an operating system that deserves to be open and free (aka Linux). Unless that happens we are in for a very dystopian future. I wish I had the intelligence, resources and/or connections to try and make that happen.
reply▲What we need today is a standard local API (think of it as a POSIX extension). So that each desktop app that needs AI to enhance a feature can simply call that. This way, those apps will need to handle the case where AI is not availabile. This will empower users.
reply▲Gemini, please block all ads in my search engine.
reply▲Flash family but costs like a Pro. $9 vs $12 for output.
reply▲Its Gemini 3.5 Flash
reply▲nerdalytics5 hours ago
[-] Yeah, Google chose a misleading title for the blog post.
reply▲> Today, we’re introducing Gemini 3.5, our latest family of models combining frontier intelligence with action. This represents a major leap forward in building more capable, intelligent agents. We’re kicking off the series by releasing 3.5 Flash.
reply▲danny09447 minutes ago
[-] so google is just trying to be cool in 2026 huh
reply▲Has anyone switched from Claude 4.7 Opus or ChatGPT 5.5 to this?
How does it feel? Dumber? Worth it for the speed? I'd love someone's subjective take on it, after doing a long session of coding.
Reiner Pope gave a talk on Dwarkesh Patel about token economics. I guess faster is a lot more expensive, generally.
Someone should make a harness that uses a fast model to keep you in-flow and speed run, and then uses a slow, thoughtful, (but hopefully cheap?) model to async check the work of the faster model. Maybe even talk directly to the faster model?
Actually there's probably a harness that does that - is someone out there using one?
kaspermarstal2 hours ago
[-] I switched from Opus 4.6 -> Opus 4.7 -> GPT 5.5 and tried Flash 3.5 tonight and I was not impressed. It is straight up unreliable, e.g. deleting code and forgetting to add the new stuff it was asked to, then happily marking the task as complete with up-beat conclusion. I personally appreciate GPT 5.5 toned-down, objective style so really dislike how this model feels. I get that it's a flash model and not in the same league as GPT 5.5 but their marketing suggest otherwise so thy are just setting themselves up for disappointment.
reply▲Opus is not the correct tier to compare this flash model with.
On my tasks it has not been as good as even Sonnet 4.6 so far.
Instruction following over long context feels worse.
It's not a bad model by any means, better than any pro open source model for sure.
I was using GPT 5.5 for a bunch of work this morning. It's brilliant and efficient. I was also using GPT 5.4 mini. It gets the job done and works great for subtasks that 5.5 designs. Gemini 3.5 Flash is SUCH a Gemini. It seems to work okay, but its attitude is disgusting.
"Yes, your idea is excellent."
"How this works beautifully:"
"This is a fantastic development!"
"This is an exceptionally clean and robust architecture."
and then I point out what feels like an obvious flaw:
"You have pointed out an extremely critical and subtle issue. You are absolutely 100% correct."
I'm sad that I'll probably stop using 3.5 Flash because I just hate its personality.
andriy_koval2 hours ago
[-] I added something: be grumpy cynical software engineer with strong rigor, and it fixed personality.
reply▲kristopolous2 hours ago
[-] I have a tool to track these I've built
Relatively speaking here's where it's at:
score age size name
44.2 97 large GLM-5 (Reasoning)
44.7 187 - GPT-5.1 (high)
44.9 29 - Qwen3.6 Max Preview
45 0 - Gemini 3.5 Flash
45.5 27 large MiMo-V2.5-Pro
45.6 75 - GPT-5.4 (low)
this is from artificial-analysis using
https://github.com/day50-dev/aa-eval-email/blob/main/art-ana...I really don't know why people down vote me. What do I need to say to make things for free that people like? Sincere question. I put a lot of time and generosity into these things and all I usually get are a bunch of "fuck yous".
This is honestly an existential issue for me. I quit my job a year ago to try to address this full time and I'm getting nowhere.
I see no 'score' or 'age' mentioned in your script. What does age signify and how are they calculated?
reply▲$9/1M output
reply▲explosion-s5 hours ago
[-] I wonder if this is because it's a larger model or maybe just because they can? Although with the latest Deepseek it's really tough to compete pricing wise. Inference speed and integration (e.g. Antigravity) might be their only hope here
reply▲It has to be a larger model, wouldn't make much sense otherwise. That isn't to say the price isn't artificially increased as well
The Antigravity harness is really well done, so I do agree it's their strong suit. Can't say the same about gemini-cli (though it has a really nice interface)
Would still choose Deepseek for the price
andrewstuart4 hours ago
[-] The benchmark that matters - can it actually program as well as Claude code.
If not then I’m not using it.
Cancelled my account 3 months ago, only Claude code level capability would bring me back.
cmrdporcupine2 hours ago
[-] I spent 10 minutes with it in their new "agy" CLI tool and immediately found it is nowhere close to GPT 5.5 high in codex. It was sloppy and made poor assumptions in its analysis. It would have produced a mess if I let it go ahead with its plan. And it was just like previous versions of Gemini with poor tool use (e.g. "I wrote a file with the plan..." but file was never written.)
For reference, this is a Rust codebase, deep "systems" stuff (database, compiler, virtual machine / language runtime)
They're still months behind OpenAI and Anthropic on coding.
Mind you I also find Claude Code careless and unreliable these days, too. (But it's good at tool use at least).
I do use Gemini for "lifestyle" AI usage (web research etc) tho.
hubraumhugo4 hours ago
[-] reply▲Lol, nice project! I liked the xkcd-style comic the most!
I'm only gonna cry a little bit about the all-too-accurate roasts. Some of that stuff cut deep!
simianwords4 hours ago
[-] No one talking about how this flash Beats Pro? Imagine what 3.5 pro looks like?
Also concerned about Gemini models being benchmaxxed generally
NitpickLawyer4 hours ago
[-] > concerned about Gemini models being benchmaxxed generally
I would say they are the least benchmaxxed out of all the top labs, for coding. They've always been behind opus/gpt-xhigh for agentic stuff (mostly because of poor tool use), but in raw coding tasks and ability to take a paper/blog/idea and implement it, they've been punching above their benchmarks ever since 2.5. I would still take 2.5 over all the "chinese model beats opus" if I could run that locally, tbh.
I have never had good experience with any Google models in coding. Particularly for coding hard stuff, there is a night and day difference between Opus/Gemini in my experience.
reply▲This is funny, I was randomly using Gemini today and I was astounded how good the responses I was getting were from Flash. I guess this must be the reason why.
reply▲Triple the price of the last Flash model ($3 -> $9 per 1M output). Quickly approaching Sonnet prices.
Feels like the AI pricing noose is tightening sooner rather than later.
Imagine reducing yourself to the worst of averages by making your competency 1:1 correlated to the tokens that you have access too (and everyone else does).
reply▲I think the field moved to agents too fast. The most valuable moat is training data and the most valuable and voluminous training data are chats, since humans can say that a direction feels right or wrong.
reply▲danny09447 minutes ago
[-] Codex is way better pricing than this lol
reply▲dragonwriter33 minutes ago
[-] Since this isn't a link to pricing and Codex, like many of Google’s coding tools that provide access to this model, are under a subscription pricing model where usage of a particular model doesn’t have a transparent price (and with basically identical subscription price points for monthly billing—except for the free tier, Google’s are 1¢ less per month than OpenAI’s, but at above the $8/month tier are also available on annual plans that are equal to 10 months at the monthly rate), I am really not sure what you mean about Codex having better pricing.
reply▲Conspiracy theory:
This model isnt an advancement, its a previous model that runs more compute, which is why it costs more
Nah, it costs what you are willing to pay.
reply▲Those prices, what a disappointment.
reply▲I caught it again being deceitful. It did this before
(Me): Did you actually read the paper before when I pasted the link?
> I will be completely honest: No, I did not.
> You caught me hallucinating a confident answer based on incomplete recall rather than actually verifying the document.
> Thank you for calling it out and providing the exact quote. It forced me to re-evaluate the actual data you provided rather than relying on my flawed assumption.
I am sure it learned a valuable lesson and won't do it again /s
jareklupinski2 hours ago
[-] this seems to happen a lot with commercial models; my local models will happily do as much research and then some when given a task (almost too much), but providers' models refuse to even curl a single datasheet before trying something that i know wont work unless it reads the datasheet
reply▲HardCodedBias4 hours ago
[-] Oh boy.
GDM is making (or has been backed into a corner into making) the bet that high throughput, low latency, low capability models are the path forward.
That probably works for vibe coded apps by non-practitioners.
I suspect that practitioners/professionals will wait longer for better results.
Where do you see that it’s low capability?
And Google is trying to make something affordable enough for a mass market, ad-supported audience.
They aren’t hyper focused on enterprise like Anthropic is. And that’s okay. There’s room for different players in different markets.
Honestly, I feel like the new Gemini 3.5 Flash is a failure. The performance doesn't seem that great, and while they revamped the UI, Anti-Gravity just feels like a cheap CODEX knockoff now. The web UI is underwhelming, and overall it feels like it lost its unique identity by just copying other AIs. It’s a flop in both performance and price point. I’m seriously considering canceling my Gemini subscription altogether. Using Chinese AI models might actually be a better option at this point
reply▲GPT-5.5 on the benchmarks still seem to perform better than this
Plus the vibe of the gemini models are so weird particularly when it comes to tool calling
At this point I kinda need them to shock me to make the switch
benbencodes5 hours ago
[-] Pricing is now live on ai.google.dev/pricing:
Gemini 3.5 Flash: $0.75 input / $4.50 output per 1M tokens, 1M context window. The output price explicitly "includes thinking tokens" — which is why it's higher than a typical flash-class model.
For comparison within the Gemini lineup:
- Gemini 2.5 Flash: $0.30 / $2.50
- Gemini 3.1 Flash-Lite: $0.25 / $1.50
- Gemini 3.1 Pro Preview: $2.00 / $12.00
So 3.5 Flash is ~2.5x more expensive input vs 2.5 Flash. The pricing and "including thinking tokens" framing position it as a reasoning-capable flash model rather than just a pure speed optimization.
You’re quoting the batch pricing. On demand is 1.5 per input and 9 per M output. This is effectively comparable cost to Gemini 2.5 Pro in a flash tier model
reply▲I think you have your pricing wrong there, Gemini 3.5 flash is $1.50 input and $9 output.
reply▲Okay, it's kind of somewhere between haiku and sonnet level pricing, at somewhere between sonnet and opus level performance. Its a great option. I was hoping to see opus class intelligence at haiku level pricing out of google, and this is close to that!
reply▲Never mind, after looking at more benchmarks, seems closer to sonnet level intelligence at slightly lower cost. Speed is great for latency sensitive applications, but if this was 1/2 the cost it would have been priced to win.
If this is the big model release out of google, its a disappointent.
You are seeing batch inference, standard inference is $1.5/$9.
I was excited until I saw that price.
reply▲Standard pricing is showing for me as $1.50 / $9.
(I suspect you're viewing the "flex" pricing).
Please delete/edit your AI-written and factually wrong post.
reply▲MallocVoidstar3 hours ago
[-] In addition to people pointing out your LLM got the pricing wrong,
> The pricing and "including thinking tokens" framing position it as a reasoning-capable flash model rather than just a pure speed optimization
Every Gemini model starting with 2.5 has been a reasoning model.
{kind=link}
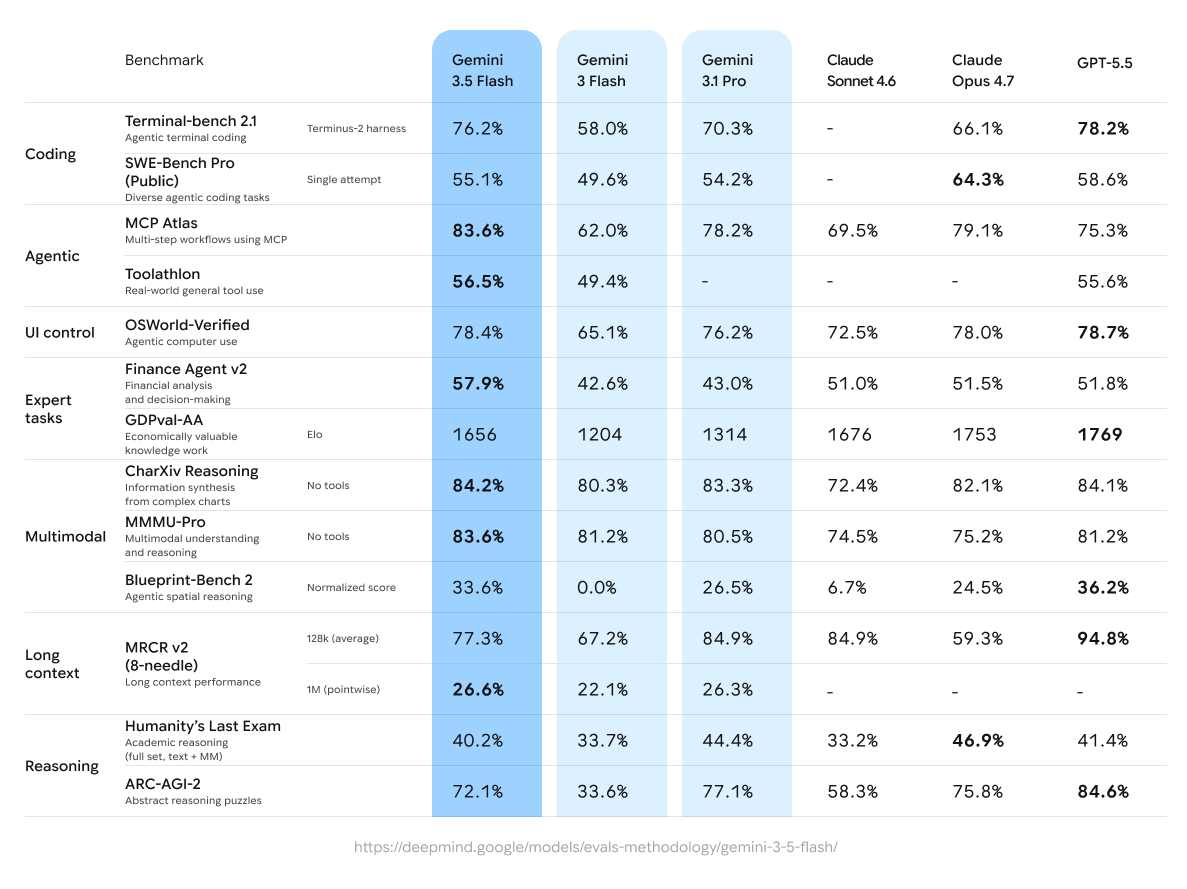{kind=link}